前言
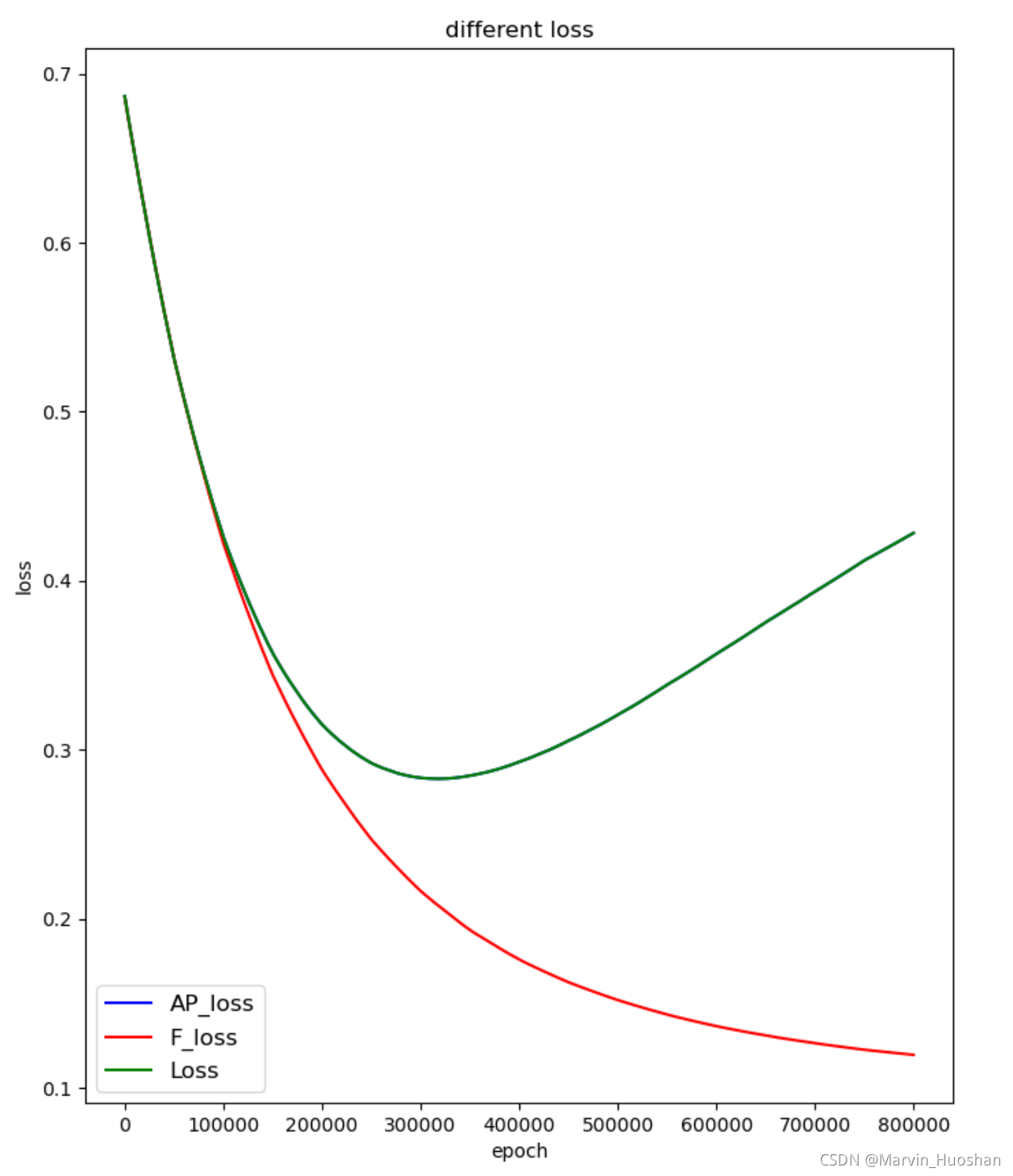
最近在写一篇文章,是一篇深度学习与安全相结合的文章,模型的输出会交给两个损失函数(availability & security)进行损失计算,进而反向传播。起初的想法是直接将两项损失进行加权平均,共同进行反向传播,后面又尝试了先A后B和先B后A的方式。发现模型训练的效果不是很好,因为这两个损失在进行下降时是一种相互制约的关系,如图1所示(侧面也反映了自己设计的连个损失方向是对的)。在epoch到达30w次之后,两者分道扬镳。
考虑到多任务之间的制约,尝试使用多目标优化的方法对两个损失函数进行优化,以获得使两种损失同时较小的一种嵌入,然后再将此满足条件的嵌入作为模型的训练目标,分步完成模型的训练。但是在研究了多目标优化的算法之后,打消了这个念头,因为我模型的输出维度很高,他是一张图的邻接矩阵的一维展开(adj.view(-1)),是百万维级别的,所以使用传统多目标优化的方法(例如遗传算法)过于复杂,所以就发现了这一篇名为Multi-Task Learning as Multi-Objective Optimization的文章。下面简单的介绍一下这篇文章。
Multi-Task Learning as Multi-Objective Optimization
作者在文章的摘要中说:“多任务学习本质上是一个多目标的问题,因为不同的任务可能会发生冲突,需要进行权衡。一个常见的折衷办法是优化一个代理目标,使每个任务损失的加权线性组合最小。然而,这种变通方法只有在任务不竞争的情况下才有效,而这种情况很少发生。在本文中,我们明确地将多任务学习作为多目标优化,其总体目标是找到一个帕累托最优解。”
这个是文章为何能够适用于我的问题的原因。细节不做过多介绍,在阅读过程中发现网上有不少对于这篇文章原理的解释,大家有疑问可以自行查看。
对Multi-Task Learning as Multi-Objective Optimization方法进行尝试
Solving the Optimization Problem

