python_imbalanced-learn非平衡学习包_01_简介
python_imbalanced-learn非平衡学习包_02_Over-sampling过采样
后续章节待定_希望各位认可前面已更_您的认可是我的动力
Over-sampling
1. A practical guide
You can refer to Compare over-sampling samplers
实用指南
您可以参考比较过采样采样器
1.1 Naive random over-sampling
One way to fight this issue is to generate new samples in the classes which are under-represented. The most naive strategy is to generate new samples by randomly sampling with replacement the current available samples. The RandomOverSampler offers such scheme:
网址
朴素随机过抽样
解决此问题的一种方法是对表示不足的类生成新样本。最简单的策略是通过随机抽样生成新样本,替换当前可用样本。RandomOverSampler提供了这样的方案:
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=3,
n_clusters_per_class=1,
weights=[0.01, 0.05, 0.94],
class_sep=0.8, random_state=0)
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
from collections import Counter
print(sorted(Counter(y_resampled).items()))
[(0, 4674), (1, 4674), (2, 4674)]
The augmented data set should be used instead of the original data set to train a classifier:
应使用扩充数据集代替原始数据集来训练分类器:
from sklearn.svm import LinearSVC
clf = LinearSVC()
clf.fit(X_resampled, y_resampled)
LinearSVC()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In the figure below, we compare the decision functions of a classifier trained using the over-sampled data set and the original data set.
在下图中,我们比较了使用过采样数据集和原始数据集训练的分类器的决策函数。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DuSnYq0s-1653184586363)(attachment:image.png)]](https://img-blog.csdnimg.cn/6a809a711daf4d5ca9bc337e2d56a14f.png)
It would also work with pandas dataframe:
它还可以与pandas dataframe数据帧配合使用
from sklearn.datasets import fetch_openml
df_adult, y_adult = fetch_openml(
'adult', version=2, as_frame=True, return_X_y=True)
df_adult.head()
| age | workclass | fnlwgt | education | education-num | marital-status | occupation | relationship | race | sex | capital-gain | capital-loss | hours-per-week | native-country |
|---|
| 0 | 25.0 | Private | 226802.0 | 11th | 7.0 | Never-married | Machine-op-inspct | Own-child | Black | Male | 0.0 | 0.0 | 40.0 | United-States |
|---|
| 1 | 38.0 | Private | 89814.0 | HS-grad | 9.0 | Married-civ-spouse | Farming-fishing | Husband | White | Male | 0.0 | 0.0 | 50.0 | United-States |
|---|
| 2 | 28.0 | Local-gov | 336951.0 | Assoc-acdm | 12.0 | Married-civ-spouse | Protective-serv | Husband | White | Male | 0.0 | 0.0 | 40.0 | United-States |
|---|
| 3 | 44.0 | Private | 160323.0 | Some-college | 10.0 | Married-civ-spouse | Machine-op-inspct | Husband | Black | Male | 7688.0 | 0.0 | 40.0 | United-States |
|---|
| 4 | 18.0 | NaN | 103497.0 | Some-college | 10.0 | Never-married | NaN | Own-child | White | Female | 0.0 | 0.0 | 30.0 | United-States |
|---|
type(df_adult)
pandas.core.frame.DataFrame
df_resampled, y_resampled = ros.fit_resample(df_adult, y_adult)
df_resampled.head()
| age | workclass | fnlwgt | education | education-num | marital-status | occupation | relationship | race | sex | capital-gain | capital-loss | hours-per-week | native-country |
|---|
| 0 | 25.0 | Private | 226802.0 | 11th | 7.0 | Never-married | Machine-op-inspct | Own-child | Black | Male | 0.0 | 0.0 | 40.0 | United-States |
|---|
| 1 | 38.0 | Private | 89814.0 | HS-grad | 9.0 | Married-civ-spouse | Farming-fishing | Husband | White | Male | 0.0 | 0.0 | 50.0 | United-States |
|---|
| 2 | 28.0 | Local-gov | 336951.0 | Assoc-acdm | 12.0 | Married-civ-spouse | Protective-serv | Husband | White | Male | 0.0 | 0.0 | 40.0 | United-States |
|---|
| 3 | 44.0 | Private | 160323.0 | Some-college | 10.0 | Married-civ-spouse | Machine-op-inspct | Husband | Black | Male | 7688.0 | 0.0 | 40.0 | United-States |
|---|
| 4 | 18.0 | NaN | 103497.0 | Some-college | 10.0 | Never-married | NaN | Own-child | White | Female | 0.0 | 0.0 | 30.0 | United-States |
|---|
If repeating samples is an issue, the parameter shrinkage allows to create a smoothed bootstrap. However, the original data needs to be numerical. The shrinkage parameter controls the dispersion of the new generated samples. We show an example illustrate that the new samples are not overlapping anymore once using a smoothed bootstrap. This ways of generating smoothed bootstrap is also known a Random Over-Sampling Examples (ROSE) [MT14].
