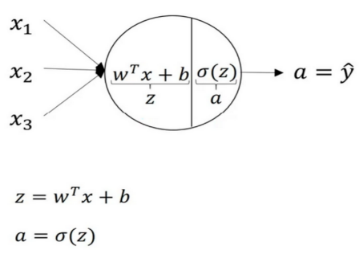
第一步,计算
z
1
[
1
]
,
z
1
[
1
]
=
w
1
[
1
]
T
x
+
b
1
[
1
]
z^{[1]}_1,z^{[1]}_1 = w^{[1]T}_1x + b^{[1]}_1
z1[1],z1[1]=w1[1]Tx+b1[1]。
第二步,通过激活函数计算
a
1
[
1
]
,
a
1
[
1
]
=
σ
(
z
1
[
1
]
)
a^{[1]}_1,a^{[1]}_1 = \sigma(z^{[1]}_1)
a1[1],a1[1]=σ(z1[1])。
隐藏层的第二个以及后面两个神经元的计算过程一样,只是注意符号表示不同,最终分别得到
a
2
[
1
]
、
a
3
[
1
]
、
a
4
[
1
]
a^{[1]}_2、a^{[1]}_3、a^{[1]}_4
a2[1]、a3[1]、a4[1],详细结果见下:
z
1
[
1
]
=
w
1
[
1
]
T
x
+
b
1
[
1
]
,
a
1
[
1
]
=
σ
(
z
1
[
1
]
)
z^{[1]}_1 = w^{[1]T}_1x + b^{[1]}_1, a^{[1]}_1 = \sigma(z^{[1]}_1)
z1[1]=w1[1]Tx+b1[1],a1[1]=σ(z1[1])
z
2
[
1
]
=
w
2
[
1
]
T
x
+
b
2
[
1
]
,
a
2
[
1
]
=
σ
(
z
2
[
1
]
)
z^{[1]}_2 = w^{[1]T}_2x + b^{[1]}_2, a^{[1]}_2 = \sigma(z^{[1]}_2)
z2[1]=w2[1]Tx+b2[1],a2[1]=σ(z2[1])
z
3
[
1
]
=
w
3
[
1
]
T
x
+
b
3
[
1
]
,
a
3
[
1
]
=
σ
(
z
3
[
1
]
)
z^{[1]}_3 = w^{[1]T}_3x + b^{[1]}_3, a^{[1]}_3 = \sigma(z^{[1]}_3)
z3[1]=w3[1]Tx+b3[1],a3[1]=σ(z3[1])
z
4
[
1
]
=
w
4
[
1
]
T
x
+
b
4
[
1
]
,
a
4
[
1
]
=
σ
(
z
4
[
1
]
)
z^{[1]}_4 = w^{[1]T}_4x + b^{[1]}_4, a^{[1]}_4 = \sigma(z^{[1]}_4)
z4[1]=w4[1]Tx+b4[1],a4[1]=σ(z4[1])
向量化计算 如果你执行神经网络的程序,用for循环来做这些看起来真的很低效。所以接下来我们要做的就是把这四个等式向量化。向量化的过程是将神经网络中的一层神经元参数纵向堆积起来,例如隐藏层中的
w
w
w纵向堆积起来变成一个
(
4
,
3
)
(4,3)
(4,3)的矩阵,用符号
W
[
1
]
W^{[1]}
W[1]表示。另一个看待这个的方法是我们有四个逻辑回归单元,且每一个逻辑回归单元都有相对应的参数——向量
w
w
w,把这四个向量堆积在一起,你会得出这4×3的矩阵。 因此, 公式如下:
z
[
n
]
=
w
[
n
]
x
+
b
[
n
]
z^{[n]} = w^{[n]}x + b^{[n]}
z[n]=w[n]x+b[n]
a
[
n
]
=
σ
(
z
[
n
]
)
a^{[n]}=\sigma(z^{[n]})
a[n]=σ(z[n])
详细过程见下:
a
[
1
]
=
[
a
1
[
1
]
a
2
[
1
]
a
3
[
1
]
a
4
[
1
]
]
=
σ
(
z
[
1
]
)
a^{[1]} = \left[ \begin{array}{c} a^{[1]}_{1}\\ a^{[1]}_{2}\\ a^{[1]}_{3}\\ a^{[1]}_{4} \end{array} \right] = \sigma(z^{[1]})
a[1]=⎣⎢⎢⎢⎡a1[1]a2[1]a3[1]a4[1]⎦⎥⎥⎥⎤=σ(z[1])
[
z
1
[
1
]
z
2
[
1
]
z
3
[
1
]
z
4
[
1
]
]
=
[
.
.
.
W
1
[
1
]
T
.
.
.
.
.
.
W
2
[
1
]
T
.
.
.
.
.
.
W
3
[
1
]
T
.
.
.
.
.
.
W
4
[
1
]
T
.
.
.
