1. OpenStack是什么
OpenStack官方的解释很官方,而且从不同角度,也有不同的理解,OpenStack可以理解为一个云操作系统
OpenStack旗下包含了一组由社区维护的开源项目,他们分别是OpenStackCompute(Nova),OpenStackObjectStorage(Swift),以及OpenStackImageService(Glance)。
OpenStackCompute[1],为云组织的控制器,它提供一个工具来部署云,包括运行实例、管理网络以及控制用户和其他项目对云的访问(thecloudthroughusersandprojects)。它底层的开源项目名称是Nova,其提供的软件能控制IaaS云计算平台,类似于AmazonEC2和RackspaceCloudServers。实际上它定义的是,与运行在主机操作系统上潜在的虚拟化机制交互的驱动,暴露基于WebAPI的功能。
OpenStackObjectStorage[2],是一个可扩展的对象存储系统。对象存储支持多种应用,比如复制和存档数据,图像或视频服务,存储次级静态数据,开发数据存储整合的新应用,存储容量难以估计的数据,为Web应用创建基于云的弹性存储。
OpenStackImageService[1],是一个虚拟机镜像的存储、查询和检索系统,服务包括的RESTfulAPI允许用户通过HTTP请求查询VM镜像元数据,以及检索实际的镜像。VM镜像有四种配置方式:简单的文件系统,类似OpenStackObjectStorage的对象存储系统,直接用Amazon'sSimpleStorageSolution(S3)存储,用带有ObjectStore的S3间接访问S3。
三个项目的基本关系如下图1-1所示:
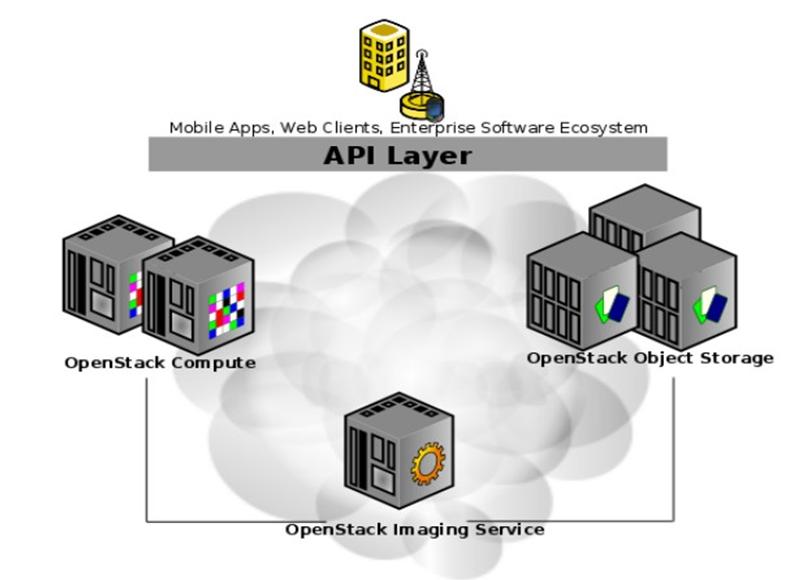
1-1 OpenStack三个组件的关系
2. 云服务提供商的概念架构
OpenStack能帮我们建立自己的IaaS,提供类似AmazonWebService的服务给客户。为实现这一点,我们需要提供几个高级特性:
a)允许应用拥有者注册云服务,查看运用和计费情况;
b)允许Developers/DevOpsfolks创建和存储他们应用的自定义镜像;
c)允许他们启动、监控和终止实例;
d)允许CloudOperator配置和操作基础架构
这四点都直击提供IaaS的核心,现在假设你同意了这四个特性,现在就可以将它们放进如下所示的概念架构2-1中。
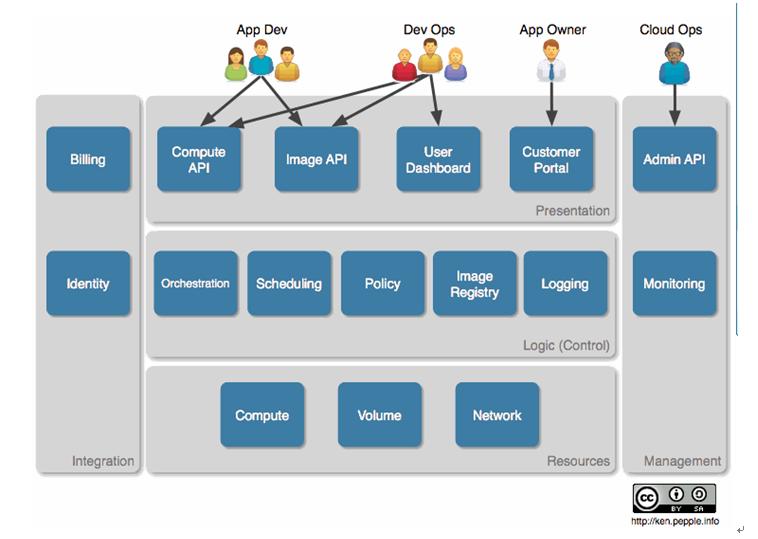
2-1 OpenStack 概念架构
在此模型中,作者假设了需要与云交互的四个用户集:developers,devops,ownersandoperators,并为每类用户划分了他们所需要的功能。该架构采用的是非常普通的分层方法(presentation,logicandresources),它带有两个正交区域。
展示层,组件与用户交互,接受和呈现信息。Webportals为非开发者提供图形界面,为开发者提供API端点。如果是更复杂的结构,负载均衡,控制代理,安全和名称服务也都会在这层。
逻辑层为云提供逻辑(intelligence)和控制功能。这层包括部署(复杂任务的工作流),调度(作业到资源的映射),策略(配额等等),镜像注册imageregistry(实例镜像的元数据),日志(事件和计量)。
假设绝大多数服务提供者已经有客户身份和计费系统。任何云架构都需要整合这些系统。