如果重复采样是一个问题,那么参数shrinkage(收缩)允许创建平滑的自我提升样本,然而,原始数据需要是数字。“shrinkage(收缩)”参数控制新生成样本的分散。我们给出了一个示例,说明使用平滑引导后,新样本不再重叠。这种生成平滑自我提升样本的方法也被称为随机过采样示例(ROSE)[MT14]。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-elqDuDrd-1653184586366)(attachment:image.png)]](https://img-blog.csdnimg.cn/69e96f288ee94a9297bfdb172b5247ae.png)
1.2 From random over-sampling to SMOTE and ADASYN
Apart from the random sampling with replacement, there are two popular methods to over-sample minority.classes: (i) the Synthetic Minority Oversampling Technique (SMOTE) [CBHK02] and (ii) the Adaptive Synthetic (ADASYN) [HBGL08] sampling method. These algorithms can be used in the same manner:
网址
除了随机抽样替换外,还有两种常用的方法对少数群体进行过采样,方式(i)合成少数过采样技术(SMOTE)[CBHK02]和(ii)自适应合成(ADASYN)[HBGL08]采样方法。这些算法可以以相同的方式使用:
from imblearn.over_sampling import SMOTE, ADASYN
X_resampled, y_resampled = SMOTE().fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
clf_smote = LinearSVC().fit(X_resampled, y_resampled)
X_resampled, y_resampled = ADASYN().fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
clf_adasyn = LinearSVC().fit(X_resampled, y_resampled)
[(0, 4674), (1, 4674), (2, 4674)]
[(0, 4673), (1, 4662), (2, 4674)]
The figure below illustrates the major difference of the different over-sampling methods.
下图说明了不同过采样方法的主要区别。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rUNglgUQ-1653184586368)(attachment:image.png)]](https://img-blog.csdnimg.cn/e5049592ab014487b79c31b1b81bd4ed.png)
1.3. Ill-posed examples
While the RandomOverSampler is over-sampling by duplicating some of the original samples of the minority class, SMOTE and ADASYN generate new samples in by interpolation. However, the samples used to interpolate/generate new synthetic samples differ. In fact, ADASYN focuses on generating samples next to the original samples which are wrongly classified using a k-Nearest Neighbors classifier while the basic implementation of SMOTE will not make any distinction between easy and hard samples to be classified using the nearest neighbors rule. Therefore, the decision function found during training will be different among the algorithms.
虽然RandomOverSampler是通过复制少数群体的一些原始样本进行过度采样,SMOTE和ADASYN通过插值生成新样本。但是,用于插值/生成新合成样本的样本不同。
事实上,ADASYN专注于在分类器错误分类的原始样旁边使用k-最近邻生成样本,而SMOTE的基本实现使用最近邻规则时不会区分容易分类样本和难以分类样本。因此,在训练过程中发现决策函数在不同的算法中会有所不同。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4uBrp4sT-1653184586370)(attachment:image.png)]](https://img-blog.csdnimg.cn/76970a5185bd48cd9f62306c5f23a4e6.png)
The sampling particularities of these two algorithms can lead to some peculiar behavior as shown below.
这两种算法的采样特性可能导致某些特殊行为,如下所示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L6XONAM6-1653184586370)(attachment:image.png)]](https://img-blog.csdnimg.cn/91dc64f002024b2fa9df0a73f2edbe2a.png)
1.4 SMOTE variants|
SMOTE might connect inliers and outliers while ADASYN might focus solely on outliers which, in both cases, might lead to a sub-optimal decision function. In this regard, SMOTE offers three additional options to generate samples. Those methods focus on samples near the border of the optimal decision function and will generate samples in the opposite direction of the nearest neighbors class. Those variants are presented in the figure below.
