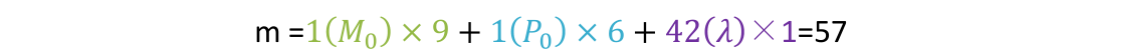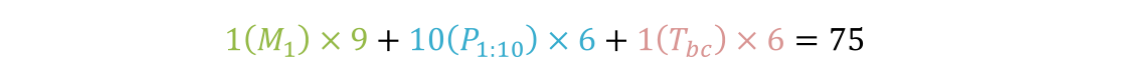目录
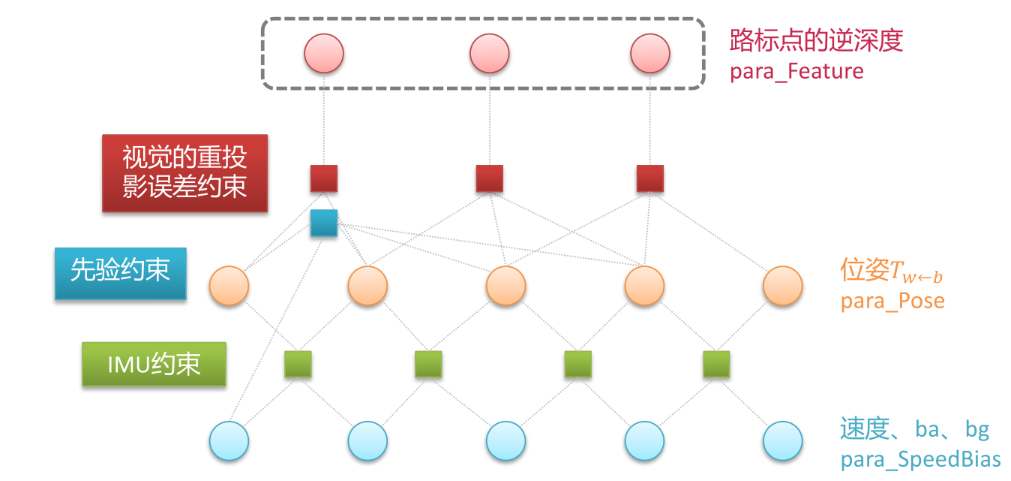
IMUFactor(imu约束) ProjectionTwoFrameOneCamFactor(视觉约束) marginalize(边缘化约束)
IMUFactor(imu约束)
将AddResidualBlock(imu_factor, NULL, para_Pose[i], para_SpeedBias[i], para_Pose[j], para_SpeedBias[j])中的传入参数提取出来,放到Pi Qi Vi Bai Bgi 和Pj Qj Vj Baj Bgj中。然后:
1、构建IMU残差residual:
residual = pre_integration- > evaluate ( Pi, Qi, Vi, Bai, Bgi,
Pj, Qj, Vj, Baj, Bgj) ;
由于预积分和ba bg有关,同时他们是优化量,每次计算后还需用bias的更新值来更新一下预积分的值:
重新积分太麻烦,假设预积分的变化量与 bias 是线性关系,直接这样更新:
Eigen:: Vector3d corrected_delta_v = delta_v + dv_dba * dba + dv_dbg * dbg;
Eigen:: Vector3d corrected_delta_p = delta_p + dp_dba * dba + dp_dbg * dbg;
其中,雅可比dv_dba等是从预积分时计算的雅可比得来 的(增量误差迭代公式 推导的大
J
J
J
J
J
J
Eigen:: Matrix3d dp_dbg = jacobian. block< 3 , 3 > ( O_P, O_BG) ;
Eigen:: Matrix3d dp_dba = jacobian. block< 3 , 3 > ( O_P, O_BA) ;
Eigen:: Matrix3d dq_dbg = jacobian. block< 3 , 3 > ( O_R, O_BG) ;
Eigen:: Matrix3d dv_dba = jacobian. block< 3 , 3 > ( O_V, O_BA) ;
Eigen:: Matrix3d dv_dbg = jacobian. block< 3 , 3 > ( O_V, O_BG) ;
residuals. block< 3 , 1 > ( O_P, 0 ) = Qi. inverse ( ) * ( 0.5 * G * sum_dt * sum_dt + Pj - Pi - Vi * sum_dt) - corrected_delta_p;
residuals. block< 3 , 1 > ( O_Q, 0 ) = 2 * ( corrected_delta_q. inverse ( ) * ( Qi. inverse ( ) * Qj) ) . vec ( ) ;
residuals. block< 3 , 1 > ( O_V, 0 ) = Qi. inverse ( ) * ( G * sum_dt + Vj - Vi) - corrected_delta_v;
residuals. block< 3 , 1 > ( O_BA, 0 ) = Baj - Bai;
residuals. block< 3 , 1 > ( O_BG, 0 ) = Bgj - Bgi;
return residuals;
分别是PQV Ba Bg:
2、残差的马氏距离:
IntegrationBase::evaluate()返回residual后,