在任何复杂的环境下,我们都将需要一个management层来操作这个环境。它应该包括一个API访问云管理特性以及一些监控形式(forms)。很可能,监控功能将以整合的形式加入一个已存在的工具中。当前的架构中已经为我们虚拟的服务提供商加入了monitoring和adminAPI,在更完全的架构中,你将见到一系列的支持功能,比如provisioning和configurationmanagement。
最后,资源层。既然这是一个compute云,我们就需要实际的compute、network和storage资源,以供应给我们的客户。该层提供这些服务,无论他们是服务器,网络交换机,NAS(networkattachedstorage)还是其他的一些资源。
3. OpenStack Compute架构
3.1 OpenStack Compute逻辑架构
OpenStack Compute逻辑架构中,组件中的绝大多数可分为两种自定义编写的Python守护进程(custom written python daemons)。
a) 接收和协调API调用的WSGI应用(nova-api, glance-api, etc)
b) 执行部署任务的Worker守护进程(nova-compute, nova-network, nova-schedule, etc.)
然而,逻辑架构中有两个重要的部分,既不是自定义编写,也不是基于Python,它们是消息队列和数据库。二者简化了复杂任务(通过消息传递和信息共享的任务)的异步部署。
逻辑架构图3-1如下所示:
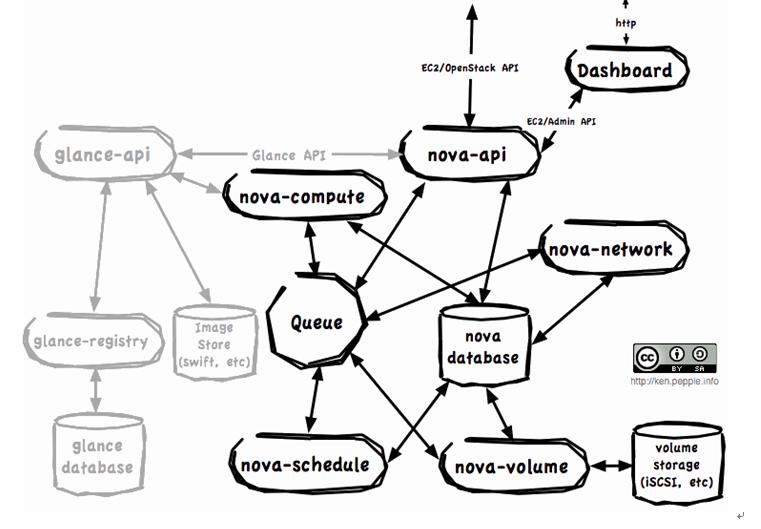
3-1 OpenStack Compute逻辑架构
从图中,我们可以总结出三点:
a) 终端用户(DevOps, Developers 和其他的 OpenStack 组件)通过和nova-api对话来与OpenStack Compute交互。
b) OpenStack Compute守护进程之间通过队列(行为)和数据库(信息)来交换信息,以执行API请求。
c) OpenStack Glance基本上是独立的基础架构,OpenStack Compute通过Glance API来和它交互。
其各个组件的情况如下:
a) nova-api守护进程是OpenStack Compute的中心。它为所有API查询(OpenStack API 或 EC2 API)提供端点,初始化绝大多数部署活动(比如运行实例),以及实施一些策略(绝大多数的配额检查)。
b) nova-compute进程主要是一个创建和终止虚拟机实例的Worker守护进程。其过程相当复杂,但是基本原理很简单:从队列中接收行为,然后在更新数据库的状态时,执行一系列的系统命令执行他们。
c) nova-volume管理映射到计算机实例的卷的创建、附加和取消。这些卷可以来自很多提供商,比如,ISCSI和AoE。
d) Nova-network worker守护进程类似于nova-compute和nova-volume。它从队列中接收网络任务,然后执行任务以操控网络,比如创建bridging interfaces或改变iptables rules。
e) Queue提供中心hub,为守护进程传递消息。当前用RabbitMQ实现。但是理论上能是python ampqlib支持的任何AMPQ消息队列。
