对yolo系列文章的发展做个总结。神经网络训练模型的根本就是真值与预测值比较,落实到不同任务最根本的区别的就是对真值的编码。理解深度学习的关键是明白真实值如何编码,下面从这个角度介绍。
1、问题的引入
深度学习最早用来解决分类问题,对于一个10分类任务,将类别编码为 one-hot 形式。

对于一个分类问题,我们希望输入一张图,输出类别。以四分类的行人、自行车、摩托车、小汽车为例,图像为数字矩阵,所以我们很容易想到对四类别分别用四个数字描述。只管的描述:1、行人;2、自行车;3、摩托车;4、小汽车。让模型预测输出 1~4 这四个数。这样好吗?
可以直观的看到这四个类别之间的距离时不一样的,实际中这四个类别之间毫无关系。所以,引入one-hot编码,将目标编码为对应的 0、1向量,这样不同类别之间就独立了。
2、目标检测真值编码
如果你还想定位图片中汽车的位置,该怎么做呢?我们可以让神经网络多输出几个单元,输出一个边界框。具体说就是让神经网络再多输出 4 个数字,标记为𝑏𝑥,𝑏𝑦,𝑏ℎ和𝑏𝑤,这四个数字是被检测对象的边界框的参数化表示。
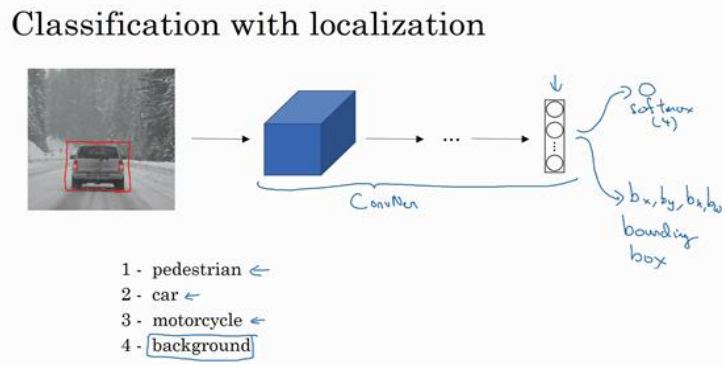
这有四个分类,神经网络输出的是这四个数字和一个分类标签,或分类标签出现的概率。目标标签𝑦的定义如下:
𝑦 =[𝑝𝑐, 𝑏𝑥, 𝑏𝑦, 𝑏ℎ, 𝑏𝑤, 𝑐1, 𝑐2, 𝑐3, c4]
上面方式只能在分类中,检测一个目标(神经网络输出维度固定的,不能预测未知数量的目标!),如何检测多个目标呢?
2.1、从滑动窗角度解释
假设一个14*14*3的图像经过一系列卷积,最后输出1*1*4向量。这个1*1*4向量就是我们对这张图像的分类结果。若把输出向量改为1*1*(1+4+4)就是对这张图类别的分类和定位。
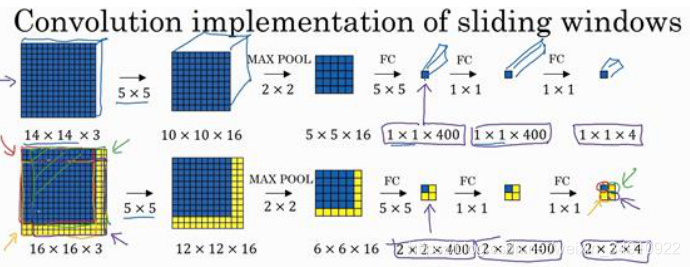
同样的网络,我们在 16×16×3 的小图像上滑动窗口,卷积网络运行了4次,于是输出了了4个标签。映射至原图,相当于对原图做了大小为 14*14 步长为 2 的滑动窗。
同样的网络,输入 28*28*3 ,最后输出 8*8*4 向量。映射至原图,相当于做了大小为 14*14步长为 2 的滑动窗。

2.2、从位置预测解释
再来从另一个角度解释目标检测编码问题。上面的目标定位可以识别图像中的一个目标的大小和位置,但要识别多个该怎么办呢?
一种直接的想法,那就再增加特征向量的维度呗。原先四类目标输出向量为:(1+4+4),现在增加数量那就是:(1+4+4)*N,N为要预测的最大目标数量。这样好吗?
问题,数量可以牵强的达到要求,但是未对目标的位置与向量的位置建立关系!所以,很容易就想到了要检测四个目标那就把图像最后输出四个格子,向量的维度收敛至格子内,就形成了现在的编码形式。将最后特征的卷积按层展开,则应该是(1+4+4)层2*2的卷积。真值进行对应编码即可。