这是文章中的一段话。在处理一般情况之前,先处理只有两个优化目标的一般情况。此时的优化目标是一个一元二次函数: ![min_{\alpha\in[0,1]}||\alpha\bigtriangledown_{\theta^{sh}}\hat{\mathcal{L}}^1+(1-\alpha)\bigtriangledown_{\theta^{sh}}\hat{\mathcal{L}}^2||^2_2](https://latex.codecogs.com/gif.latex?min_%7B%5Calpha%5Cin%5B0%2C1%5D%7D%7C%7C%5Calpha%5Cbigtriangledown_%7B%5Ctheta%5E%7Bsh%7D%7D%5Chat%7B%5Cmathcal%7BL%7D%7D%5E1+%281-%5Calpha%29%5Cbigtriangledown_%7B%5Ctheta%5E%7Bsh%7D%7D%5Chat%7B%5Cmathcal%7BL%7D%7D%5E2%7C%7C%5E2_2) ,其解为:
,其解为:
![\alpha = \left [ \frac{(\bigtriangledown_{\theta^{sh}}\hat{L}^2-\bigtriangledown_{\theta^{sh}}\hat{L}^1)^T\bigtriangledown_{\theta^{sh}}\hat{L}^2}{||\bigtriangledown_{\theta^{sh}}\hat{L}^1-\bigtriangledown_{\theta^{sh}}\hat{L}^2||_2^2} \right ]_+](https://latex.codecogs.com/gif.latex?%5Calpha%20%3D%20%5Cleft%20%5B%20%5Cfrac%7B%28%5Cbigtriangledown_%7B%5Ctheta%5E%7Bsh%7D%7D%5Chat%7BL%7D%5E2-%5Cbigtriangledown_%7B%5Ctheta%5E%7Bsh%7D%7D%5Chat%7BL%7D%5E1%29%5ET%5Cbigtriangledown_%7B%5Ctheta%5E%7Bsh%7D%7D%5Chat%7BL%7D%5E2%7D%7B%7C%7C%5Cbigtriangledown_%7B%5Ctheta%5E%7Bsh%7D%7D%5Chat%7BL%7D%5E1-%5Cbigtriangledown_%7B%5Ctheta%5E%7Bsh%7D%7D%5Chat%7BL%7D%5E2%7C%7C_2%5E2%7D%20%5Cright%20%5D_+)
