旅行商问题
旅行商问题(traveling salesman problem,TSP)可描述为:已知N个城市之间的相互距离,现有一个商人必须遍访这N个城市,并且每个城市只能访问一次,最后又必须返回出发城市。如何安排他对这些城市的访问次序,使其旅行路线总长度最短。
旅行商问题是一个典型的组合优化问题,其可能的路径数目是与城市数目N呈指数型增长的,一般很难精确地求出其最优解,因而寻找其有效的近似求解算法具有重要的理论意义,特别是当N的数目很大时,用常规的方法求解计算量太大。对庞大的搜索空间中寻求最优解,对于常规方法和现有的计算工具而言,存在着诸多的计算困难。使用遗传算法的搜索能力可以很容易地解决这类问题。另一方面,很多实际应用问题,经过简化处理后,均可化为旅行商问题,因而对旅行商问题求解方法的研究具有重要的应用价值。
遗传算法
遗传算法简称GA(genetic algorithms),是1962年由美国Michigan大学的Holland教授提出的模拟自然界遗传机制和生物进化论而成的一种并行随机搜索最优化方法。
遗传算法是以达尔文的自然选择学说为基础发展起来的。遗传算法将“优胜劣汰,适者生存”的生物进化原理引入优化参数形成的编码串联群体中,按所选择的适配值函数并通过遗传中的复制、交叉及变异对个体进行筛选,使适配值高的个体被保留下来,组成新的群体,新的群体既继承了上一代的信息,又优于上一代。这样周而复始,群体中个体适应度不断提高,直到满足一定的条件。遗传算法的算法简单,可并行处理,并能得到全局最优解。
遗传算法的基本操作分为5步:
1.复制
复制是从一个旧种群中选择生命力强的个体位串产生新种群的过程。根据位串的适配值复制,也就是指具有高适配值的位串更有可能在下一代中产生一个或多个子孙。它模仿了自然现象,应用了达尔文的适者生存理论。复制操作可以通过随机方法来实现。若用计算机程序来实现,可考虑首先产生0~1之间均匀分布的随机数,若某串的复制概率为40%,则当产生的随机数在0.40~1.0之间时,该串被复制,否则被淘汰。此外,还可以通过计算方法实现,其中较典型的几种方法为适应度比例法、期望值法、排位次法等。适应度比例法较常用。
2.交叉
复制操作能从旧种群中选择出优秀者,但不能创造新的染色体。而交叉模拟了生物进化过程中的繁殖现象,通过两个染色体的交换组合,来产生新的优良品种。它的过程为:在匹配池中任选两个染色体,随机选择一点或多点交换点位置﹔交换双亲染色体交换点右边的部分,即可得到两个新的染色体数字串。交换体现了自然界中信息交换的思想。交叉有一点交叉、多点交叉,还有一致交叉,顺序交叉和周期交叉。
3.变异
变异运算用来模拟生物在自然的遗传环境中由于各种偶然因素引起的基因突变,它以很小的概率随机地改变遗传基因(表示染色体的符号串的某一位)的值。在染色体以二进制编码的系统中,它随机地将染色体的某一个基因由1变为0,或由0变为1。若只有选择和交叉,而没有变异,则无法在初始基因组合以外的空间进行搜索,使进化过程在早期就陷入局部解而进入终止过程,从而影响解的质量。为了在尽可能大的空间中获得质量较高的优化解,必须采用变异操作。
对于一个需要进行优化的实际问题,一般可按下述步骤构造遗传算法:
- 第1步:确定决策变量及各种约束条件,即确定出个体的表现型和问题的解空间;
- 第⒉步:建立优化模型,即确定出目标函数的类型及数学描述形式或量化方法;
- 第3步:确定表示可行解的染色体编码方法,即确定出个体的基因型及遗传算法的搜索空间;
- 第4步:确定个体适应度的量化评价方法,即确定出由目标函数到个体适应度函数的转换规则;
- 第5步:设计遗传算子,即确定选择运算、交叉运算、变异运算等遗传算子的具体操作方法﹔
- 第6步:确定遗传算法的有关运行参数,即群体大小、进化代数、交叉概率和变异概率等参数;
- 第7步:确定解码方法,即确定出由个体表现型到个体基因型的对应关系或转换方法。

TSP问题编码
设D={dij}是由城市i和城市j之间的距离组成的距离矩阵,旅行商问题就是求出一条通过所有城市且每个城市只通过一次的具有最短距离的回路。
在旅行商问题的各种求解方法中,描述旅行路线的方法主要有如下两种:(1)巡回旅行路线经过的连接两个城市的路线的顺序排列;(2)巡回旅行路线所经过的各个城市的顺序排列。大多数求解旅行商问题的遗传算法是以后者为描述方法的,它们都采用所遍历城市的顺序来表示各个个体的编码串,其等位基因为N个整数值或N个记号.