其优化的最小二乘是马氏距离,使马氏距离最小。下图中,均值在红圈,红叉和绿叉到红圈的欧氏距离一样,但显然绿叉的偏离小,这就用到了协方差S和马氏距离d,(对尺度进行标准化,然后旋转轴去相关)。作用是:各个PVQ…误差不是独立的,存在相关性,不可等视,按照重要程度和相关性,来合理地得到最优位姿估计(不是简单的各个误差平方和最小时最优)
马氏距离
d
=
r
T
P
−
1
r
d=r^TP^{-1}r
d = r T P − 1 r
m
i
n
(
e
T
e
)
min(e^Te)
m i n ( e T e ) -1 分解成
L
T
L
L^TL
L T L
Eigen::Matrix<double, 15, 15> sqrt_info = Eigen::LLT...
residual = sqrt_info * residual;//最小二乘残差(比如残差为loss,最小二乘为|loss|^2,而ceres中只需要写上loss就行了)
3、残差的雅可比:
和残差计算中预积分更新类似,先从预积分时计算的大雅可比得到pqv对ba、bg的雅可比dv_dba等。
然后计算残差对各优化变量的雅可比:
对应代码中的
if ( jacobians[ 0 ] )
{
Eigen:: Map< Eigen:: Matrix< double , 15 , 7 , Eigen:: RowMajor>> jacobian_pose_i ( jacobians[ 0 ] ) ;
jacobian_pose_i. setZero ( ) ;
jacobian_pose_i. block< 3 , 3 > ( O_P, O_P) = - Qi. inverse ( ) . toRotationMatrix ( ) ;
jacobian_pose_i. block< 3 , 3 > ( O_P, O_R) = Utility:: skewSymmetric ( Qi. inverse ( ) * ( 0.5 * G * sum_dt * sum_dt + Pj - Pi - Vi * sum_dt) ) ;
Eigen:: Quaterniond corrected_delta_q = pre_integration- > delta_q * Utility:: deltaQ ( dq_dbg * ( Bgi - pre_integration- > linearized_bg) ) ;
jacobian_pose_i. block< 3 , 3 > ( O_R, O_R) = - ( Utility:: Qleft ( Qj. inverse ( ) * Qi) * Utility:: Qright ( corrected_delta_q) ) . bottomRightCorner< 3 , 3 > ( ) ;
jacobian_pose_i. block< 3 , 3 > ( O_V, O_R) = Utility:: skewSymmetric ( Qi. inverse ( ) * ( G * sum_dt + Vj - Vi) ) ;
jacobian_pose_i = sqrt_info * jacobian_pose_i;
}
然后
J
[
1
]
J
[
2
]
J
[
3
]
J[1] J[2] J[3]
J [ 1 ] J [ 2 ] J [ 3 ]
ProjectionTwoFrameOneCamFactor(视觉约束)
按传入的值初始化
Eigen::Vector3d pts_i, pts_j;//初始化为传入的_pts_i、_pts_j
Eigen::Vector3d velocity_i, velocity_j;//为(_velocity_i.x, _velocity_i.y, 0)