f) SQL database存储云基础架构中的绝大多数编译时和运行时状态。这包括了可用的实例类型,在用的实例,可用的网络和项目。理论上,OpenStack Compute能支持SQL-Alchemy支持的任何数据库,但是当前广泛使用的数据库是sqlite3(仅适合测试和开发工作),MySQL和PostgreSQL。
g) OpenStack Glance,是一个单独的项目,它是一个compute架构中可选的部分,分为三个部分:glance-api, glance-registry and the image store. 其中,glance-api接受API调用,glance-registry负责存储和检索镜像的元数据,实际的Image Blob存储在Image Store中。Image Store可以是多种不同的Object Store,包括OpenStack Object Storage (Swift)
h) 最后,user dashboard是另一个可选的项目。OpenStack Dashboard提供了一个OpenStack Compute界面来给应用开发者和devops staff类似API的功能。当前它是作为Django web Application来实现的。当然,也有其他可用的Web前端。
3.2 概念映射
将逻辑架构映射到概念架构中(如3-2所示),可以看见我们还缺少什么。
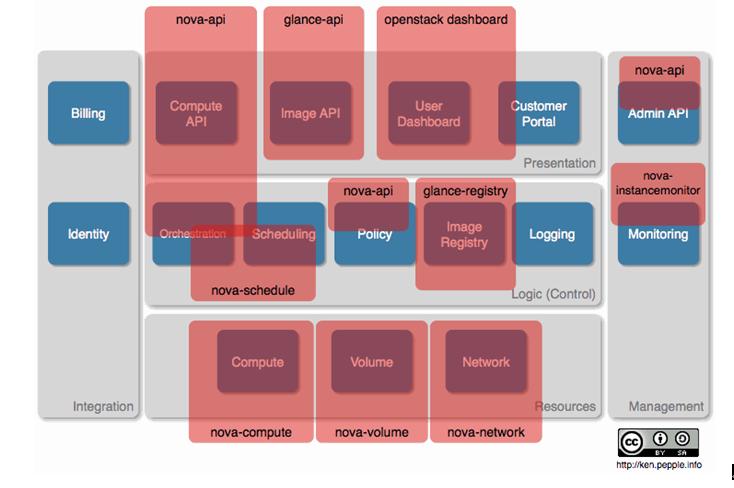
3-2 逻辑架构到概念架构的映射
这种覆盖方式并不是唯一的,这里的只是作者的理解。通过覆盖OpenStack Compute 逻辑组件,Glance和Dashboard,来表示功能范围。对于每一个覆盖,都有相应的提供该功能的逻辑组件的名称。
a) 在这种覆盖范围中,最大的差距是logging和billing。此刻,OpenStack Compute没有能协调logging事件、记录日志以及创建/呈现bills的Billing组件。真正的焦点是logging和Billing的整合。这能通过以下方式来补救。比如代码扩充,商业产品或者服务或者自定义日志解析的整合。
b) Identity也是未来可能要补充的一点。
c) customer portal也是一个整合点。user dashboard(见运行的实例,启动新的实例)没有提供一个界面,来允许应用拥有者签署服务,跟踪它们的费用以及声明有问题的票据(lodge trouble tickets)。而且,这很可能对我们设想的服务提供商来说是合适的。
d) 理想的情况是,Admin API会复制我们能通过命令行接口做的所有功能。在带有Admin API work的Diablo 发布中会更好。
e) 云监控和操作将是服务提供商关注的重点。好操作方法的关键是好的工具。当前,OpenStack Compute 提供 nova-instancemonitor,它跟踪计算结点使用情况。未来我们还需要三方工具来监控。
f) Policy是极其重要的方面,但是会与供应商很相关。从quotas到QoS,到隐私控制都在其管辖内。当前图上有部分覆盖,但是这取决于供应商的复杂需求。为准确起见,OpenStack Compute 为实例,浮点IP地址以及元数据提供配额。
g) 当前,OpenStack Compute内的Scheduling对于大的安装来说是相当初步的。调度器是以插件的方式设计的,目前支持chance(随机主机分配),simple(最少负载)和zone(在一个可用区域里的随机结点。)分布式的调度器和理解异构主机的调度器正在开发之中。