3、yolov3输出编码
以输入416*416为例,实际中图像大小可以是任意,作者先将图像缩放至416*416大小,对应的坐标也缩放至416*416大小的对应位置。如下图,目标在416*416图像大小下的坐标为:(cx,cy,bw,bh) = (5.86, 7.12, 1.41, 2.13)。

v3-tiny对应有两个yolo输出,结构是一样的,我们一13*13的输出为例。以三类别检测为例,输出为:batch*(4+1+3)*13*13。物体中心点落到某个格子就以某个格子预测该物体,没有落入物体的格子则赋值为0。
3.1、坐标回归相对值编码
对于坐标的回归作者并未使用原始的大小,而是使用了相对值。相对值约束了一个范围,加速了训练,也减少了坐标的漂移。
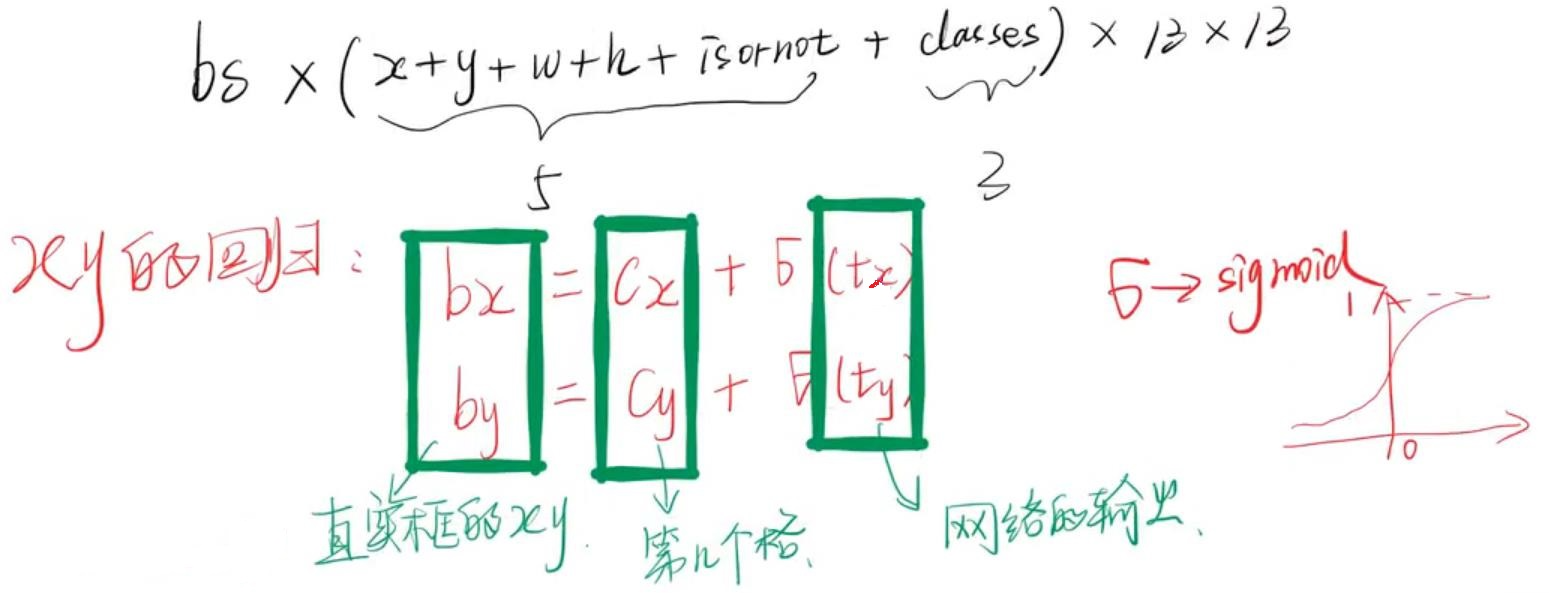
中心点x, y 的预测由小数部分 tx, ty 加整数部分cx, cy(也就是格子的坐标)确定,tx, ty 经过sigmod函数输出值约束至0~1。经过sigmod约束,大部分的实际预测值限制在-4~4范围。