double td_i, td_j;//初始化为传入的_td_i、_td_j
构建视觉残差residual:Evaluate()
将AddResidualBlock()中的传入参数提取出来,放到Pi Qi 和Pj Qj ,外参tic qic,逆深度和td中
然后坐标系变换,由点在第一帧的归一化平面->世界系->第二帧的归一化平面
pts_i_td = pts_i - ( td - td_i) * velocity_i;
pts_j_td = pts_j - ( td - td_j) * velocity_j;
Eigen:: Vector3d pts_camera_i = pts_i_td / inv_dep_i;
Eigen:: Vector3d pts_imu_i = qic * pts_camera_i + tic;
Eigen:: Vector3d pts_w = Qi * pts_imu_i + Pi;
Eigen:: Vector3d pts_imu_j = Qj. inverse ( ) * ( pts_w - Pj) ;
Eigen:: Vector3d pts_camera_j = qic. inverse ( ) * ( pts_imu_j - tic) ;
double dep_j = pts_camera_j. z ( ) ;
residual = ( pts_camera_j / dep_j) . head< 2 > ( ) - pts_j_td. head< 2 > ( ) ;
residual = sqrt_info * residual;
雅可比:
因为残差P重投影 -P跟踪位置 不是简单的
[
x
,
y
,
z
]
[x, y,z]
[ x , y , z ]
[
x
,
y
,
z
]
[x, y,z]
[ x , y , z ]
后面那部分:重投影的
P
P
P
d
P
/
d
p
dP/dp
d P / d p 对应代码:
reduce << 1. / dep_j, 0 , - pts_camera_j ( 0 ) / ( dep_j * dep_j) ,
0 , 1. / dep_j, - pts_camera_j ( 1 ) / ( dep_j * dep_j) ;
reduce = sqrt_info * reduce;
if ( jacobians[ 0 ] )
{
Eigen:: Map< Eigen:: Matrix< double , 2 , 7 , Eigen:: RowMajor>> jacobian_pose_i ( jacobians[ 0 ] ) ;
Eigen:: Matrix< double , 3 , 6 > jaco_i;
jaco_i. leftCols< 3 > ( ) = ric. transpose ( ) * Rj. transpose ( ) ;
jaco_i. rightCols< 3 > ( ) = ric. transpose ( ) * Rj. transpose ( ) * Ri * - Utility:: skewSymmetric ( pts_imu_i) ;
jacobian_pose_i. leftCols< 6 > ( ) = reduce * jaco_i;
jacobian_pose_i. rightCols< 1 > ( ) . setZero ( ) ;
}
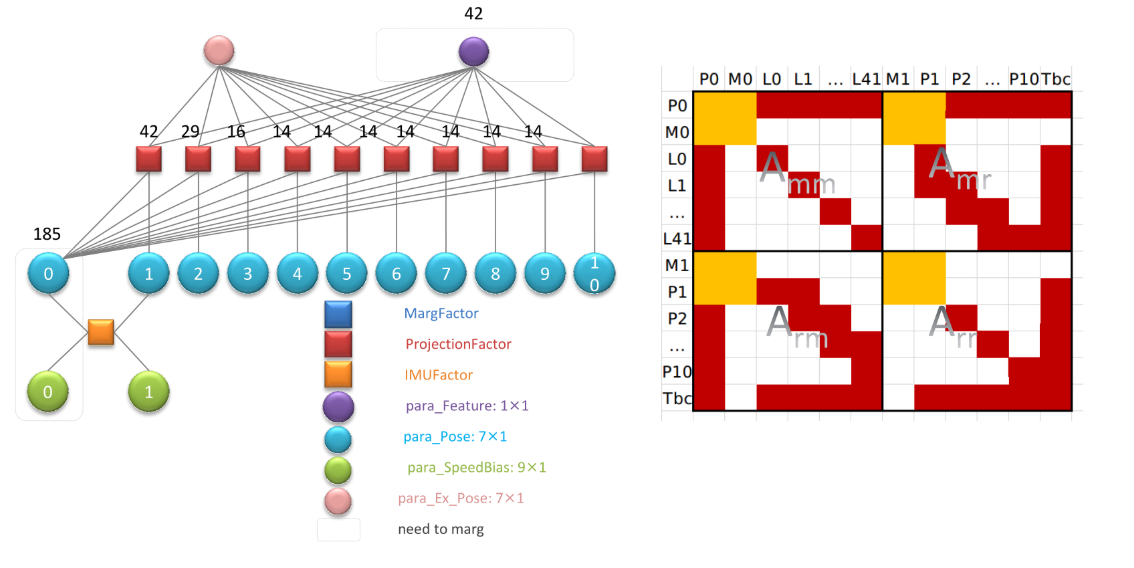
marginalize(边缘化约束)
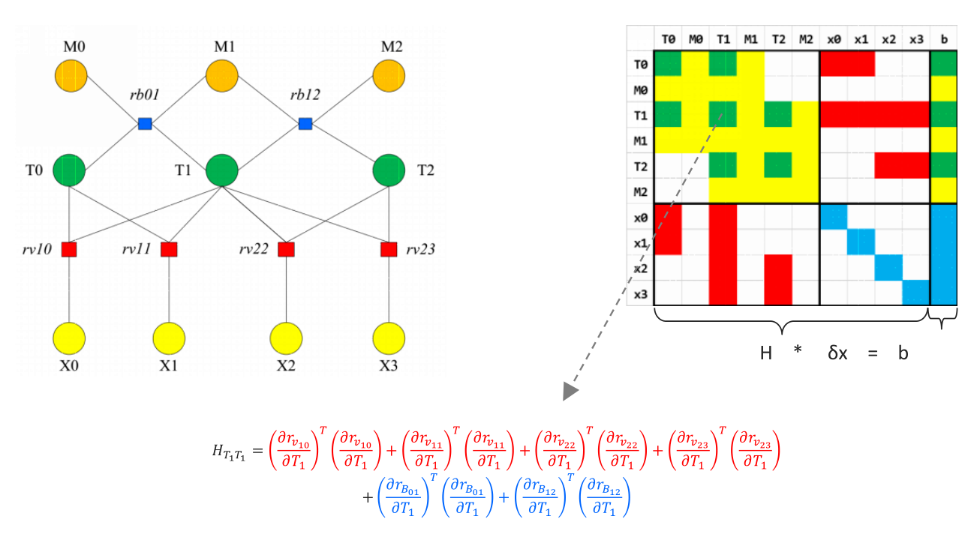
一、边缘化理解:
边缘化约束 :蓝色部分
边缘化
H
H
