视觉 SLAM 十四讲 —— 第十三讲 建图
在前端和后端中,我们重点关注同时估计相机运动轨迹与特征点空间位置的问题。然而,在实际使用 SLAM 时,除了对相机本体进行定位之外,还存在许多其他的需求。例如,考虑放在机器人上的 SLAM,那么我们会希望地图能够用于定位、导航、避障和交互,特征点地图显然不能满足所有的这些需求。所以,本章我们将更详细地讨论各种形式的地图,并指出目前视觉 SLAM 地图中存在着的缺陷。
概述
在视觉 SLAM 看来,“建图”是服务于“定位”的;但是在应用层面看来,“建图”明显还带有许多其他的需求。关于地图的用处,我们大致归纳如下
- 定位。定位是地图的一个基本功能。在前面的视觉里程计章节,我们讨论了如何利用局部地图来实现定位。或者,在回环检测章节,我们也看到,只要有全局的描述子信息,我们也能通过回环检测确定机器人的位置。更进一步,我们还希望能够把地图保
存下来,让机器人在下次开机后依然能在地图中定位,这样只需对地图进行一次建模,而不是每次启动机器人都重新做一次完整的 SLAM。 - 导航。导航是指机器人能够在地图中进行路径规划,从任意两个地图点间寻找路径,然后控制自己运动到目标点的过程。该过程中,我们至少需要知道地图中哪些地方不可通过,而哪些地方是可以通过的。这就超出了稀疏特征点地图的能力范围,我们必
须有另外的地图形式。稍后我们会说,这至少得是一种稠密的地图。 - 避障。避障也是机器人经常碰到的一个问题。它与导航类似,但更注重局部的、动态的障碍物的处理。同样的,仅有特征点,我们无法判断某个特征点是否为障碍物,所以我们将需要稠密地图。
- 重建。有时候,我们希望利用 SLAM 获得周围环境的重建效果,并把它展示给其他人看。这种地图主要用于向人展示,所以我们希望它看上去比较舒服、美观。或者,我们也可以把该地图用于通讯,使其他人能够远程地观看我们重建得到的三维物体
或场景——例如三维的视频通话或者网上购物等等。这种地图亦是稠密的,并且我们还对它的外观有一些要求。我们可能不满足于稠密点云重建,更希望能够构建带纹理的平面,就像电子游戏中的三维场景那样。 - 交互。交互主要指人与地图之间的互动。例如,在增强现实中,我们会在房间里放置虚拟的物体,并与这些虚拟物体之间有一些互动——比方说我会点击墙面上放着的虚拟网页浏览器来观看视频,或者向墙面投掷物体,希望它们有(虚拟的)物理碰撞。
另一方面,机器人应用中也会有与人、与地图之间的交互。例如机器人可能会收到命令“取桌子上的报纸”,那么,除了有环境地图之外,机器人还需要知道哪一块地图是“桌子”,什么叫做“之上”,什么又叫做“报纸”。这需要机器人对地图有更高级层面的认知——亦称为语义地图。

单目稠密重建
立体视觉
那么,在稠密深度图估计中,不同之处在于,我们无法把每个像素都当作特征点,计算描述子。因此,稠密深度估计问题中,匹配就成为很重要的一环:如何确定第一张图的某像素,出现在其他图里的位置呢?这需要用到极线搜索和块匹配技术。然后,当我们
知道了某个像素在各个图中的位置,就能像特征点那样,利用三角测量确定它的深度。不过不同的是,在这里我们要使用很多次三角测量让深度估计收敛,而不仅是一次。我们希望深度估计,能够随着测量的增加,从一个非常不确定的量,逐渐收敛到一个稳定值。这就是深度滤波器技术。所以,下面的内容将主要围绕这个主题展开。
极线搜索与块匹配

左边的相机观测到了某个像素 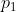 。由于这是一个单目相机,我们无从知道它的深度,所以假设这个深度可能在某个区域之内,不妨说是某最小值到无穷远之间:
。由于这是一个单目相机,我们无从知道它的深度,所以假设这个深度可能在某个区域之内,不妨说是某最小值到无穷远之间: 。因此,该像素对应的空间点就分布在某条线段(本例中是射线)上。在另一个视角(右侧相机)看来,这条线段的投影也形成图像平面上的一条线,我们知道这称为极线。当我们知道两个相机间的运动时,这条极线也是能够确定的。
。因此,该像素对应的空间点就分布在某条线段(本例中是射线)上。在另一个视角(右侧相机)看来,这条线段的投影也形成图像平面上的一条线,我们知道这称为极线。当我们知道两个相机间的运动时,这条极线也是能够确定的。
在直接法的讨论中我们也知道,比较单个像素的亮度值并不一定稳定可靠。一种直观的想法是:既然单个像素的亮度没有区分性,那是否可以比较像素块呢?我们在 周围取一个大小为  的小块,然后在极线上也取很多同样大小的小块进行比较,就可以一定程度上提高区分性。这就是所谓的块匹配。
的小块,然后在极线上也取很多同样大小的小块进行比较,就可以一定程度上提高区分性。这就是所谓的块匹配。
常用的块匹配方法包括:
- SAD(Sum of Absolute Difference)
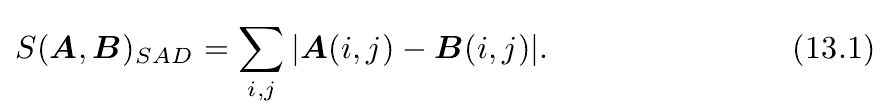
- SSD(Sum of Squared Distance)
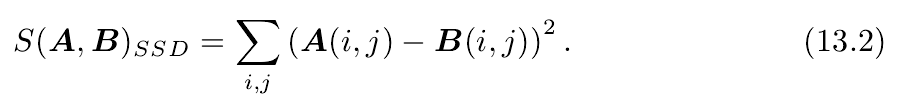
- NCC(Normalized Cross Correlation)
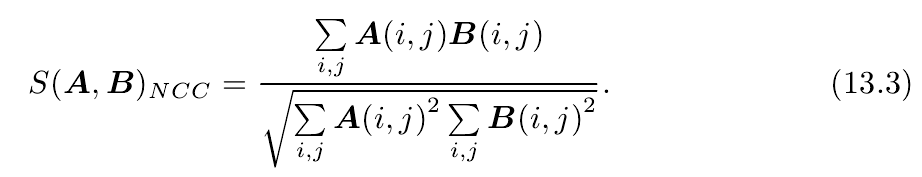
和我们遇到过的许多情形一样,这些计算方式往往存在一个精度——效率之间的矛盾。精度好的方法往往需要复杂的计算,而简单的快速算法又往往效果不佳。这需要我们在实际工程中进行取舍。另外,除了这些简单版本之外,我们可以先把每个小块的均值去掉,称为去均值的 SSD、去均值的 NCC 等等。去掉均值之后,我们允许像“小块 B 比 A 整体上亮一些,但仍然很相似”这样的情况,因此比之前的更加可靠一些。
在搜索距离较长的情况下,我们通常会得到一个非凸函数:这个分布存在着许多峰值,然而真实的对应点必定只有一个。在这种情况下,我们会倾向于使用概率分布来描述深度值,而非用某个单一个的数值来描述深度。于是,我们的问题就转到了,在不断对不同图像进行极线搜索时,我们估计的深度分布将发生怎样的变化——这就是所谓的深度滤波器。
高斯分布的深度滤波器
对像素点深度的估计,本身亦可建模为一个状态估计问题,于是就自然存在滤波器与非线性优化两种求解思路。虽然非线性优化效果较好,但是在 SLAM 这种实时性要求较强的场合,考虑到前端已经占据了不少的计算量,建图方面则通常采用计算量较少的滤波器
方式了。
对深度的分布假设存在着若干种不同的做法。首先,在比较简单的假设条件下,我们可以假设深度值服从高斯分布,得到一种类卡尔曼式的方法(我们稍后会看到)。而另一方面,在某些工作中,亦采用了均匀——高斯混合分布的假设,推导了另一种形式更
为复杂的深度滤波器。
对于简单的高斯分布假设,可得融合后的高斯分布的均值和方差为

对于量测不确定性的估计,可以根据如下几何关系求得。
综上所述,我们给出了估计稠密深度的一个完整的过程:
- 假设所有像素的深度满足某个初始的高斯分布;
- 当新数据产生时,通过极线搜索和块匹配确定投影点位置;
- 根据几何关系计算三角化后的深度以及不确定性;
- 将当前观测融合进上一次的估计中。若收敛则停止计算,否则返回 2。
实验分析与讨论
