1. 论文简介
论文名:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文地址 :Faster R-CNN
论文作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun
论文时间:2016年(论文发表)
说明:在GPU上推理速度达到5fps(包含候选区域生成的时间),准确率也有进一步的提升。
2. Faster R-CNN算法流程
简单来说就是:RPN+ Fast R-CNN,也就是用RPN网络来生成候选框,而不是使用SS算法来生成候选框。

(1)将图片输入到backbone网络中,从而获得特征图
(2)使用RPN网络生成后候选框,再将候选框投影到特征图上从而获得对应的特征矩阵
(3)将每个特征矩阵通过ROI Pooling层缩放到7x7大小的特征图,再将特征图展平,通过多个全连接层获得最终的预测结果

3. RPN网络结构

上图为论文中给出的RPN网络。
注意:图中:256-d是使用ZF网络(Zeiler and Fergus model)得到的特征图的channel数量,如果使用VGG16网络,则channel数量是512。论文中,作者提到使用了这两种网络。
FPN网络的作用:1.生成proposal(经过一定的修正);2.初步判定proposal中是前景还是背景。
论文中提到,RPN网络采用了n x n的滑动窗口(即在特征图上使用n x n的窗口进行滑动作为输入,论文中n=3),然后接两个全连接层,其中一个称为box-regression layer(reg),另一个称为box-classification layer(cls)。
实际在执行的时候,在得到feature map之后,接一个3x3的卷积层,之后再接两个1x1的卷积层,其中一个用于回归,针对每个anchor box输出4个边界框回归参数(所以图上是4k),另一个用于分类,针对每个每个anchor box输出2个概率值(所以图上是2k),分别为前景的概率和背景的概率。
例如,以VGG16为例,得到的特征图为HxWx512,经过3x3卷积之后(滑动窗口),得到HxWx512的特征图,一个分支经过最终用于分类的1x1卷积层后,得到HxWx18的特征图;另一个分支经过最终用于回归的1x1卷积层后,得到HxWx36的特征图;这两个特征图后续还会做reshape等等。

所以RPN网络参数量(以VGG16为例):
1个3x3卷积层:3x3x512(channel)x512(number of filters)
2个1x1卷积层:1x1x512(channel)x(4+2)x9(anchors)
上面两个相加:

4. Anchors
Faster R-CNN中,作者采用anchor-based的方法(pyramid of anchors),使得训练可以end to end,推理速度更快,也能够检测不同尺寸的目标。
anchor box其实就是原图上的一个一个的矩形框。具体生成方式如下:
对于特征图上的每个3x3的滑动窗口,找到滑动窗口的中心点,然后计算出该中心点对应到原始图像上的位置点,最后基于原始图像上的这个点绘制k(论文中为9)个anchor box。
也就是说,通过backbone网络,我们会得到特征图,由此也会知道整个backbone网络的stride,也就是下采样倍率,那么就可以根据这个stride将特征图上的某一个点映射回到原图上,然后在当前点根据anchor box的尺度和比例得到anchor box。
例如,假设当前滑动窗口的中心点是(2,2),特征图尺寸为HxW,原图尺寸为H'xW',我们可以计算H'/H以及W'/W(取整处理),那么(2x(H'/H) , 2xW'/W)就是在原图上的对应的点。
anchor的尺度和比例():
三种尺度scale: ,
, ,
,
三种比例ratio:1:1,1:2,2:1
如下图所示,中间蓝色的anchor的面积为,蓝色正方形表示该anchor的高和宽的比例为1:1,横向的蓝色长方形表示该anchor的高和宽的比例为1:2,纵向的蓝色长方形表示该anchor的高和宽的比例为2:1。红色和绿色的框类似。