同时,作者又介绍道,对于每一个任务t,都需要计算 ,而参数
,而参数 在反向传播阶段恰好是多任务共享的参数,所以在反向传播阶段需要计算T次。因此作者为了降低计算复杂度,确定了优化问题的上界。
在反向传播阶段恰好是多任务共享的参数,所以在反向传播阶段需要计算T次。因此作者为了降低计算复杂度,确定了优化问题的上界。
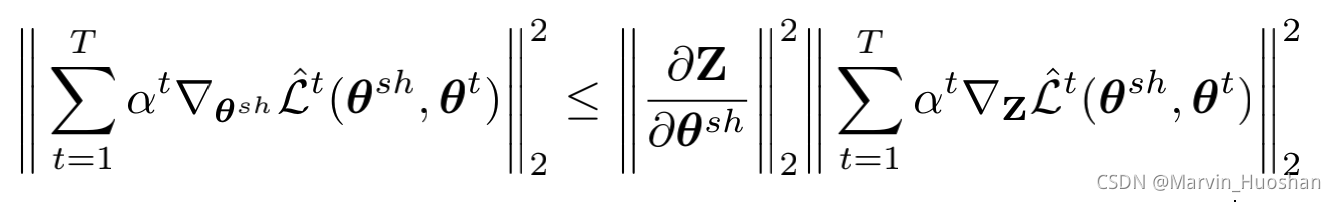
其中Z为表示层的输出,也就是共享参数的各层最后的输出。 
又因为 与
与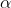 无关,所以在优化中会被移除。因此使用以下上界来优化目标。
无关,所以在优化中会被移除。因此使用以下上界来优化目标。
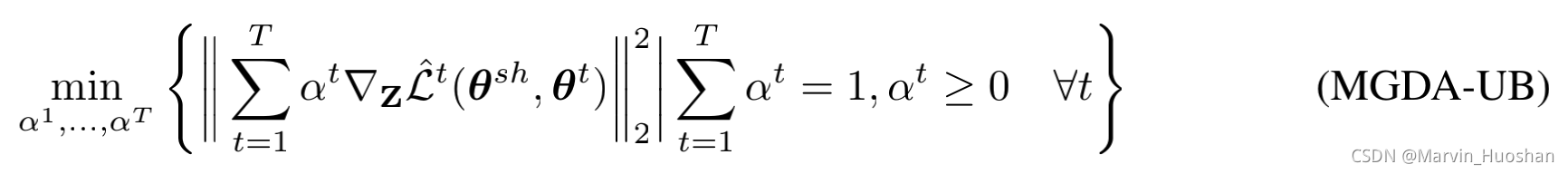
应用
根据以上分析,我对自己的模型进行了改进,先分享一下源代码:
grads = {}
#这个函数是为了获取中间变量的梯度,我方案中的Z不是一个叶子结点,所以其梯度在反向传播之后不会被保存
def save_grad(name):
def hook(grad):
grads[name] = grad
return hook
def MTL(loss, Floss):
'''
使用多任务学习的多个梯度来决定最终梯度
:param loss: 损失1
:param Floss: 损失2
:return:
'''
Z.register_hook(save_grad('Z'))
#对loss进行反向传播,获取各层的梯度
loss.backward(retain_graph = True)
theta1 = grads['Z'].view(-1)
#将计算图中的梯度清零,准备对第二种loss进行反向传播
optimizer.zero_grad(retain_graph = True)
Floss.backward()
theta2 = grads['Z'].view(-1)
#alpha解的分子部分
part1 = torch.mm((theta2 - theta1), theta2.T)
#alpha解的分母部分