]
⏞
W
[
1
]
∗
[
x
1
x
2
x
3
]
⏞
i
n
p
u
t
+
[
b
1
[
1
]
b
2
[
1
]
b
3
[
1
]
b
4
[
1
]
]
⏞
b
[
1
]
\left[ \begin{array}{c} z^{[1]}_{1}\\ z^{[1]}_{2}\\ z^{[1]}_{3}\\ z^{[1]}_{4}\\ \end{array} \right] = \overbrace{ \left[ \begin{array}{c} ...W^{[1]T}_{1}...\\ ...W^{[1]T}_{2}...\\ ...W^{[1]T}_{3}...\\ ...W^{[1]T}_{4}... \end{array} \right] }^{W^{[1]}} * \overbrace{ \left[ \begin{array}{c} x_1\\ x_2\\ x_3\\ \end{array} \right] }^{input} + \overbrace{ \left[ \begin{array}{c} b^{[1]}_1\\ b^{[1]}_2\\ b^{[1]}_3\\ b^{[1]}_4\\ \end{array} \right] }^{b^{[1]}}
⎣⎢⎢⎢⎡z1[1]z2[1]z3[1]z4[1]⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡...W1[1]T......W2[1]T......W3[1]T......W4[1]T...⎦⎥⎥⎥⎤W[1]∗⎣⎡x1x2x3⎦⎤input+⎣⎢⎢⎢⎡b1[1]b2[1]b3[1]b4[1]⎦⎥⎥⎥⎤b[1]
对于神经网络的第一层,给予一个输入
x
x
x,得到
a
[
1
]
a^{[1]}
a[1],
x
x
x可以表示为
a
[
0
]
a^{[0]}
a[0]。通过相似的衍生你会发现,后一层的表示同样可以写成类似的形式,得到
a
[
2
]
a^{[2]}
a[2],
y
^
=
a
[
2
]
\hat{y} = a^{[2]}
y^=a[2],具体过程见上述公式。
A
[
1
]
=
[
⋮
⋮
⋮
⋮
α
[
1
]
(
1
)
α
[
1
]
(
2
)
⋯
α
[
1
]
(
m
)
⋮
⋮
⋮
⋮
]
A^{[1]} = \left[ \begin{array}{c} \vdots & \vdots & \vdots & \vdots\\ \alpha^{[1](1)} & \alpha^{[1](2)} & \cdots & \alpha^{[1](m)}\\ \vdots & \vdots & \vdots & \vdots\\ \end{array} \right]
A[1]=⎣⎢⎢⎡⋮α[1](1)⋮⋮α[1](2)⋮⋮⋯⋮⋮α[1](m)⋮⎦⎥⎥⎤ 公式:
z
[
1
]
(
i
)
=
W
[
1
]
(
i
)
x
(
i
)
+
b
[
1
]
α
[
1
]
(
i
)
=
σ
(
z
[
1
]
(
i
)
)
z
[
2
]
(
i
)
=
W
[
2
]
(
i
)
α
[
1
]
(
i
)
+
b
[
2
]
α
[
2
]
(
i
)
=
σ
(
z
[
2
]
(
i
)
)
}
⟹
{
A
[
1
]
=
σ
(
z
[
1
]
)
z
[
2
]
=
W
[
2
]
A
[
1
]
+
b
[
2
]
A
[
2
]
=
σ
(
z
[
2
]
)
\left. \begin{array}{r} \text{$z^{[1](i)} = W^{[1](i)}x^{(i)} + b^{[1]}$}\\ \text{$\alpha^{[1](i)} = \sigma(z^{[1](i)})$}\\ \text{$z^{[2](i)} = W^{[2](i)}\alpha^{[1](i)} + b^{[2]}$}\\ \text{$\alpha^{[2](i)} = \sigma(z^{[2](i)})$}\\ \end{array} \right\} \implies \begin{cases} \text{$A^{[1]} = \sigma(z^{[1]})$}\\ \text{$z^{[2]} = W^{[2]}A^{[1]} + b^{[2]}$}\\ \text{$A^{[2]} = \sigma(z^{[2]})$}\\ \end{cases}
z[1](i)=W[1](i)x(i)+b[1]α[1](i)=σ(z[1](i))z[2](i)=W[2](i)α[1](i)+b[2]α[2](i)=σ(z[2](i))⎭⎪⎪⎬⎪⎪⎫⟹⎩⎪⎨⎪⎧A[1]=σ(z[1])z[2]=W[2]A[1]+b[2]A[2]=σ(z[2])
定义矩阵
X
X
X等于训练样本,将它们组合成矩阵的各列,形成一个
n
n
n维或
n
n
n乘以
m
m
m维矩阵。接下来计算见上述公式
以此类推,从小写的向量
x
x
x到这个大写的矩阵
X
X
X,只是通过组合
x
x
x向量在矩阵的各列中。
同理,
z
[
1
]
(
1
)
z^{[1](1)}
z[1](1),
z
[
1
]
(
2
)
z^{[1](2)}
z[1](2)等等都是
z
[
1
]
(
m
)
z^{[1](m)}
z[1](m)的列向量,将所有
m
m
m都组合在各列中,就的到矩阵
Z
[
1
]
Z^{[1]}
Z[1]。
同理,
a
[
1
]
(
1
)
a^{[1](1)}
a[1](1),
a
[
1
]
(
2
)
a^{[1](2)}
a[1](2),……,
a
[
1
]
(
m
)
a^{[1](m)}
a[1](m)将其组合在矩阵各列中,如同从向量
x
x
x到矩阵
X
X
X,以及从向量
z
z
z到矩阵
Z
Z
Z一样,就能得到矩阵
A
[
1
]
A^{[1]}
A[1]。
同样的,对于
Z
[
2
]
Z^{[2]}
Z[2]和
A
[
2
]
A^{[2]}
A[2],也是这样得到。