所以,对于特征图上的每个点,都会在原图上生成9个anchor。对于RPN网络来说,每个anchor都会输出2个代表前景和背景的概率值以及4个边界框回归参数,也就是RPN网络图上的2k和4k。
具体的,当k=9:
2k=18: ,其中f表示前景,b表示背景
,其中f表示前景,b表示背景
4k=36:
对于一张1000x600的图像,大约会有20000(≈60 x 40 x 9)个anchor,忽略掉跨边界的anchor后,会剩下大概6000个anchor用于训练。
作者在论文中有说,尽管backbone得到的特征图的感受野小于anchor的大小(ZF网络感受野:171,VG,16感受野:228),但仍然可以进行预测,因为我们可以通过物体的局部信息来推测某个目标。


5.训练数据
训练RPN网络时
每个mini-batch从一张图片上采样。每个mini-batch包含256个anchor,其中正负样本比例1:1,如果正样本数量不够128,那么使用负样本进行填充。
正样本的定义:
(1)和GT具有最大的IoU
(2)和任何一个GT的IoU大于0.7
实际上,方法(1)可以说是方法(2)的补偿,作者说,通常情况下,方法(2)就能找到足够的正样本,但极少数情况下,使用方法(2)可能找不到正样本(也就是所有的anchor和GT的IoU都小于等于0.7),所以仍然会使用方法(1)。
负样本的定义:
和所有GT的IoU小于0.3
既不是正样本也不是负样本的anchor都被舍弃。


训练Fast R-CNN时
RPN训练之后会通过回归参数调整候选框位置和大小,调整之后的称为region proposal(候选框)。
RPN生成的proposal之间存在大量重叠,可以基于cls score的值采用NMS方法来去除一些proposal,IoU阈值设置为0.7,最后每张图片剩下将近2000个候选框。

6. RPN损失函数
原论文中给出如下式子

其中
i:表示mini-batch中的第i个anchor
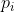 :表示第i个anchor是目标(前景)的概率
:表示第i个anchor是目标(前景)的概率
 :当anchor为正样本时为1,为负样本时为0
:当anchor为正样本时为1,为负样本时为0
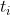 :表示第i个bounding box的边界框回归参数
:表示第i个bounding box的边界框回归参数
 :表示第i个正样本对应的GT Box
:表示第i个正样本对应的GT Box
 :表示一个mini-batch中的样本数,值为256
:表示一个mini-batch中的样本数,值为256
 :表示anchor位置的数量(对于一张1000x600的图像,大约会有2400(≈60 x 40)个位置)
:表示anchor位置的数量(对于一张1000x600的图像,大约会有2400(≈60 x 40)个位置)
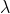 :平衡系数,论文中取值为10
:平衡系数,论文中取值为10
RPN损失函数由分类损失和回归损失两部分组成。
分类损失:

举个例子:
最终得到的2k个类别score为:(0.1,0.9,0.3,0.7,...,0.8,0.2),每2个为一组,对应真实标签为:1,0,...,1。
那么
作者提到,为了简便起见,采用了2个类别的softmax。
当然,我们也可以用sigmoid,也就是binary cross entropy,也就是

这个时候需要注意,分类输出的应该是k个值。

回归损失:
和Fast R-CNN是一样的原理,都是使用smooth 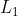 损失函数。
损失函数。




 分别属于predicted box,anchor box,ground-truth box。
分别属于predicted box,anchor box,ground-truth box。
7. Fast R-CNN损失函数
参考:Fast R-CNN
8. Faster R-CNN训练过程
现在:联合训练,Total Loss = RPN Loss+Faster R-CNN,反向传播。(pytorch官方示例)
原论文:
(1)利用ImageNet预训练模型初始化backbone,然后单独训练RPN网络;
(2)固定RPN网络参数,利用ImageNet预训练模型初始化backbone,利用RPN网络生成的proposal训练Fast R-CNN;
(3)固定Fast R-CNN训练好的backbone参数,微调RPN网络;
(4)固定backbone,微调Fast R-CNN全连接层参数;
(5)最后,RPN和Fast R-CNN共享backbone参数。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)