评论中的链接包含了答案。下面我将公式简化后的内容放在这个简单的示例中,因为结果有些直观。
lmer fits a model of the form 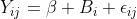 , where
, where 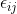 and
and 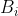 are independent normals with variances
are independent normals with variances 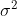 and
and 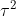 respectively. The joint probability distribution of
respectively. The joint probability distribution of 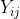 and is therefore
and is therefore
where
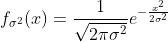 .
.
The likelihood is obtained by integrating this with respect to 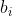 (which isn't observed) to give
(which isn't observed) to give
where 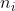 is the number of observations from group
is the number of observations from group  , and
, and 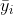 is the mean of observations from group . This is somewhat intuitive since the first term captures spread within each group, which should have variance , and the second captures the spread between groups. Note that
is the mean of observations from group . This is somewhat intuitive since the first term captures spread within each group, which should have variance , and the second captures the spread between groups. Note that 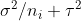 is the variance of .
is the variance of .
However, by default (REML=T) lmer maximises not the likelihood but the "REML criterion", obtained by additionally integrating this with respect to 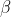 to give
to give
where 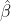 is given below.
is given below.
最大化似然 (REML=F)
If 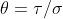 is fixed, we can explicitly find the and
is fixed, we can explicitly find the and 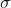 which maximise likelihood. They turn out to be
which maximise likelihood. They turn out to be
Note 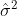 has two terms for variation within and between groups, and is somewhere between the mean of
has two terms for variation within and between groups, and is somewhere between the mean of 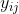 and the mean of depending on the value of
and the mean of depending on the value of 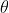 .
.
Substituting these into likelihood, we can express the log likelihood 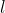 in terms of only:
in terms of only:
lmer iterates to find the value of which minimises this. In the output, 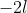 and are shown in the fields "deviance" and "logLik" (if REML=F) respectively.
and are shown in the fields "deviance" and "logLik" (if REML=F) respectively.
最大化限制似然 (REML=T)
Since the REML criterion doesn't depend on , we use the same estimate for as above. We estimate to maximise the REML criterion:
The restricted log likelihood 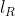 is given by
is given by
In the output of lmer, 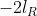 and are shown in the fields "REMLdev" and "logLik" (if REML=T) respectively.
and are shown in the fields "REMLdev" and "logLik" (if REML=T) respectively.