DataFrame使用笔记
dates=pd.date_range('20160728',periods=6)
df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
df2=pd.DataFrame({'A':pd.Timestamp('20160728'),'B':pd.Series(1)})
df2.dtypes
df2.head() df2.tail(5)
df.columns df.value
df.describe()
df.T df.sort(columns='C')
df['A'] df[1:3]
df.loc[:,['A','B']]
df.loc['20160728':'20160730',['A','B']]
df.at[dates[0],'A']
df.iloc[3] df.iloc[1,1]
df.iloc[3:5,0:2]
df.iloc[[1,2,4],[0,2]]
df.iat[1,1]
df[(df.D>0)&(df.C<0)]
df[['A','B']][(df.D>0)&(df.C<0)]
df['D'].isin(alist)
os.getcwd()
df=pd.read_csv('',encoding='gbk',sep=',')
counts=df[u'专业名称'].value_counts()
plt=counts.plot(kind='bar').get_figure()
plt.savefig('d/plot.png')
good=df[df[u'高考分数']>520]
good_counts=good[u'专业名称'].value_counts()
per=good_counts/counts
df.groupby('A').first()
df.groupby(['A','B'])
def get_type(letter):
if letter.lower() in 'abem':
return 'v'
else:
return 'w'
grouped=df.groupby(get_type,axis=1)
import pandas.util.testing as tm
colors=tm.choice(['red','green'],size=10)
foods=tm.choice(['eggs','ham'],size=10)
index=pd.MultiIndex.from.arrays([colors,foods],names=['color','food'])
df.pd.DataFrame(np.random.randn(10,2),index=index)
print df.query('color=="red"')
grouped=df.groupby(level='food')
df.index.names=[None,None]
print df.query('ilevel_0=="red"')
grouped=df.groupby(level=1)
grouped.aggregate(np.sum)
print grouped.aggregate(np.sum).reset_index()
df.groupby(level=['color'],as_index=False).sum()
print grouped.size()
print grouped.discribe()
import pandas as pd
import numpy as np
index=pd.date_range('20140101',periods=100)
ts=pd.Series(np.random.normal(0.5,2,100),index)
print ts.head()
key=lambda x:x.month
zscore=lambda x:(x-x.mean())/x.std()
transformed=ts.groupby(key).transform(zscore)
print type(transformed)
print transformed.groupby(key).mean()
print transformed.groupby(key).std()
grouped=df.groupby(level='color').agg(['SUM':np.sum,'MEAN':np.mean,'STD':np.std])
print grouped['a'].agg({'lambda':lambda x:np.mean(abs(x))})
key =lambda x:x.month
grouped=ts.groupby(key).agg({'SUM':np.sum,'MEAN':np.mean,'STD':np.std})
print grouped
df.groupby(df['date'].apply(lambda x:x.month)).first()
df.set_index('date')
date_string =('2010-09-01','2020-01-01')
a=pd.Series([pd.to_datetime(date) for date in date_string])
df['c']=pd.Series(np.random.randn(10),index=df.index)
df.insert(1,'e',df['a'])
del df['c']
df2=df.drop(['a','b'],axis=1)
b=df.pop('b')
df.insert(0,'b',b)
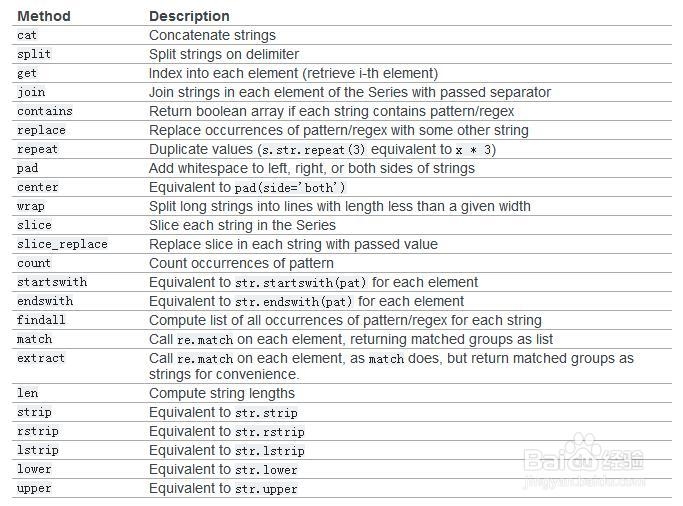
s=pd.Series(list('ABCDEF')
s.str.lower()
s.str.upper()
s.str.len()
s.str.split('_').str.get(1)
s.str.replace('^a|b$','X',case=False)
s=pd.Series(['a1','a2','b1','b2',c])
s.str.extract('([ab])(\d)?')
s.str.extract('(?P<letter>[abc])(?P<digit>\d)')
pattern=r'[a-z][0-9]'
print s.str.contains(pattern,na=False)
s.str.match(pattern,as_index=False)
s.str.endswith('l',na=False)
s.str.startwith('l',na=False)
import MySQLdb
con=MySQLdb.connect(host="localhost",db="")
sql="SELECT * FROM..."
df=pd.read_sql(sql,con,index_col='id')
con2=execute('DROP TABLE IF EXISTS wheather')
pd.io.sql.write_frame(df,"wheather",con2)
df=pd.DataFrame(np.random.randn(5,3),index=list('abcde'),columns=['one','two','three'])
df.ix[1,:-1]=np.nan
df.fillna(0)
df.fillna(method='pad')
df.fillna(method='bfill',limit=1)
df.fillna(df.mean()['one':'two'])
df.dropna(axis=0)
df.interpolate()
df.replace({1:11,2:12})
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)