part2 = torch.norm(theta1 - theta2, p = 2)
#二范数的平方
part2.pow(2)
alpha = torch.div(part1, part2)
min = torch.ones_like(alpha)
alpha = torch.where(alpha > 1, min, alpha)
min = torch.zeros_like(alpha)
alpha = torch.where(alpha < 0, min, alpha)
#alpha theta1 & (1 - alpha) theta2
#将alpha等维度拓展
alpha1 = alpha
alpha2 = (1 - alpha)
#将各层梯度清零
optimizer.zero_grad()
#根据比率alpha1 & alpha2分配Loss1和Loss2的比率
MTLoss = alpha1 * loss + alpha2 * Floss
MTLoss.backward()
在我自己的方案中,其实也是进行了三次反向传播,其实可以只计算出表示层的输出Z的梯度,然后根据梯度计算alpha,直接将两种Loss分配权重,但是这里的操作我并没有实现,因为每次backward()之后,其实是进行了一次完整的反向传播,如果不进行backward()又没有办法快速求出Z的梯度。所以我还没研究清楚如何进行控制,如果大家有解决的方法,也希望能够不吝赐教。
在这里我为何还要使用Z而不是表示层的梯度,是因为我的表示层的权重矩阵是一个多维的变换矩阵,所以在进行帕累托最优求解的时候比较麻烦,而表示层的输出Z,是一个一维的向量,进行帕累托最优解寻找的过程比较简单,方便计算。当然这也只是我在阅读完文献后的第一次尝试,可能在理解上还有很多错误,后面会不断进行改进。
结果
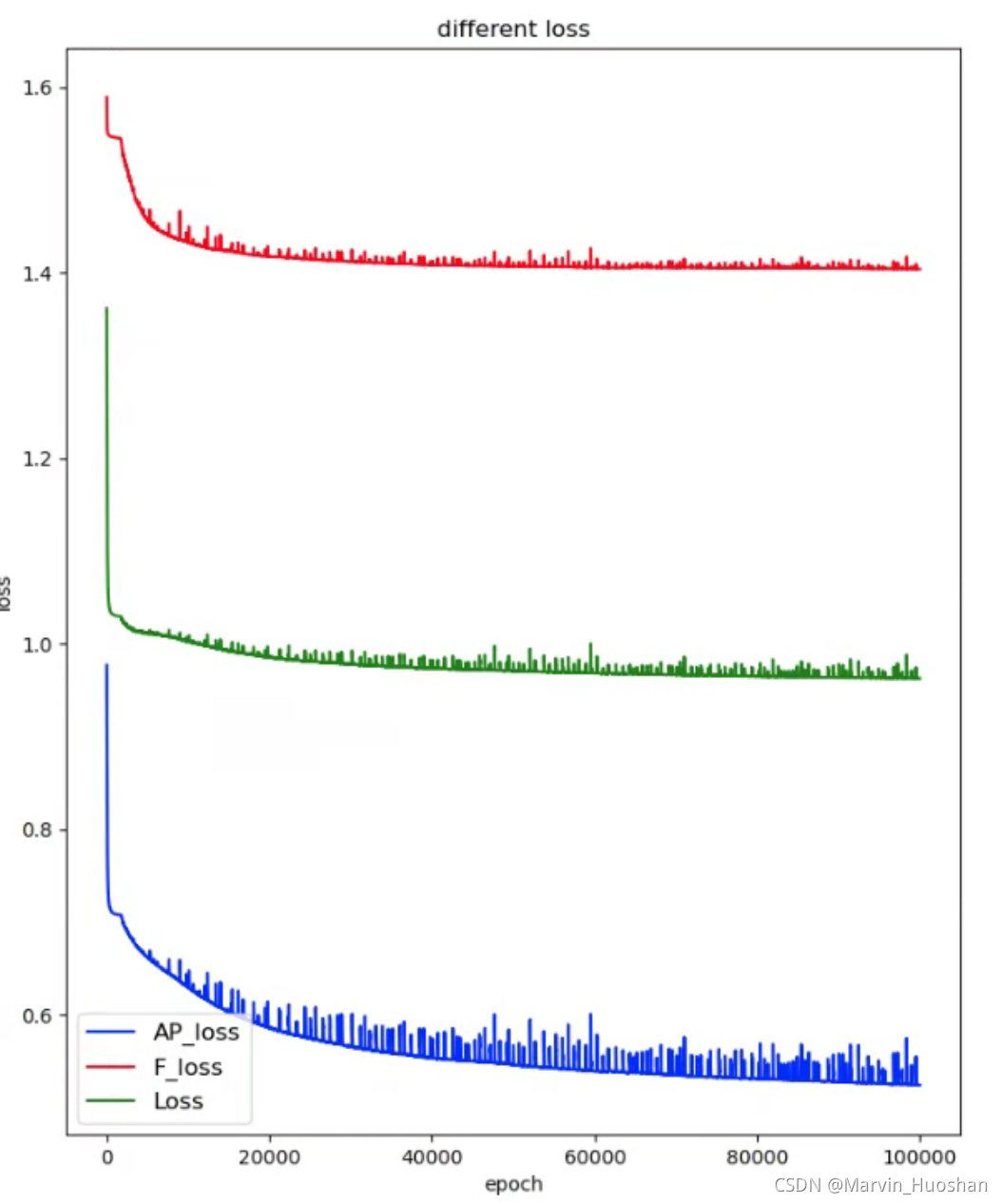
这个是使用文章中方法改进之后的梯度下降损失的变化,其中AP_loss是Loss1,F_loss是Loss2,可以看出两者都在进行下降,同时与我之前使用的手动调参(Loss1 & Loss2全程按照一种比例进行梯度下降)相比,损失函数的震荡情况获得了十分明显的改善。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)