以城市的遍历次序作为遗传算法的编码,目标函数取路径长度。在群体初始化、交叉操作和变异操作中考虑TSP问题的合法性约束条件(即对所有的城市做到不重不漏)
TSP问题的遗传算法设计
1.参数编码和初始群体设定
一般来说遗传算法对解空间的编码大多采用二进制编码形式,但对于TSP-类排序问题,采用对访问城市序列进行排列组合的方法编码,即某个巡回路径的染色体个体是该巡回路径的城市序列。
针对TSP问题,编码规则通常是取N进制编码,即每个基因仅从1到N的整数里面取一个值,
每个个体的长度为N,N为城市总数。
定义一个s行t列的pop矩阵来表示群体, t为城市个数+1,即N+1,s为样本中个体数目。
针对30个城市的TSP问题, t取值31,即矩阵每一行的前30个元素表示经过的城市编号,最后一个元素表示经过这些城市要走的距离。
参数编码和初始群体设定程序为:
pop=zeros(s,t);
for i=1:s
pop(i,1:t-1)=randperm(t-1);
end
2.适应度函数设计
在TSP的求解中,用距离的总和作为适应度函数,来衡量求解结果是否最优。将pop矩阵中每一行表示经过的距离的最后一个元素作为适应度函数。
两个城市m和n间的距离为:
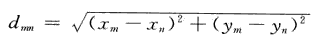
function [d]=juli(m,n)
x=[87 91 83 71 64 68 83 87 74 71 58 54 51 37 41 2 7 22 25 18 4 13 18 24 25 41 45 44 58 62];
y=[7 38 46 44 60 58 69 76 78 71 69 62 67 84 94 99 64 60 62 54 50 40 40 42 38 26 21 35 35 32];
%m=m+1;
%n=n+1;
d=sqrt((x(m)-x(n))^2+(y(m)-y(n))^2);
根据t的定义,两两城市组合数共有t一2组,则目标函数为:
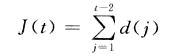
自适应度函数取目标函数的倒数,即:
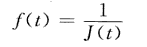
function [pop]=qiujuli(pop)
[s,t]=size(pop);
for i=1:1:s
dd=0;
for j=1:1:t-2
dd=dd+chap10_1calculate(pop(i,j),pop(i,j+1));
end
% dd=dd+ga_tsp_juli(pop(i,1),pop(i,t-1));
pop(i,t)=dd;
end
第三步:计算选择算子
选择就是从群体中选择优胜个体、淘汰劣质个体的操作,它是建立在群体中个体适应度评估基础上。仿真中采用最优保存方法,即将群体中适应度最大的c个个体直接替换适应度最小的c个个体。仿真中,取c=15。
function [pop]=select(pop,k)
[s,t]=size(pop);
m11=(pop(:,t));
%m11
m11=m11';
mmax=zeros(1,k);
mmin=zeros(1,k);
num=1;
while num<k+1
[a,mmax(num)]=max(m11);
m11(mmax(num))=0;
num=num+1;
end
num=1;
while num<k+1
[b,mmin(num)]=min(m11);
m11(mmin(num))=a;
num=num+1;
end
for i=1:k
pop(mmax(i),:)=pop(mmin(i),:);
end
第四步:计算交叉算子
交叉算子在遗传算法中起着核心的作用,它是指将个体进行两两配对,并以交叉概率p。将配对的父代个体加以替换重组而生成新个体的操作。仿真中,取p=0.90。
有序交叉法实现的步骤是:
- 随机选取两个交叉点crosspoint(1)和 crosspoint(2);
- 两后代先分别按对应位置复制双亲X1和X2匹配段中的两个子串A1和B1;
- 在对应位置交换双亲匹配段以外的城市,如果交换后,后代X1中的某一城市a与子串A1中的城市重复﹐则将该城市取代子串B1与Al中的城市a具有相同位置的新城市,直到与子串A1中的城市均不重复为止,对后代X2也采用同样方法

function [pop]=cross(pop)
[s,t]=size(pop);