H
需要丢弃的约束(残差):第0帧的初速度、位姿、所有的视觉约束:
将与丢弃的帧相关的约束构造边缘化
H
H
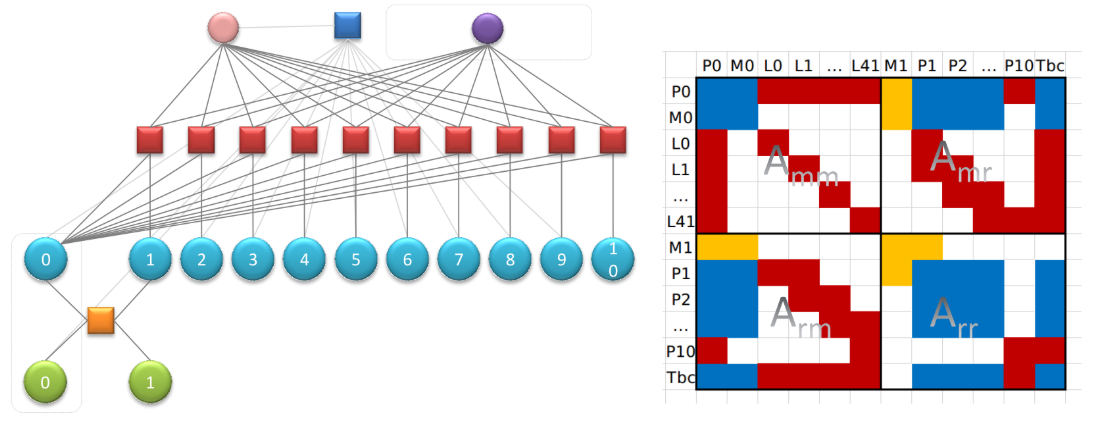
H ,利用舒尔补将丢弃的约束关系转移到保留的上,作为先验约束 (不同于残差的
H
H
H
H
H
H
A
r
r
A_{rr}
A r r 先验约束 ,在构建约束时加到残差
H
H
H 中:
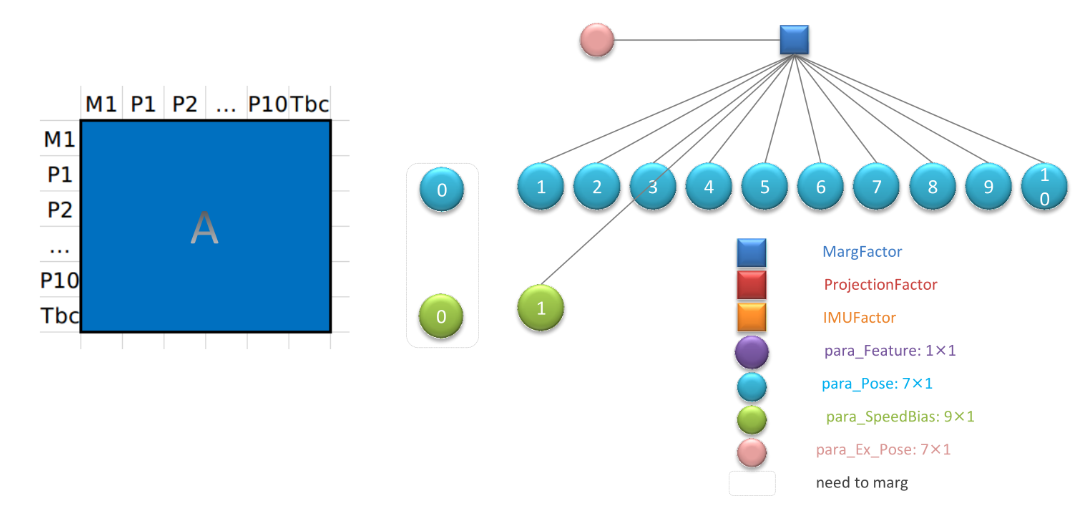
下次再构造边缘化的
H
H
H 的时候就把这个A拆进去,与要扔掉的视觉约束和imu约束一起进行下次舒尔补(下次M1—>M0…了)二、边缘化程序
1、提取要丢弃的变量和与之有关的约束,进行排序得到各个变量map<addr, data>:
if ( last_marginalization_parameter_blocks[ i] == para_Pose[ 0 ] || last_marginalization_parameter_blocks[ i] == para_SpeedBias[ 0 ] )
drop_set. push_back ( i) ;
marg的残差和雅可比
MarginalizationFactor * marg_factor = new MargFactor ( last_marginalization_info) ;
ResidualBlockInfo * residual_block_info = new ResidualBlockInfo ( marginalization_factor, NULL , last_marginalization_parameter_blocks,
drop_set) ;
marginalization_info- > addResidualBlockInfo ( residual_block_info) ;
IMUFactor* imu_factor = new IMUFactor ( pre_integrations[ 1 ] ) ;
ResidualBlockInfo * residual_block_info = new ResidualBlockInfo ( imu_factor, NULL , vector< double * > { para_Pose[ 0 ] , para_SpeedBias[ 0 ] , para_Pose[ 1 ] , para_SpeedBias[ 1 ] } ,
vector< int > { 0 , 1 } ) ;
marginalization_info- > addResidualBlockInfo ( residual_block_info) ;
for ( auto & it_per_id : f_manager. feature)
if ( it_per_id. start_frame != 0 )
continue ;
for ( auto & it_per_frame : it_per_id. feature_per_frame)
imu_j++ ;
ProjectionTwoFrameOneCamFactor * f_td = new ProjectionTwoFrameOneCamFactor ( pts_i, pts_j, it_per_id. feature_per_frame[ 0 ] . velocity, it_per_frame. velocity, it_per_id. feature_per_frame[ 0 ] . cur_td, it_per_frame. cur_td) ;