如你所见,OpenStack Compute为我们想象的服务提供商,提供了一个不错的基础,只要服务提供商愿意做一些整合。
3.3 OpenStack Compute系统架构
OpenStack Compute由一些主要组件组成。“Cloud controller”包含很多组件,它表示全局状态,以及与其他组件交互。实际上,它提供的是Nova-api服务。它的功能是:为所有API查询提供一个端点,初始化绝大多数的部署活动,以及实施一些策略。API 服务器起cloud controller web Service前端的作用。Compute controller 提供compute服务资源,典型包含compute service,Object Store component可选地提供存储服务。Auth manager提供认证和授权服务,Volume controller为compute servers提供快速和持久的块级别存储。Network controller提供虚拟网络使compute servers彼此交互以及与公网进行交互。Scheduler选择最合适的compute controller来管理(host)一个实例。
OpenStack Compute建立在无共享、基于消息的架构上。Cloud controller通过HTTP与internal object store交互,通过AMQP和scheduler、network controller、 和volume controller 来进行通信。为了避免在等待接收时阻塞每个组件,OpenStack Compute用异步调用的方式。
为了获得带有一个组件多个备份的无共享属性,OpenStack Compute将所有的云系统状态保持在分布式的数据存储中。对系统状态的更新会写到这个存储中,必要时用质子事务。
对系统状态的请求会从store中读出。在少数情况下,控制器也会短时间缓存读取结果。
3.4 OpenStack Compute物理架构
OpenStack Compute采用无共享、基于消息的架构,非常灵活,我们能安装每个nova- service在单独的服务器上,这意味着安装OpenStack Compute有多种可能的方法。可能多结点部署唯一的联合依赖性,是Dashboard必须被安装在nova-api服务器。几种部署架构如下:
a) 单结点:一台服务器运行所有的nova- services,同时也驱动虚拟实例。这种配置只为尝试OpenStack Compute,或者为了开发目的;
b) 双结点:一个cloud controller 结点运行除nova-compute外的所有nova-services,compute结点运行nova-compute。一台客户计算机很可能需要打包镜像,以及和服务器进行交互,但是并不是必要的。这种配置主要用于概念和开发环境的证明。
c) 多结点:通过简单部署nova-compute在一台额外的服务器以及拷贝nova.conf文件到这个新增的结点,你能在两结点的基础上,添加更多的compute结点,形成多结点部署。在较为复杂的多结点部署中,还能增加一个volume controller 和一个network controller作为额外的结点。对于运行多个需要大量处理能力的虚拟机实例,至少是4个结点是最好的。
一个可能的Openstack Compute多服务器部署(集群中联网的虚拟服务器可能会改变)如下3-3所示:
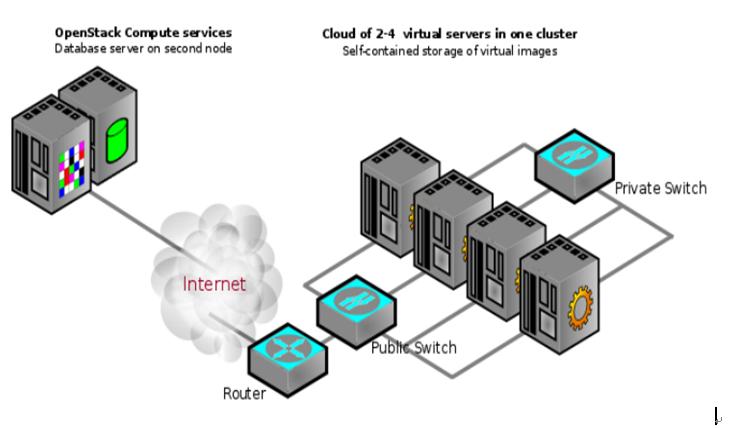
3-3 OpenStack Compute物理架构一
如果你注意到消息队列中大量的复制引发了性能问题,一种可选的架构是增加更多的Messaging服务器。在这种情形下,除了可以扩展数据库服务器外,还可以增加一台额外的RabbitMQ服务器。部署中可以在任意服务器上运行任意nova-service,只要nova.conf中配置为指向RabbitMQ服务器,并且这些服务器能发送消息到它。
下图3-4是另外一种多结点的部署架构。
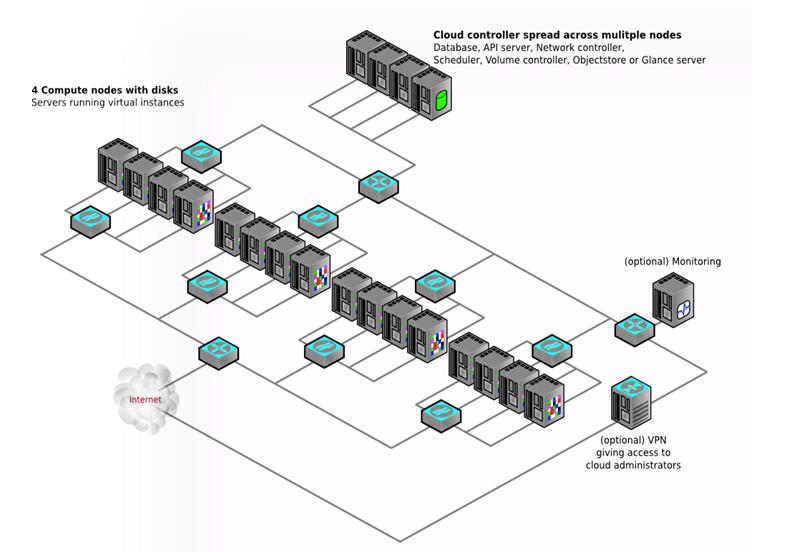
3-4 多结点的部署架构二
3.5 OpenStack Compute服务架构
因为Compute有多个服务,也可能有多种配置,下图3-5显示了总体的服务架构,以及服务之间的通信系统。
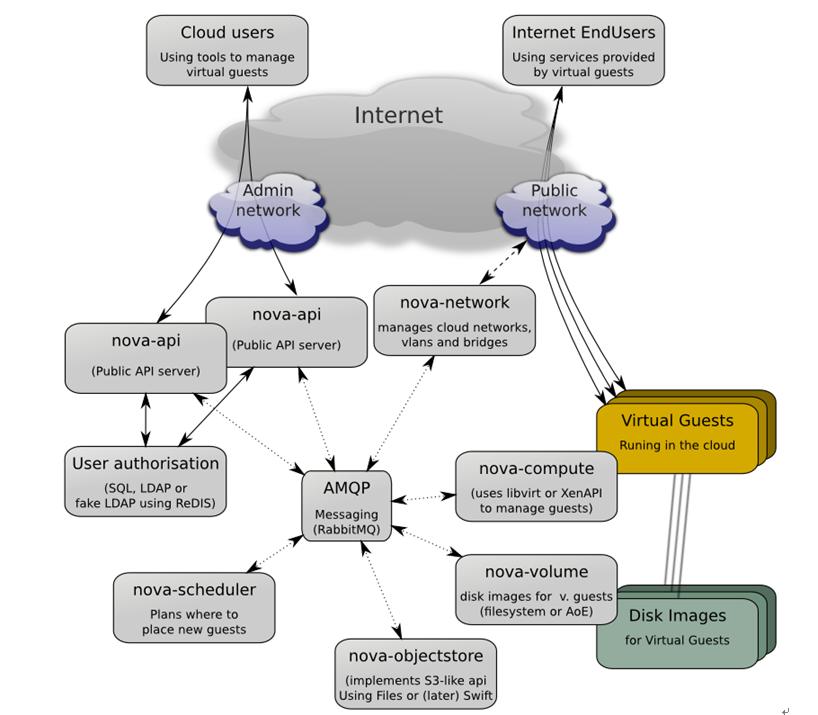
3-5 OpenStack Compute服务架构
4. OpenStack Image Service
OpenStack Image Service包括两个主要的部分,分别是API server和Registry server(s)。
OpenStack Image Service的设计,尽可能适合各种后端仓储和注册数据库方案。API Server(运行“glance api”程序)起通信hub的作用。比如各种各样的客户程序,镜像元数据的注册,实际包含虚拟机镜像数据的存储系统,都是通过它来进行通信的。API server转发客户端的请求到镜像元数据注册处和它的后端仓储。OpenStack Image Service就是通过这些机制来实际保存进来的虚拟机镜像的。
OpenStack Image Service支持的后端仓储有:
a) OpenStack Object Storage。它是OpenStack中高可用的对象存储项目。
b) FileSystem。OpenStack Image Service存储虚拟机镜像的默认后端是后端文件系统。这个简单的后端会把镜像文件写到本地文件系统。
c) S3。该后端允许OpenStack Image Service存储虚拟机镜像在Amazon S3服务中。
d) HTTP。OpenStack Image Service能通过HTTP在Internet上读取可用的虚拟机镜像。这种存储方式是只读的。
OpenStack Image Service registry servers是遵守OpenStack Image Service Registry API的服务器。
根据安装手册,这两个服务安装在同一个服务器上。镜像本身则可存储在OpenStack Object Storage, Amazon's S3 infrastructure,fileSystem。如果你只需要只读访问,可以存储在一台Web服务器上。
5. OpenStack Object Storage
5.1 关键概念
a) Accounts和 Account Servers
OpenStack Object Storage系统被设计来供许多不同的存储消费者或客户使用。每个用户必须通过认证系统来识别自己。为此,OpenStack Object Storage提供了一个授权系统(swauth)。