pop1=pop;
for i=1:2:s
m=randperm(t-3)+1;
crosspoint(1)=min(m(1),m(2));
crosspoint(2)=max(m(1),m(2));
% middle=pop(i,crosspoint(1)+1:crosspoint(2));
% pop(i,crosspoint(1)+1:crosspoint(2))=pop(i+1,crosspoint(1)+1:crosspoint(2));
% pop(i+1,crosspoint(1)+1:crosspoint(2))=middle;
for j=1:crosspoint(1)
while find(pop(i,crosspoint(1)+1:crosspoint(2))==pop(i,j))
zhi=find(pop(i,crosspoint(1)+1:crosspoint(2))==pop(i,j));
y=pop(i+1,crosspoint(1)+zhi);
pop(i,j)=y;
end
end
for j=crosspoint(2)+1:t-1
while find(pop(i,crosspoint(1)+1:crosspoint(2))==pop(i,j))
zhi=find(pop(i,crosspoint(1)+1:crosspoint(2))==pop(i,j));
y=pop(i+1,crosspoint(1)+zhi);
pop(i,j)=y;
end
end
end
[pop]=chap10_1dis(pop);
for i=1:s
if pop1(i,t)<pop(i,t)
pop(i,:)=pop1(i,:);
end
end
第五步:计算变异算子
变异操作是以变异概率pm对群体中个体串某些基因位上的基因值作变动,若变异后子代的适应度值更加优异,则保留子代染色体,否则,仍保留父代染色体。仿真中,取pm=0.20。
这里采用倒置变异法:假设当前个体X为(1374 8 05 9 6 2),如果当前随机概率值小于pm,则随机选择来自同一-个体的两个点mutatepoint(1)和 mutatepoint(2),然后倒置该两点的中间部分,产生新的个体。
例如,假设随机选择个体X的两个点“7”和“9”,则倒置该两个点的中间部分,即将“4805”变为“5084”,产生新的个体X为(1 3 7 5 0 8 4 9 6 2)。
function [pop]=cross(pop)
[s,t]=size(pop);
pop1=pop;
for i=1:2:s
m=randperm(t-3)+1;
crosspoint(1)=min(m(1),m(2));
crosspoint(2)=max(m(1),m(2));
% middle=pop(i,crosspoint(1)+1:crosspoint(2));
% pop(i,crosspoint(1)+1:crosspoint(2))=pop(i+1,crosspoint(1)+1:crosspoint(2));
% pop(i+1,crosspoint(1)+1:crosspoint(2))=middle;
for j=1:crosspoint(1)
while find(pop(i,crosspoint(1)+1:crosspoint(2))==pop(i,j))
zhi=find(pop(i,crosspoint(1)+1:crosspoint(2))==pop(i,j));
y=pop(i+1,crosspoint(1)+zhi);
pop(i,j)=y;
end
end
for j=crosspoint(2)+1:t-1
while find(pop(i,crosspoint(1)+1:crosspoint(2))==pop(i,j))
zhi=find(pop(i,crosspoint(1)+1:crosspoint(2))==pop(i,j));
y=pop(i+1,crosspoint(1)+zhi);
pop(i,j)=y;
end
end
end
[pop]=chap10_1dis(pop);
for i=1:s
if pop1(i,t)<pop(i,t)
pop(i,:)=pop1(i,:);
end
end
第六步:主函数
在主函数将以上步骤串起来,这里用到了两个数据集,30和48城市的
clear all;
close all;