SMOTE 变形
SMOTE可能会连接内联点和离群点,而ADASYN可能只关注离群点,这两种情况下都可能导致次优决策函数。在这方面,SMOTE提供了三个额外的选项来生成样本。
这些方法侧重于最优决策函数边界附近的样本,并将在最近邻类的相反方向生成样本。这些变体如下图所示。
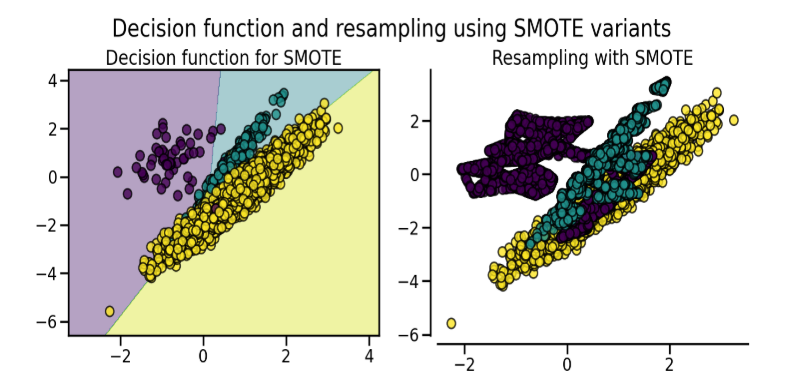
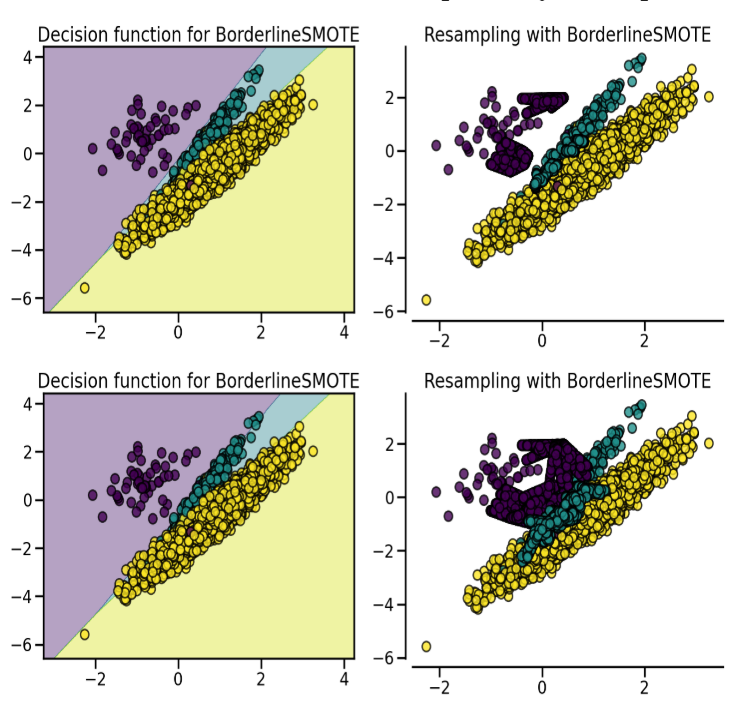
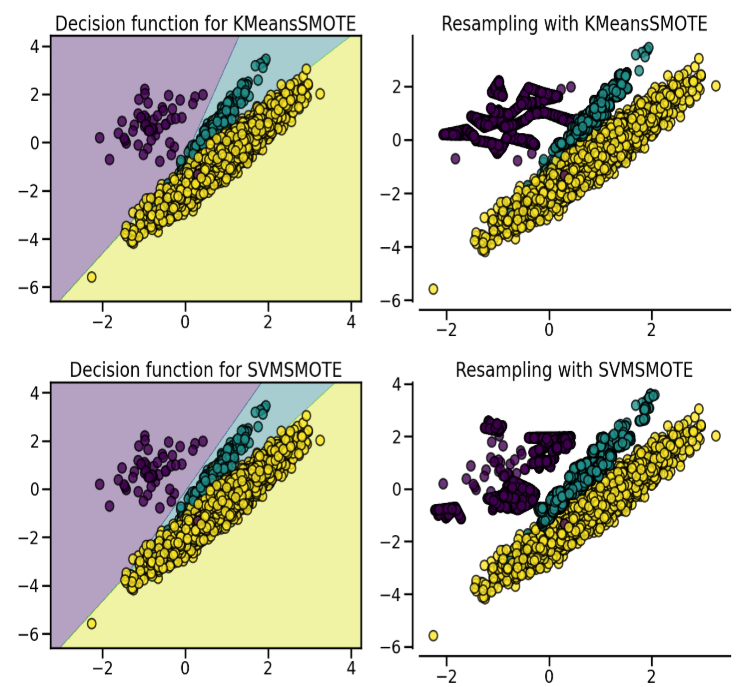
The BorderlineSMOTE [HWM05], SVMSMOTE [NCK09], and KMeansSMOTE [LDB17] offer some variant of the SMOTE algorithm:
BorderlineSMOTE[HWM05]、SVMSote[NCK09]和KMeansSMOTE[LDB17]提供了SMOTE算法的一些变体:
from imblearn.over_sampling import BorderlineSMOTE
X_resampled, y_resampled = BorderlineSMOTE().fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
[(0, 4674), (1, 4674), (2, 4674)]
When dealing with mixed data type such as continuous and categorical features, none of the presented methods (apart of the class RandomOverSampler) can deal with the categorical features. The SMOTENC [CBHK02] is an extension of the SMOTE algorithm for which categorical data are treated differently:
当处理连续和分类特征等混合数据类型时,所提出的方法(除了类RandomOverSampler)都不能处理分类特征。SMOTENC[CBHK02]是SMOTE算法的扩展专门用来处理类别特征:
import numpy as np
rng = np.random.RandomState(42)
n_samples = 50
X = np.empty((n_samples, 3), dtype=object)
X[:, 0] = rng.choice(['A', 'B', 'C'], size=n_samples).astype(object)
X[:, 1] = rng.randn(n_samples)
X[:, 2] = rng.randint(3, size=n_samples)
y = np.array([0] * 20 + [1] * 30)
print(sorted(Counter(y).items()))
[(0, 20), (1, 30)]
In this data set, the first and last features are considered as categorical features. One need to provide this information to SMOTENC via the parameters categorical_features either by passing the indices of these features or a boolean mask marking these features:
在此数据集中,第一个和最后一个特征被视为分类特征。需要通过参数categorical_features向SMOTENC提供此信息,或者通过传递这些特性的索引或用布尔掩码标记这些特性:
from imblearn.over_sampling import SMOTENC
smote_nc = SMOTENC(categorical_features=[0, 2], random_state=0)
X_resampled, y_resampled = smote_nc.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
print(X_resampled[-5:])
[(0, 30), (1, 30)]