运行Account服务的结点与个体账户是不同的概念。Account服务器是存储系统的部分,必须和Container服务器和Object服务器配置在一起。
b) Authentication 和 Access Permissions
你必须通过认证服务来认证,以接收OpenStack Object Storage连接参数和认证令牌。令牌必须为所有后面的container/object操作而传递。典型的,特定语言的API处理认证,令牌传递和HTTPS request/response 通信。
通过运用X-Container-Read: accountname和 X-Container-Write: accountname:username,你能为用户或者账户对对象执行访问控制。比如,这个设置就允许来自accountname账户的的任意用户来读,但是只允许accountname账户里的用户username来写。你也能给OpenStack Object Storage中存储的对象授予公共访问的权限,而且可以通过Referer头部阻止像热链接这种基于站点的内容盗窃,来限制公共访问。公共的container设置被用作访问控制列表之上的默认授权。比如,X-Container-Read: referer: any 这个设置,允许任何人能从container中读,而不管其他的授权设置。
一般来说,每个用户能完全访问自己的存储账户。用户必须用他们的证书来认证,一旦被认证,他们就能创建或删除container,以及账户之类的对象。一个用户能访问另一个账户的内容的唯一方式是,他们享有一个API访问key或你的认证系统提供的会话令牌。
c) Containers and Objects
一个Container是一个存储隔间,为你提供一种组织属于属于你的数据的方式。它比较类似于文件夹或目录。Container和其他文件系统概念的主要差异是containers不能嵌套。然而,你可以在你的账户内创建无数的containers。但是你必须在你的账户上有一个container,因为数据必须存在Container中。
Container取名上的限制是,它们不能包含“/”,而且长度上少于256字节。长度的限制也适用于经过URL编码后的名字。比如,Course Docs的Container名经过URL编码后是“Course%20Docs”,因此此时的长度是13字节而非11字节。
一个对象是基本的存储实体,和表示你存储在OpenStack Object Storage系统中文件的任何可选的元数据。当你上传数据到OpenStack Object Storage,它原样存储,由一个位置(container),对象名,以及key/value对组成的任何元数据。比如,你可选择存储你数字照片的副本,把它们组织为一个影集。在这种情况下,每个对象可以用元数据Album :
Caribbean Cruise 或Album : Aspen Ski Trip来标记。
对象名上唯一的限制是,在经过URL编码后,它们的长度要少于1024个字节。
上传的存储对象的允许的最大大小5GB,最小是0字节。你能用内嵌的大对象支持和St工具来检索5GB以上的对象。对于元数据,每个对象不应该超过90个key/value对,所有key/value对的总字节长度不应该超过4KB。
d) Operations