% t=31; %Number of Cities is t-1
t=49
s=500; %Number of Samples
pc=0.90;
pm=0.20;
pop=zeros(s,t);
for i=1:s
pop(i,1:t-1)=randperm(t-1);
end
for k=1:1:5000
if mod(k,10)==1
k
end
pop=chap10_1dis(pop);
c=15;
pop=chap10_1select(pop,c);
p=rand;
if p>=pc
pop=chap10_1cross(pop);
end
if p>=pm
pop=chap10_1mutate(pop);
end
end
pop
min(pop(:,t))
J=pop(:,t);
fi=1./J;
[Oderfi,Indexfi]=sort(fi); % Arranging fi small to bigger
BestS=pop(Indexfi(s),:); % Let BestS=E(m), m is the Indexfi belong to max(fi)
I=BestS;
% x=[87 91 83 71 64 68 83 87 74 71 58 54 51 37 41 2 7 22 25 18 4 13 18 24 25 41 45 44 58 62];
% y=[7 38 46 44 60 58 69 76 78 71 69 62 67 84 94 99 64 60 62 54 50 40 40 42 38 26 21 35 35 32];
%x=[87 58 91 83 62 71 64 68 83 87 74 71 58 54 51 37 41 2 7 22 25 18 4 13 18 24 25 41 45 44];
%y=[7 35 38 46 32 44 60 58 69 76 78 71 69 62 67 84 94 99 64 60 62 54 50 40 40 42 38 26 21 35];
att48=[1 6734 1453
2 2233 10
3 5530 1424
4 401 841
5 3082 1644
6 7608 4458
7 7573 3716
8 7265 1268
9 6898 1885
10 1112 2049
11 5468 2606
12 5989 2873
13 4706 2674
14 4612 2035
15 6347 2683
16 6107 669
17 7611 5184
18 7462 3590
19 7732 4723
20 5900 3561
21 4483 3369
22 6101 1110
23 5199 2182
24 1633 2809
25 4307 2322
26 675 1006
27 7555 4819
28 7541 3981
29 3177 756
30 7352 4506
31 7545 2801
32 3245 3305
33 6426 3173
34 4608 1198
35 23 2216
36 7248 3779
37 7762 4595
38 7392 2244
39 3484 2829
40 6271 2135
41 4985 140
42 1916 1569
43 7280 4899
44 7509 3239
45 10 2676
46 6807 2993
47 5185 3258
48 3023 1942
];
x=att48(1:end,2);
y=att48(1:end,3);
for i=1:1:t-1
x1(i)=x(I(i));
y1(i)=y(I(i));
end
x1(t)=x(I(1));
y1(t)=y(I(1));
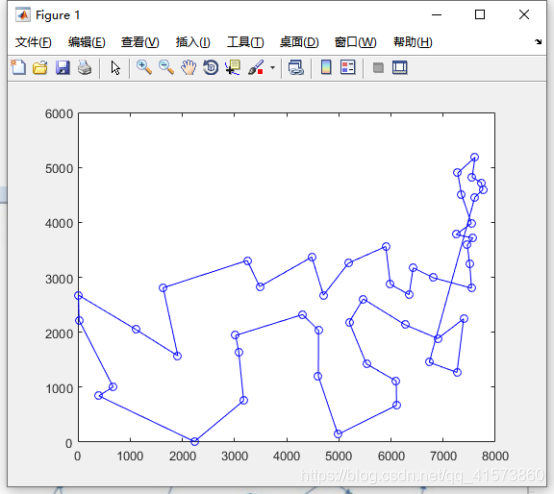
figure(1);
plot(x1,y1,'-ob');
运行结果
30个城市TSP:迭代100次,ans = 672.5364

30个城市TSP:迭代1000次,ans = 433.2609

30个城市TSP:迭代6000次,ans = 422.2395

48个城市TSP:迭代100次,ans = 5.0207e+04

48个城市TSP:迭代10000次,ans = 3.3533e+04(最优解长度:33522)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)