由于真实数据的复杂性,能够在实际环境下工作的程序,往往需要周密的考虑和大量的工程技巧,这使得每种实际可行的代码都极其复杂——它们很难向初学者解释清楚,所以我们只好使用不那么有效,但相对易读易写的实现方式。这里仅提出若干种对演
示程序加以改进的意见。
像素梯度的问题
块匹配的正确与否,依赖于图像块是否具有区分度。显然,如果图像块仅是一片黑或者一片白,缺少有效的信息,那么在NCC 计算中,我们就很可能错误地将它与周围的某块像素给匹配起来。
在进行块匹配(和 NCC 的计算)时,我们必须假设小块不变,然后将该小块与其他小块进行对比。这时,有明显梯度的小块将具有良好的区分度,不易引起误匹配。对于梯度不明显的像素,由于在块匹配时没有区分性,所以我们将难以有效地估计其深度。反之,像素梯度比较明显的地方,我们得到的深度信息也相对准确,例如桌面上的杂志、电话等具有明显纹理的物体。因此,演示程序反映了立体视觉中一个非常常见的问题:对物体纹理的依赖性。该问题在双目视觉中也极其常见,体现了立体视觉的重建质量,十分依赖于环境纹理。
逆深度
从另一个角度来看,我们不妨可以问:把像素深度假设成高斯分布,是否合适呢?这里关系到一个参数化的问题(Parameterization)。
仔细想想,深度的正态分布确实存在一些问题:
- 我们实际想表达的是:这个场景深度大概是 5-10 米,可能有一些更远的点,但近处肯定不会小于相机焦距(或认为深度不会小于 0)。这个分布并不是像高斯分布那样,形成一个对称的形状。它的尾部可能稍长,而负数区域则为零。
- 在一些室外应用中,可能存在距离非常远,乃至无穷远处的点。我们的初始值中难以涵盖这些点,并且用高斯分布描述它们会有一些数值计算上的困难。
于是,逆深度应运而生。人们在仿真中发现,假设深度的倒数,也就是逆深度,为高斯分布是比较有效的。随后,在实际应用中,逆深度也具有更好的数值稳定性,从而逐渐成为一种通用的技巧,存在于现有 SLAM 方案中的标准做法中。
图像间的变换
在块匹配之前,做一次图像到图像间的变换亦是一种常见的预处理方式。这是因为,我们假设了图像小块在相机运动时保持不变,而这个假设在相机平移时(示例数据集基本都是这样的例子)能够保持成立,但当相机发生明显的旋转时,就难以继续保持了。特别地,当相机绕光心旋转时,一个下黑上白的图像可能会变成一个上黑下白的图像块,导致相关性直接变成了负数(尽管仍然是同样一个块)。
为了防止这种情况的出现,我们通常需要在块匹配之前,把参考帧与当前帧之间的运动考虑进来。根据仿射变换矩阵,我们可以把当前帧(或参考帧)的像素进行变换后,再进行块匹配,以期获得对旋转更好的效果。
并行化:效率的问题
在实验当中我们也看到,稠密深度图的估计非常费时,这是因为我们要估计的点从原先的数百个特征点,一下子变成了几十万个像素点,即使现在主流的 CPU 无法实时地计算那样庞大的数量。不过,该问题亦有另一个性质:这几十万个像素点的深度估计是彼此
无关的!这使并行化有了用武之地。
GPU 的并行计算架构非常适合这样的问题,因此,在单双和双目的稠密重建中,经常看到利用 GPU 进行并行加速的方式。
其他的改进
- 现在各像素完全是独立计算的,可能存在这个像素深度很小,边上一个又很大的情况。我们可以假设深度图中相邻的深度变化不会太大,从而给深度估计加上了空间正则项。这种做法会使得到的深度图更加平滑。
- 我们没有显式地处理外点(Outlier)的情况。事实上,由于遮挡、光照、运动模糊等各种因素的影响,不可能对每个像素都能保持成功的匹配。而演示程序的做法中,只要 NCC 大于一定值,就认为出现了成功的匹配,没有考虑到错误匹配的情况。
