一、BN层概念明晰
BN层存在的意义:让较深的神经网络的训练变得更加容易。
BN层的工作内容:利用小批量数据样本的均值和标准差,不断调整神经网络中间输出,使整个神经网络在各层的中间输出的数值更加稳定。

BN层在Net中的运算方式:考虑图像首个CBA层,[3*416*416]经过16个通道的3*3卷积后变为[16*416*416],则之后的BN层会有16个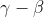 组,每个通道都对应一组。train时使用Batch内归一化,同时计算滑动平均;test时会用滑动平均中存的值。
组,每个通道都对应一组。train时使用Batch内归一化,同时计算滑动平均;test时会用滑动平均中存的值。
BN层注意事项:训练模式和预测模式计算结果不同。
训练模式下:数据是成批的,可以进行批内求均值、求方差,进而得到归一化结果,最后乘以拉伸参数(scale— )和偏移参数(shift—
)和偏移参数(shift—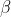 )得到BN层结果;同时,训练过程中还会对整个数据集的全局均值和全局方差进行移动平均估计和记录。
)得到BN层结果;同时,训练过程中还会对整个数据集的全局均值和全局方差进行移动平均估计和记录。
预测模式下:样本都是单张送入,无法使用Batch方式计算均值和方差,此时使用训练过程中记录的全局均值和全局方差进行归一化,之后用学习到的拉伸参数(scale—)和偏移参数(shift—)得到BN层结果。
注:Pytorch的网络搭建好了之后需要进行模式选择,也就是model.train()或者model.eval()。model.eval()预测时会自动把BN和DropOut层固定住,不会取平均,而是使用训练好的值。
二、Pytorch简易实现代码
《动手学深度学习》中的原理示例型代码,帮助理解网络层搭建过程:
def batch_norm(is_training, X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 预测模式
if not is_training:
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps) # 直接使用传入的移动平均所得的均值和方差
# 训练模式
else:
assert len(X.shape) in (2, 4) # 样本数为2,特征数为4
if len(X.shape) == 2: # 使用全连接层的情况,计算特征维上的均值和方差,数据维度1*4
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持
# X的形状以便后面可以做广播运算
mean = X.mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
var = ((X - mean) ** 2).mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
# 训练模式下用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 拉伸和偏移
return Y, moving_mean, moving_var
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims):
super(BatchNorm, self).__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 不参与求梯度和迭代的变量,全在内存上初始化成0
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.zeros(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var, Module实例的traning属性默认为true, 调用.eval()后设成false
Y, self.moving_mean, self.moving_var = batch_norm(self.training,X, self.gamma, self.beta, self.moving_mean,self.moving_var, eps=1e-5, momentum=0.9)
return Y
三、Pytorch中BN网络搭建
此例是Pytorch的YOLO实现中网络搭建和参数load方法:
搭建:
modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9, eps=1e-5))
数据加载:(我的天这个好麻烦)
ptr = 0
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
if i == cutoff:
break
if module_def["type"] == "convolutional":
conv_layer = module[0]
if module_def["batch_normalize"]:
# Load BN bias, weights, running mean and running variance
bn_layer = module[1]
num_b = bn_layer.bias.numel() # Number of biases
# Bias
bn_b = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn_layer.bias)
bn_layer.bias.data.copy_(bn_b)
ptr += num_b
# Weight
bn_w = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn_layer.weight)
bn_layer.weight.data.copy_(bn_w)
ptr += num_b
# Running Mean
bn_rm = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn_layer.running_mean)
bn_layer.running_mean.data.copy_(bn_rm)
ptr += num_b
# Running Var
bn_rv = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(bn_layer.running_var)
bn_layer.running_var.data.copy_(bn_rv)
ptr += num_b
else:
# Load conv. bias
num_b = conv_layer.bias.numel()
conv_b = torch.from_numpy(weights[ptr: ptr + num_b]).view_as(conv_layer.bias)
conv_layer.bias.data.copy_(conv_b)
ptr += num_b
# Load conv. weights
num_w = conv_layer.weight.numel()
conv_w = torch.from_numpy(weights[ptr: ptr + num_w]).view_as(conv_layer.weight)
conv_layer.weight.data.copy_(conv_w)
ptr += num_w
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)