ResidualBlockInfo * residual_block_info = new ResidualBlockInfo ( f_td, loss_function, vector< double * > { para_Pose[ imu_i] , para_Pose[ imu_j] , para_Ex_Pose[ 0 ] , para_Feature[ feature_index] , para_Td[ 0 ] } ,
vector< int > { 0 , 3 } ) ;
marginalization_info- > addResidualBlockInfo ( residual_block_info) ;
前面三步的addResidualBlockInfo: (得到上表的一部分,最终在marginalize()得到)将不同损失函数对应的优化变量、边缘化位置存入到 parameter_block_sizes 和 parameter_block_idx 中
构建map,map的key就是他们的addr:(符号有的使用的PVQ或TV,示意图都是PM)
//parameter_block_size:变量维度,imu:[7,9,7,9](T0,V0,T1,V1);视觉[7,7,7,1](Ti,Tj,Tbc,λ)
for (int i = 0; i < residual_block_info->parameter_blocks.size(); i++)
{
double *addr = parameter_blocks[i];//指向数据的指针,也是作为map的key
int size = parameter_block_sizes[i];//地址指向的这个数据的长度
parameter_block_size[reinterpret_cast<long>(addr)] = size;//放进parameter_block_size
}
//parameter_block_idx:排序序号,要扔的不需要了,设成0,imu: [T0 V0];视觉[Ti,λ]
for (int i = 0; i < static_cast<int>(residual_block_info->drop_set.size()); i++)
{
double *addr = parameter_blocks[residual_block_info->drop_set[i]];//变量的id
parameter_block_idx[reinterpret_cast<long>(addr)] = 0;//id存入parameter_block_idx
}
如视觉中,每次传入一个约束parameter_block_size就产生下图这么一块。然后有很多约束,就有跟多块最终组成最初的表。
2、preMarginalize() :
得到每次IMU和视觉观测对应的参数块,雅克比矩阵,残差值。在这里调用了各自的Evaluate()计算残差和雅克比矩阵。结果的地址赋值parameter_block_data
it->Evaluate();//分别计算所有状态变量构成的残差和雅克比矩阵,其实就是调用各个损失函数中的重载函数Evaluate()
std::vector<int> block_sizes = it->cost_function->parameter_block_sizes();
long addr = reinterpret_cast<long>(it->parameter_blocks[i]);//优化变量的地址
memcpy(data, it->parameter_blocks[i], sizeof(double) * size);//重新开辟一块内存
parameter_block_data[addr] = data;//变量约束的地址parameter_block_data
3、 marginalize()
