一种基于卡尔曼滤波的语音增强方法
摘要
本文考虑了只有损坏的语音信号可供处理时的语音增强问题。为此,研究了卡尔曼滤波方法,并与维纳滤波方法进行了比较。卡尔曼滤波方法的性能明显优于维纳滤波方法。提出了一种延迟卡尔曼滤波方法,进一步提高了卡尔曼滤波的语音增强性能。
1 介绍
在许多实际情况下,语音信号被白噪声的加入所破坏。噪音的存在会影响语音的可理解性。一个例子是飞行员和空中交通管制塔之间的通信,其中语音通常由于发动机噪声的增加而降低。在这种情况下,最好是提高语音的质量和可理解性。在自动语音和说话人识别系统中,如果在预处理阶段加入语音增强方案,识别将变得更简单、更可靠。语音增强在语音编码应用中也起着重要的作用。
本文所解决的问题是在只有损坏的语音信号可供处理时增强语音。文献报道了大量语音增强的方法。平稳维纳滤波方法是一种重要的语音增强方法之一。
由于语音在本质上是非平稳的,平稳维纳滤波器不能很好地处理。因此,提出了基于短时功率谱的方法。最近,帕利瓦尔[2]提出了一种非平稳的语音增强维纳推理方法,其中维纳滤波器由使用最小二乘法的每个短时间语音段(持续时间=20-30毫秒)设计的。
虽然非平稳维纳滤波器在最小二乘误差意义上对给定段是最优的,但它没有利用语音产生过程的知识。在本文中,我们提出了允许语音非平稳性的卡尔曼滤波方法,同时利用了语音产生模型。我们还表明,同一过滤器的延迟版本提供了进一步的改进,尽管计算的复杂度保持相同。
2 卡尔曼滤波器的语音增强功能
- 数学公式
语音可以用一个自回归(AR)过程来表示,它本质上是一个由白噪声序列驱动的全极点线性系统的重要输出。因此,第k个时刻的语音信号s (k)由:
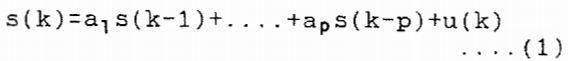
对方程(1)的一点观察表明,它可以用状态空间模型来表示,如下图所示。

其中,X (k)、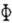 和G分别为状态向量、状态转换矩阵和输入矩阵。其定义如下:
和G分别为状态向量、状态转换矩阵和输入矩阵。其定义如下:

当只有噪声损坏的信号y (k)存在时,观测过程可以写入以下形式:

这个方程可以写成以下矩阵形式:

其中X (k)为方程(4)定义的状态向量,H为给出的观测矩阵:
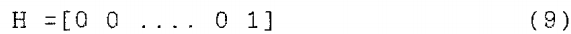
噪声序列{u(k)}和噪声序列{n(k)}是零均值白噪声过程,且不相关。观测噪声n (k)也与状态向量不相关。对于所有的k和l,我们可以写下:

