最近看了一篇论文,很是头大,大概看懂了个所以然。记录一下。
论文:Monocular Visual–Inertial State Estimation With Online Initialization and Camera–IMU Extrinsic Calibration
作者:Zhenfei Yang, Shaojie Shen.
背景知识
VIO初始化:https://blog.csdn.net/shyjhyp11/article/details/115403769

论文的简要概括:
- 首先采用手眼标定的思想,估计外参的旋转;
- 已知旋转,忽略bias的变化,同时标定:速度、重力方向、特征点深度、平移;
- 进一步精细优化;
- 采用一种边缘化策略,保证滑窗大小和信息保留。
论文详细解释
IMU积分、预积分等相关内容
公式(1):IMU的直接积分
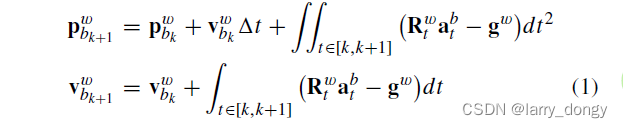
公式(2):加速度项产生的位置变化
α
\alpha
α,速度变化
β
\beta
β,角速度产生的角度变化
R
b
k
+
1
b
k
R_{b_{k+1}}^{b_k}
Rbk+1bk
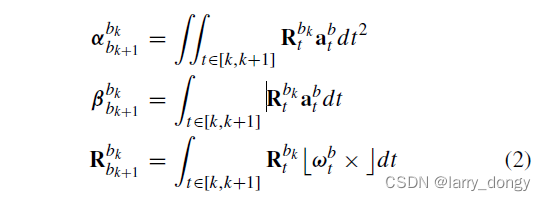
公式(3):(1)的重写
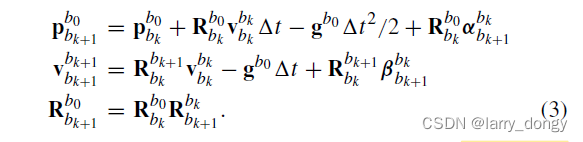
目标
估计所需要的状态量:所有IMU时刻的平移、速度、重力方向
x
k
x_k
xk,以及相机和IMU外参
p
c
b
p_c^b
pcb,以及特征点的深度信息
λ
\lambda
λ
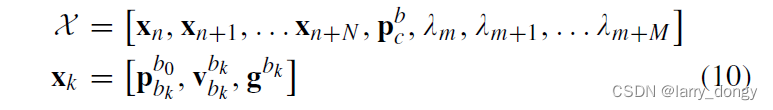
旋转量估计
估计前首先通过视觉建立了一个初步的地图,因此可以通过特征匹配结果,得到两帧间 Camera 的旋转量;
再通过 IMU 的积分得到IMU的旋转量(由于时间较短,忽略了bias等变换)
此时就是求解公式(4):这是一个手眼标定的基本公式,解法也相对简单,看论文即可。另外,加了一项根据旋转估值误差的权重,Huber norm。
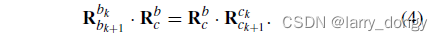
速度、重力方向、特征点深度、相机IMU平移 估计
核心公式(11):第一项是先验项的约束,第二项是IMU的,第三项是相机的。下面展开介绍。
首先在之前,作者假设,下面所有的旋转量都是已知的,包括camera和imu的旋转(上面已计算),和imu在不同时刻间的旋转(公式2、3提供)。
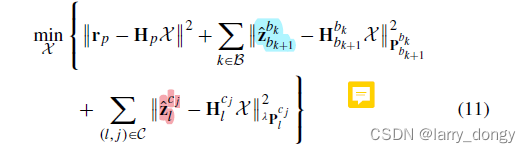
这部分内容其实写的有点乱,真的搞了半天才大概理解在干嘛。首先看相机的误差项:(17)(18)

(17)中的 0 表达的很奇怪。但看后面的可以理解作者想表达的意思。
首先对于在
c
i
c_i
ci 帧首次观测到的特征点
l
l
l,它被
c
j
c_j
cj这一帧观测到了,此时建立一个约束。通过赋予深度
λ
l
\lambda_l
λl,从camera转到base(IMU)下,在通过IMU一系列的积分求得的旋转增量得到 j 时刻的IMU位姿,再转换回camera系。此时,应该和
c
j
c_j
cj 下观测到的是一致的,那么这里的
M
M
M 就是用于构建视觉误差。
理论上如果外参(的平移量)和深度(
λ
\lambda
λ)计算正确,(17)这个式子应该为0。这就是(17)想表达的含义。那么我们让这个式子等于0,就能求出来准确的平移量和深度!
基于这个思想,再看IMU项:式(12)

式(12)是约束了:速度项和重力方向。
(12)的第三行,旧的重力方向经过旋转后,应该新的一致,误差为0,因此约束了重力的attitude。
第二行和第一行,同时约束了速度项。
因此,最小化(12)即可求出速度和重力方向。
但是(11)还有两个东西没有提到,一个是状态量
X
X
X 前面的
H
H
H,还有右下角的
P
P
P 矩阵。
论文中没有显示的给出
H
H
H 的形式,但可以根据式(10)自己写出来吧。
右下角的
P
P
P,是协方差矩阵,根据IMU的噪声和相机成像的噪声,得到。详见论文。
式(12)的求解
作者指出,式(12)可以写成式(21)的形式,直接解析求解,而不需要迭代。这里就需要涉及上面提到的
H
H
H 了。

进一步细化
上述的求解,只是一些粗糙的计算,例如忽略了误差传递等。此时要优化的是式(28)
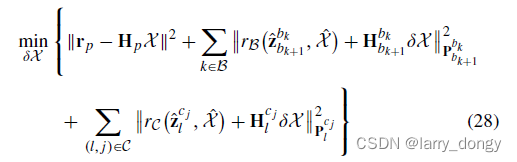
后面就忽略了吧,就看不懂了……
后记
哎,IMU这部分硬着头皮啃吧,之前多少年都不想深究,还是绕不开。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)