对参数块变量进行排序,待marg的参数块变量放在前面,其他参数块变量放在后面,并将每个参数块的对应的下标放在parameter_block_idx for (const auto &it : parameter_block_size)
{
// 大小累加作为pos
parameter_block_idx[it.first] = pos;//就将这个待marg的变量id设为pos
pos += localSize(it.second);//pos加上这个变量的长度
}
通过上面的操作就会将所有的优化变量进行一个伪排序,待marg的优化变量的idx为0,其他所在的位置相关,最终得到最初的排列。
多线程构造各个残差对应的各个优化变量的信息矩阵,然后在加起来 Eigen::MatrixXd A(pos, pos);//整个矩阵H的大小(Hx=b)
Eigen::VectorXd b(pos);
ThreadsConstructA()//分别构造H矩阵
if (i == j)
p->A.block(idx_i, idx_j, size_i, size_j) += jacobian_i.transpose() * jacobian_j;
else
{
p->A.block(idx_i, idx_j, size_i, size_j) += jacobian_i.transpose() * jacobian_j;
p->A.block(idx_j, idx_i, size_j, size_i) = p->A.block(idx_i, idx_j, size_i, size_j).transpose();
}
//舒尔补的4个分块
Eigen::MatrixXd Amm = A.block(0, 0, m, m)//求逆Amm_inv
Eigen::VectorXd bmm = b.segment(0, m);
Eigen::MatrixXd Amr = A.block(0, m, m, n);
Eigen::MatrixXd Arm = A.block(m, 0, n, m);
Eigen::MatrixXd Arr = A.block(m, m, n, n);
Eigen::VectorXd brr = b.segment(m, n);
//新的矩阵H* b*
A = Arr - Arm * Amm_inv * Amr;
b = brr - Arm * Amm_inv * bmm;
从
H
∗
H^*
H ∗
b
∗
b^ *
b ∗
J
T
J
J^TJ
J T J linearized_jacobians、_residuals linearized_jacobians = S_sqrt * saes2.eigenvectors().transpose();
linearized_residuals = S_inv_sqrt * saes2.eigenvectors().transpose() * b;
A
=
J
T
J
=
V
S
V
=
V
S
S
V
>
>
>
J
=
S
V
A=J^TJ=VSV=V\sqrt{S}\sqrt{S}V >>> J=\sqrt{S}V
A = J T J = V S V = V S
S
V > > > J = S
V
b
=
J
T
f
>
>
>
f
=
(
J
T
)
−
1
b
=
S
−
1
V
b
b=J^Tf >>> f=(J^T)^{-1}b=\sqrt{S}^{-1}Vb
b = J T f > > > f = ( J T ) − 1 b = S
− 1 V b
J
J
J
H
H
H
H
H
H
b
b
b
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)