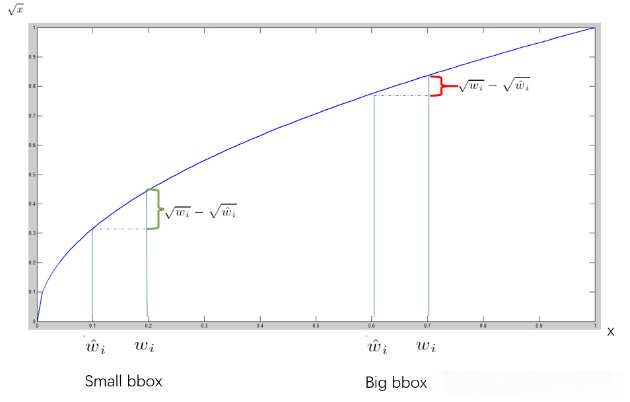
宽高的预测,可以简单约束下,relu激活下,确保预测结果为正数。yolo作者在v1时,考虑大小框对损失贡献不一致的情况,损失函数采用sqrt(w),sqrt(h)约束,降低框大小对损失的影响。
3.2、锚点、锚框(anchor)
只使用格子,一个格子只能预测一个目标,当图像内目标较密集时,就很容易出现多个目标的中心点落到同一个格子内。且不同目标大小不一样,宽高比也不一样。
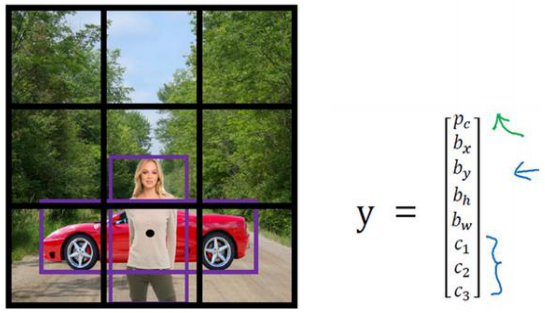
这时候引入anchor机制。yolo里面使用了3个,faster rcnn系列使用6个。我们以两个anchor为例:
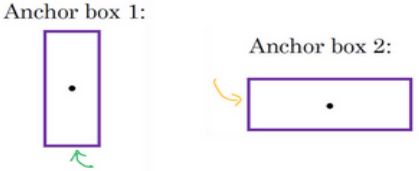
对于不适用anchor来说,上面的格子用的向量为:
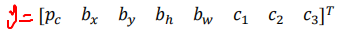
使用两个anchor,上面向量改为:

目标中心点落到该格子上,之后判断离它大小更相似的anchor预测该目标。
实际工程实际中,往往会设置一个阈值,iou>th的锚框都可以预测该目标,当没有任何锚框超过阈值时,选最相似的那个锚框预测。
实际宽高预测是,也是预测相对锚框的大小,如下:
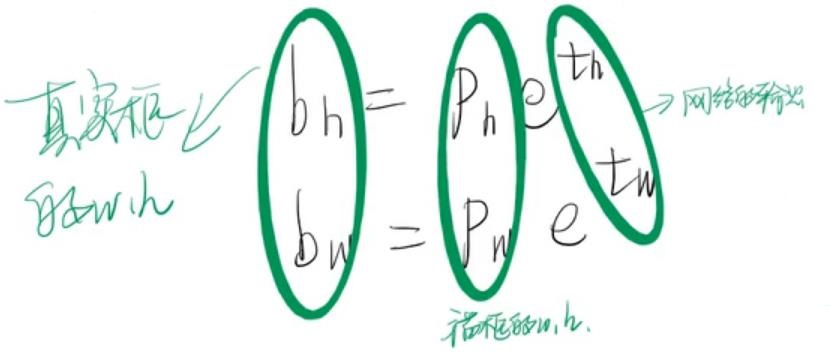
y = exp(x) 函数可视化:
可以看到,大部分的预测值被约束在-2~2之间。决策推理时,每个anchor位置的预测th, tw取该anchor的宽高ph, pw作用,生成最终的bw, bh。
4、yolo输出向量格式
输出为:batch * 13 * 13 * (tx, ty, tw, th, conf, ont-hot-class)。假设共80类目标,则输出向量为:batch * 13 *13 * (4+1+80)。
扩展文章:
1、在线曲线生成器
在线绘制多项式/函数曲线图形工具 - 在线计算器 - 脚本之家在线工具
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)