处理错误匹配亦有若干种方式。例如,G. Vogiatzis and C. Hernández, “Video-based, real-time multi-view stereo,” Image and Vision Computing 提出的均匀——高斯混合分布下的深度滤波器,显式地将内点与外点进行区别并进行概率建模,能够较好的处理外点数据。
从上面的讨论可以看出,存在着许多可能的改进方案。如果我们细致地改进每一步的做法,最后是有希望得到一个良好的稠密建图的方案的。然而,正如我们所讨论的,有一些问题存在理论上的困难,例如对环境纹理的依赖,例如像素梯度与极线方向的关联(以
及平行的情况)。这些问题很难通过调整代码实现来解决。所以,直到目前为止,尽管双目和移动单目能够建立稠密的地图,我们通常认为它们过于依赖于环境纹理和光照,不够可靠。
RGB-D 稠密建图
除了使用单目和双目进行稠密重建之外,在适用范围内,RGB-D 相机是一种更好的选择。在上一章中详细讨论的深度估计问题,在 RGB-D 相机中可以完全通过传感器中硬件测量得到,无需消耗大量的计算资源来估计它们。并且,RGB-D 的结构光或飞时原理,
保证了深度数据对纹理的无关性。即使面对纯色的物体,只要它能够反射光,我们就能测量到它的深度。这亦是 RGB-D 传感器的一大优势。
最直观最简单的方法,就是根据估算的相机位姿,将 RGB-D 数据转化为点云(Point Cloud),然后进行拼接,最后得到一个由离散的点组成的点云地图(Point Cloud Map)。在此基础上,如果我们对外观有进一步的要求,希望估计物体的表面,可以使用三角网格(Mesh),面片(Surfel)进行建图。另一方面,如果希望知道地图的障碍物信息并在地图上导航,亦可通过体素(Voxel)建立占据网格地图(Occupancy Map)。
点云地图
- 在生成每帧点云时,去掉深度值太大或无效的点。这主要是考虑到 Kinect 的有效量程,超过量程之后的深度值会有较大误差。
- 利用统计滤波器方法去除孤立点。该滤波器统计每个点与它最近 个点的距离值的分布,去除距离均值过大的点。这样,我们保留了那些“粘在一起”的点,去掉了孤立的噪声点。
- 最后,利用体素滤波器(Voxel Filter)进行降采样。由于多个视角存在视野重叠,在重叠区域会存在大量的位置十分相近的点。这会无益地占用许多内存空间。体素滤波保证在某个一定大小的立方体(或称体素)内仅有一个点,相当于对三维空间进行了
降采样,从而节省了很多存储空间。
不过,使用点云表达地图仍然是十分初级的,我们不妨按照之前提的对地图的需求,看看点云地图是否能满足:
- 定位需求:取决于前端视觉里程计的处理方式。如果是基于特征点的视觉里程计,由于点云中没有存储特征点信息,所以无法用于基于特征点的定位方法。如果前端是点云的 ICP,那么可以考虑将局部点云对全局点云进行 ICP 以估计位姿。然而,这要
求全局点云具有较好的精度。在我们这种处理点云的方式中,并没有对点云本身进行优化,所以是不够的。 - 导航与避障的需求:无法直接用于导航和避障。纯粹的点云无法表示“是否有障碍物”的信息,我们也无法在点云中做“任意空间点是否被占据”这样的查询,而这是导航和避障的基本需要。不过,可以在点云基础上进行加工,得到更适合导航与避障
的地图形式。 - 可视化和交互:具有基本的可视化与交互能力。我们能够看到场景的外观,也能在场景里漫游。从可视化角度来说,由于点云只含有离散的点,而没有物体表面信息(例如法线),所以不太符合人们对可视化习惯。例如,点云地图的物体从正面看和背面