Operations是你在OpenStack Object Storage系统上执行的行为,比如创建或删除containers,上传或下载objects等等。Operations的完全清单可以在开发文档上找到。Operations能通过ReST web service API或特定语言的API来执行。值得强调的是,所有操作必须包括一个来自你授权系统的有效的授权令牌。
e) 特定语言的API绑定
一些流行语言支持的API 绑定,在RackSpace云文件产品中是可用的。这些绑定在基础ReST API上提供了一层抽象,允许变成人员直接与container和object模型打交道,而不是HTTP请求和响应。这些绑定可免费下载,使用和修改。它们遵循MIT许可协议。对于OpenStack Object Storage,当前支持的API绑定是:PHP,Python,Java,C#/.NET 和Ruby。
5.2 Object Storage如何工作
a) Ring
Ring 代表磁盘上存储的实体的名称和它们的物理位置的映射。accounts, containers, and objects都有单独的Ring。其他组件要在这三者之一进行任何操作,他们都需要合相应的Ring进行交互以确定它在集群中的位置。
Ring用zones,devices,partitions,和replicas来维护映射,在Ring中的每个分区都会在集群中默认有三个副本。分区的位置存储在Ring维护的映射中。Ring也负责确定失败场景中接替的设备。(这点类似HDFS副本的复制)。分区的副本要保证存储在不同的zone。Ring的分区分布在OpenStack Object Storage installation所有设备中。分区需要移动的时候,Ring确保一次移动最少的分区,一次仅有一个分区的副本被移动。
权重能用来平衡分区在磁盘驱动上的分布。Ring在代理服务器和一些背景进程中使用。
b) Proxy Server
代理服务器负责将OpenStack Object Storage架构中其他部分结合在一起。对于每次请求,它都查询在Ring中查询account, container, or object的位置,并以此转发请求。公有APIs也是通过代理服务器来暴露的。
大量的失败也是由代理服务器来进行处理。比如一个服务器不可用,它就会要求Ring来为它找下一个接替的服务器,并把请求转发到那里。
当对象流进或流出object server时,它们都通过代理服务器来流给用户,或者通过它从用户获取。代理服务器不会缓冲它们。
Proxy服务器的功能可以总结为:查询位置,处理失败,中转对象。
c) Object Server
Object Server,是非常简单的blob存储服务器,能存储、检索和删除本地磁盘上的对象,它以二进制文件形式存放在文件系统中,元数据以文件的扩展属性存放。
对象以源于对象名的hash和操作的时间戳的路径来存放。上一次写总会成功,确保最新的版本将被使用。删除也视作文件的一个版本:这确保删除的文件也被正确复制,更旧的把本不会因为失败情形离奇消失。
d) Container Server
其主要工作是处理对象列表,它不知道对象在哪里,只是知道哪些对象在一个特定的container。列表被存储为sqlite 数据库文件,类似对象的方式在集群中复制。也进行了跟踪统计,包括对象的总数,以及container中使用的总存储量。
e) Account Server
它是类似于Container Server,除了它是负责containers的列表而非对象。
f) Replication
设计副本的目的是,在面临网络中断或驱动失败等临时错误条件时,保持系统在一致的状态。