它也假设X最初的估计是 并且是无偏的,即
并且是无偏的,即

误差协方差矩阵Po的初始估计,是已知的从以下相对论
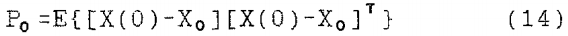
状态方程(3)和观测方程(8)清楚地表明,卡尔曼滤波器可以很容易地应用于状态向量X (k)的估计。可以很容易地证明,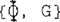 对和
对和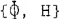 对分别是可控的和可观测的。因此,基于该模型的卡尔曼滤波器将是“稳定的”或“鲁棒”的,因为初始误差和f轮和其他计算误差的影响将渐近消失。
对分别是可控的和可观测的。因此,基于该模型的卡尔曼滤波器将是“稳定的”或“鲁棒”的,因为初始误差和f轮和其他计算误差的影响将渐近消失。
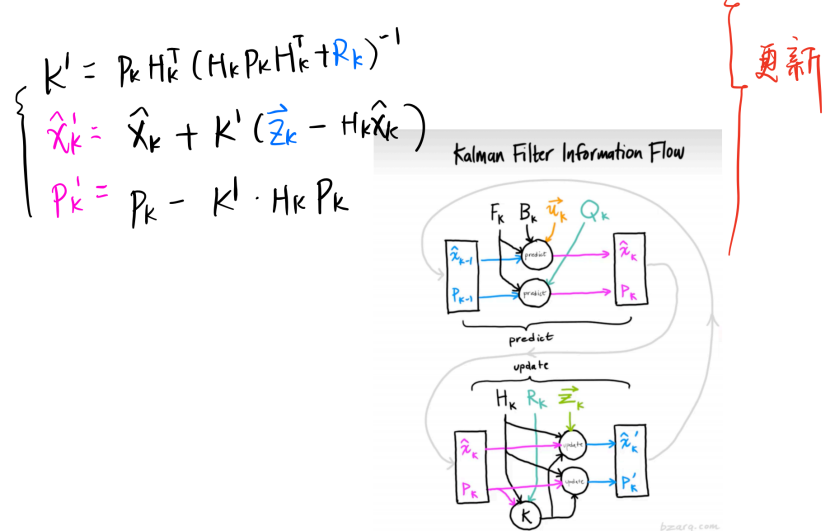
卡尔曼滤波器给出了基于观测值{y(1),y(2),…,y(k)}的X (k)的最小均方误差估计,这个估计用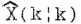 表示。相应的误差协方差矩阵为
表示。相应的误差协方差矩阵为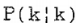 。类似地,X (k)的下一步预测估计为
。类似地,X (k)的下一步预测估计为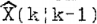 ,相关的误差协方差矩阵为
,相关的误差协方差矩阵为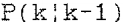 。使用这些符号,卡尔曼滤波算法可以通过以下递归关系给出:
。使用这些符号,卡尔曼滤波算法可以通过以下递归关系给出:
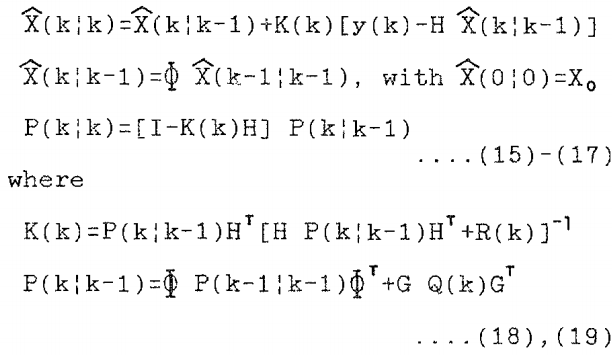
卡尔曼滤波对语音增强的应用包括两个独立的步骤:
- 估计AR系数
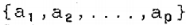 和噪声方差Q和R。很多文献中已经提出了不同的方法来估计这些参数。
和噪声方差Q和R。很多文献中已经提出了不同的方法来估计这些参数。 - 利用估计的参数值应用卡尔曼滤波算法。状态向量
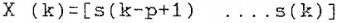 的最后一个分量,即
的最后一个分量,即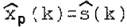 给出了语音信号s (k)的卡尔曼滤波估计。
给出了语音信号s (k)的卡尔曼滤波估计。
- 延迟卡尔曼滤波器
进一步的观察表明,状态向量的第一个分量s(k-p+1) 将更好地提供第(k-p+1)时刻的语音信号估计,因为这个估计使用了(p-1)额外观测数据{y(k-p+2),....,y(k)}形式的额外信息。这一现象反映在对角线元素, ,误差协方差矩阵
,误差协方差矩阵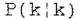 按升序排列。
按升序排列。
实际上,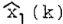 是s(k-p+1) 的固定滞后平滑估计,它是滞后(lag)=p-1。这种方法将
是s(k-p+1) 的固定滞后平滑估计,它是滞后(lag)=p-1。这种方法将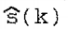 的计算延迟到1(k+p-1)。因此,我们将这个估计称为延迟卡尔曼滤波估计。
的计算延迟到1(k+p-1)。因此,我们将这个估计称为延迟卡尔曼滤波估计。
4 增值计算复杂度
卡尔曼滤波方法的计算方法无疑比较复杂。每次迭代都需要进行矩阵向量乘法,从而产生一个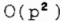 的操作数。但是,使用快速卡尔曼算法[7],它依赖于一些移位不变的特性,将每次迭代的计算复杂度降低到O (p)操作。另一个有趣的一点是,对于每个段,误差协方差和卡尔曼增益矩阵经过几步后达到一个稳态值。在此之后,稳态增益值可以用于该段的其余部分。因此,可以实现大量的计算机-狮子节省。
的操作数。但是,使用快速卡尔曼算法[7],它依赖于一些移位不变的特性,将每次迭代的计算复杂度降低到O (p)操作。另一个有趣的一点是,对于每个段,误差协方差和卡尔曼增益矩阵经过几步后达到一个稳态值。在此之后,稳态增益值可以用于该段的其余部分。因此,可以实现大量的计算机-狮子节省。
5 结论
本文提出了一种提高语音能力的卡尔曼滤波方法,并将其与平稳和正态平稳维纳滤波方法的性能进行了比较。由于卡尔曼滤波利用了语音产生模型,人们发现它比维纳滤波方法具有更好的性能(在信噪比和SEGSNR方面)。并提出了一种延迟卡尔曼滤波器,由于其固有的固定滞后平滑操作,进一步提高了卡尔曼滤波器的语音增强性能。


本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)