看是一样的,而且还能透过物体看到它背后的东西:这些都不符合我们日常的经验,因为我们没有物体表面的信息。
综上所述,我们说点云地图是“基础”的或“初级的”,是指它更接近于传感器读取的原始数据。它具有一些基本的功能,但通常用于调试和基本的显示,不便直接用于应用程序。如果我们希望地图有更高级的功能,点云地图是一个不错的出发点。例如,针对导航
功能,我们可以从点云出发,构建占据网格地图(Occupancy Grid),以供导航算法查询某点是否可以通过。再如,SfM 中常用的泊松重建方法,就能通过基本的点云重建物体网格地图,得到物体的表面信息。除泊松重建之外,Surfel 亦是一种表达物体表面的方
式,以面元作为地图的基本单位,能够建立漂亮的可视化地图。
八叉树地图
我们知道,把三维空间建模为许多个小方块(或体素),是一种常见的做法。如果我们把一个小方块的每个面平均切成两片,那么这个小方块就会变成同样大小的八个小方块。这个步骤可以不断的重复,直到最后的方块大小达到建模的最高精度。在这个过程中,把“将一个小方块分成同样大小的八个”这件事,看成“从一个节点展开成八个子节点”,那么,整个从最大空间细分到最小空间的过程,就是一棵八叉树(Octo-tree)。

在于当某个方块的所有子节点都被占据或都不被占据时,就没必要展开这个节点。例如,一开始地图为空白时,我们就只需一个根节点,而不需要完整的树。当在地图中添加信息时,由于实际的物体经常连在一起,空白的地方也会常常连在一起,所以大多数八叉树节点都无需展开到叶子层面。所以说,八叉树比点云节省了大量的存储空间。
我们会选择用概率形式表达某节点是否被占据的事情。比方说,用一个浮点数 ![x\in [0,1]](https://private.codecogs.com/gif.latex?x%5Cin%20%5B0%2C1%5D) 来表达。这个 x 一开始取 0.5。如果不断观测到它被占据,那么让这个值不断增加;反之,如果不断观测到它是空白,那就让它不断减小即可。通过这种方式,我们动态地建模了地图中的障碍物信息。不过,现在的方式有一点小问题:如果让 x 不断增加或减小,它可能跑到 [0,1] 区间之外,带来处理上的不便。所以我们不是直接用概率来描述某节点被占据,而是用概率对数值(Log-odds)来描述。
来表达。这个 x 一开始取 0.5。如果不断观测到它被占据,那么让这个值不断增加;反之,如果不断观测到它是空白,那就让它不断减小即可。通过这种方式,我们动态地建模了地图中的障碍物信息。不过,现在的方式有一点小问题:如果让 x 不断增加或减小,它可能跑到 [0,1] 区间之外,带来处理上的不便。所以我们不是直接用概率来描述某节点被占据,而是用概率对数值(Log-odds)来描述。
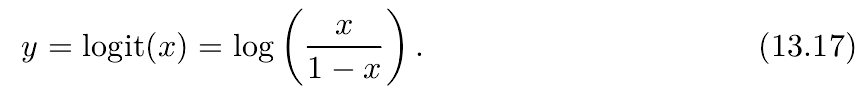
有了对数概率,我们就可以根据 RGB-D 数据,更新整个八叉树地图了。假设我们在RGB-D 图像中观测到某个像素带有深度 ,这说明了一件事:我们在深度值对应的空间点上观察到了一个占据数据,并且,从相机光心出发,到这个点的线段上,应该是没有物体
的(否则会被遮挡)。利用这个信息,可以很好地对八叉树地图进行更新,并且能处理运动的结构。
TSDF 地图和 Fusion 系列