[['A' 0.5246469549655818 2]
['B' -0.3657680728116921 2]
['B' 0.9344237230779993 2]
['B' 0.3710891618824609 2]
['B' 0.3327240726719727 2]]
Therefore, it can be seen that the samples generated in the first and last columns are belonging to the same categories originally presented without any other extra interpolation.
However, SMOTENC is only working when data is a mixed of numerical and categorical features. If data are made of only categorical data, one can use the SMOTEN variant [CBHK02]. The algorithm changes in two ways:
1.the nearest neighbors search does not rely on the Euclidean distance. Indeed, the value difference metric (VDM) also implemented in the class ValueDifferenceMetric is used.
2.a new sample is generated where each feature value corresponds to the most common category seen in the neighbors samples belonging to the same class.
因此,可以看出,在第一列和最后一列中生成的样本与最初显示的类别相同,没有任何其他额外的插值。
然而,SMOTENC只有在数据混合了数字和分类特征时才起作用。如果数据仅由分类数据构成,则可以使用SMOTEN变量[CBHK02]。算法有两处变化:
1.最近邻搜索不依赖于欧几里德距离。实际上,ValueDifferenceMetric类中实现的值差度量(VDM)则会被使用。
2.生成新样本的每个特征值对应于属于同一类的相邻样本中最常见的类别。
Let’s take the following example:
我们以以下例子为例
import numpy as np
X = np.array(["green"] * 5 + ["red"] * 10 + ["blue"] * 7,
dtype=object).reshape(-1, 1)
y = np.array(["apple"] * 5 + ["not apple"] * 3 + ["apple"] * 7 +
["not apple"] * 5 + ["apple"] * 2, dtype=object)
from imblearn.over_sampling import SMOTEN
sampler = SMOTEN(random_state=0)
X_res, y_res = sampler.fit_resample(X, y)
X_res[y.size:]
y_res[y.size:]
array(['not apple', 'not apple', 'not apple', 'not apple', 'not apple',
'not apple'], dtype=object)
We generate a dataset associating a color to being an apple or not an apple. We strongly associated “green” and “red” to being an apple. The minority class being “not apple”, we expect new data generated belonging to the category “blue”:
我们生成一个数据集,将颜色与是否是苹果关联起来。我们强烈地将“绿色”和“红色”与是苹果联系在一起。少数类别为“非苹果”,我们预计生成的新数据属于“蓝色”类别:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)