副本进程会比较本地的数据和每个远处的副本,以确保他们所有都包含最新的版本。对象副本用一个Hash列表来快速比较每个分区的片段,而containe和 account replication 用的是Hash和共享的高水印结合的方法。
副本的更新,是基于推送的。对于对象副本,更新是远程同步文件到Peer。Account和container replication通过HTTP or rsync把整个数据库文件推送遗失的记录。
副本也通过tombstone设置最新版本的方式,确保数据从系统中清除。
g) 更新器(Updaters)
有时,container 或 account数据不能被立即更新,这通常是发生在失败的情形或高负载时期。如果一个更新失败,该更新会在文件系统上本地排队,更新器将处理这些失败的更新。事件一致性窗口(eventual consistency window)最可能来起作用。比如,假设一个container服务器正处于载入之中,一个新对象正被放进系统,代理服务器一响应客户端成功,该对象就立即可读了。然而,container服务器没有更新Object列表,所以更新就进入队列,以等待稍后的更新。Container列表,因此可能还不会立即包含这个对象。
实际上,一致性窗口只是与updater运行的频率一样大,当代理服务器将转发清单请求到响应的第一个container服务器中,也许甚至还不会被注意。在载入之下的服务器可能还不是服务后续清单请求的那个。另外两个副本中的一个可能处理这个清单。
h) Auditors
Auditors会检查objects, containers, 和 accounts的完整性。如果发先损坏的文件,它将被隔离,好的副本将会取代这个坏的文件。如果发现其他的错误,它们会记入到日志中。
5.3 OpenStack Object Storage物理架构
Proxy Services 偏向于CPU和network I/O 密集型,而 Object Services, Container Services, Account Services 偏向于disk and networkI/O 密集型。
可以在每一服务器上安装所有的服务,在Rackspace内部, 他们将Proxy Services放在他们自己的服务器上,而所有存储服务则放在同一服务器上。这允许我们发送10G的网络给代理,1G给存储服务器,从而保持对代理服务器的负载平衡更好管理。我们能通过增加更多代理来扩展整个API吞吐量。如果需要获得Account或 Container Services更大的吞吐量,它们也可以部署到自己的服务器上。
在部署OpenStack Object Storage时,可以单结点安装,但是它只适用于开发和测试目的。也可以多服务器的安装,它能获得分布式对象存储系统需要的高可用性和冗余。
有这样一个样本部署架构,如图5-1所示。一个Proxy 结点,运行代理服务,一个Auth 结点,运行认证服务,五个Storage结点,运行Account,Container和Object服务。
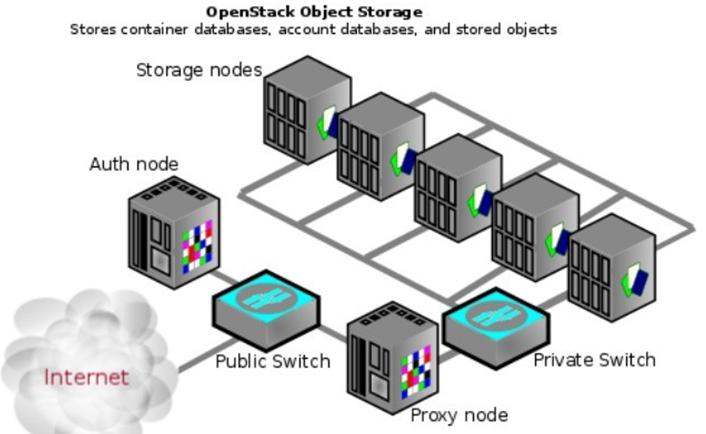
5-1 五个Storage结点的OpenStack Object Storage物理架构
以上希望让大家对openstack有一定了解
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)