在前面的地图模型中,我们的做法以定位为主体。地图的拼接,是作为后续加工步骤,放在 SLAM 框架中的。这种框架成为主流的原因,是因为定位算法可以满足实时性的需求,而地图的加工可以在关键帧处进行处理,无需实时响应。定位通常是轻量级的,特别是当我们使用稀疏特征或稀疏直接法的时候;相应的,地图的表达与存储则是重量级的。它们的规模和计算需求较大,不利于实时处理。特别是稠密地图,往往只能在关键帧层面进行计算。
但是,现有做法中,我们并没有对稠密地图进行优化。希望重建结果是光滑的、完整的,符合我们对地图的认识的。在这种思想下,出现了一种以“建图”为主体,而定位居于次要地位的做法,也就是本节想介绍的实时三维重建。由于三维重建把重建准确地图作为主要目标,所以基本都需要利用 GPU 进行加速,甚至需要非常高级的 GPU 或多个 GPU 进行并行加速,通常需要较重的计算设备。而相反的,SLAM 则是往轻量级、小型化方向发展,有些方案甚至放弃了建图和回环检测部分,只保留了视觉里程计。而实时重建的研究方向正在往大规模、大型动态场景的重建方向发展。
我们就以经典的 TSDF 地图为代表进行介绍。TSDF 是 Truncated Signed Distance Function 的缩写,不妨译作截断符号距离函数。虽然把“函数”称为“地图”似乎不太妥当,然而在没有更好的翻译之前,我们还是暂时称它为 TSDF 地图、TSDF 重建等等,只要不产生理解上的偏差即可。与八叉树相似,TSDF 地图也是一种网格式(或直观地说,方块式)的地图,先选定要建模的三维空间,按照一定分辨率,将这个空间分成许多小块,存储每个小块内部的信息。不同的是,TSDF 地图整个儿存储在 GPU 显存当中而不是内存中。利用 GPU 的并行特性,我们可以并行地对对每个体素进行计算和更新,而不像 CPU 遍历内存区域那样,不得不串行地进行。
每个 TSDF 体素内,存储了该小块与最近的物体表面的距离。如果小块在最近物体表面的前方,它就有一个正的值;反之,如果该小块位于表面之后,那么这个值就为负。由于物体表面通常是很薄的一层,所以就把值太大的和太小的都取成 1 和-1,这就得到了截
断之后距离,也就是所谓的 TSDF。那么按照定义,TSDF 为 0 的地方就是表面本身——或者,由于数值误差的存在,TSDF 由负号变成正号的地方就是表面本身。
TSDF 亦有“定位”与“建图”两个问题,与 SLAM 非常的相似,不过具体的形式与本书前面几章介绍的稍有不同。在这里,定位问题主要指如何把当前的 RGB-D 图像与 GPU 中的 TSDF 地图进行比较,估计相机位姿。而建图问题,就是如何根据估计的相机位姿,对 TSDF 地图进行更新。传统做法中,我们还会对 RGB-D 图像进行一次双边贝叶斯滤波,以去除深度图中的噪声。
TSDF 的定位类似于前面介绍的 ICP,不过由于 GPU 的并行化,我们可以对整张深度图和 TSDF 地图进行 ICP 的计算,而不必像传统视觉里程计那样必须先计算特征点。同时,由于 TSDF 没有颜色信息,意味着我们可以只使用深度图,不使用彩色图,就能完成
位姿估计,这在一定程度上摆脱了视觉里程计算法对光照和纹理的依赖性,使得 RGB-D 重建更加鲁棒。另一方面,建图部分亦是一种并行地对 TSDF 中的数值进行更新的过程,使得所估计的表面更加平滑可靠。
小结
本讲介绍了一些常见类型的地图,尤其是稠密地图形式。我们看到根据单目或双目可以构建稠密地图,而 RGB-D 地图则往往更加容易、稳定一些。本讲的地图偏重于度量地图,而拓扑地图形式,因为它和 SLAM 研究差别比较大,我们没有详细地展开探讨。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)