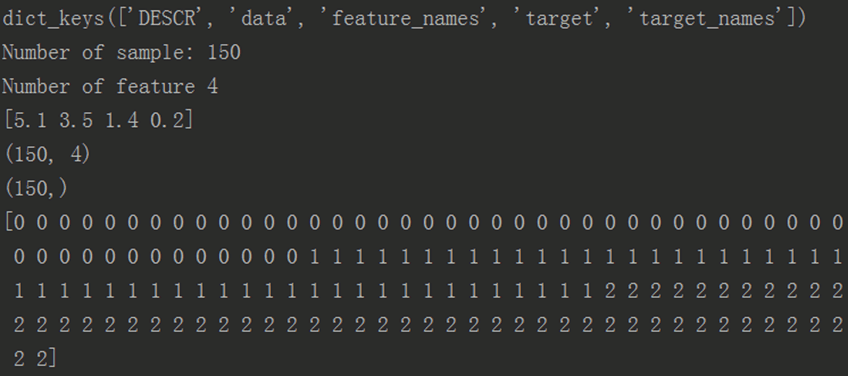
from sklearn.datasets import load_iris#加载数据集iris = load_iris()print(iris.keys())#数据的条数和维数n_samples, n_features = iris.data.shapeprint("Number of sample:", n_samples) #150个样本个数print("Number of feature", n_features) #4个特征#第一个样例print(iris.data[0]) #[5.1 3.5 1.4 0.2]print(iris.data.shape) #(150, 4)print(iris.target.shape) #(150,)print(iris.target) #样本分类
打印结果:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)