在深度学习训练的时候,数据的batch size大小受到GPU内存限制,batch size大小会影响模型最终的准确性和训练过程的性能。在GPU内存不变的情况下,模型越来越大,那么这就意味着数据的batch size智能缩小,这个时候,梯度累积(Gradient Accumulation)可以作为一种简单的解决方案来解决这个问题。
Batch size的作用
训练数据的Batch size大小对训练过程的收敛性,以及训练模型的最终准确性具有关键影响。通常,每个神经网络和数据集的Batch size大小都有一个最佳值或值范围。
不同的神经网络和不同的数据集可能有不同的最佳Batch size大小。
选择Batch size的时候主要考虑两个问题:
泛化性:大的Batch size可能陷入局部最小值。陷入局部最小值则意味着神经网络将在训练集之外的样本上表现得很好,这个过程称为泛化。因此,泛化性一般表示过度拟合。
收敛速度:小的Batch size可能导致算法学习收敛速度慢。网络模型在每个Batch的更新将会确定下一次Batch的更新起点。每次Batch都会训练数据集中,随机抽取训练样本,因此所得到的梯度是基于部分数据噪声的估计。在单次Batch中使用的样本越少,梯度估计准确度越低。换句话说,较小的Batch size可能会使学习过程波动性更大,从本质上延长算法收敛所需要的时间。
考虑到上面两个主要的问题,所以在训练之前需要选择一个合适的Batch size。

Batch size对内存的影响
虽然传统计算机在CPU上面可以访问大量RAM,还可以利用SSD进行二级缓存或者虚拟缓存机制。但是如GPU等AI加速芯片上的内存要少得多。这个时候训练数据Batch size的大小对GPU的内存有很大影响。
为了进一步理解这一点,让我们首先检查训练时候AI芯片内存中内存的内容:
- 模型参数:网络模型需要用到的权重参数和偏差。
- 优化器变量:优化器算法需要的变量,例如动量momentum。
- 中间计算变量:网络模型计算产生的中间值,这些值临时存储在AI加速芯片的内存中,例如,每层激活的输出。
- 工作区Workspace:AI加速芯片的内核实现是需要用到的局部变量,其产生的临时内存,例如算子D=A+B/C中B/C计算时产生的局部变量。
因此,Batch size越大,意味着神经网络训练的时候所需要的样本就越多,导致需要存储在AI芯片内存变量激增。在许多情况下,没有足够的AI加速芯片内存,Batch size设置得太大,就会出现OOM报错(Out Off Memor)。
使用大Batch size的方法
解决AI加速芯片内存限制,并运行大Batch size的一种方法是将数据Sample的Batch拆分为更小的Batch,叫做Mini-Batch。这些小Mini-Batch可以独立运行,并且在网络模型训练的时候,对梯度进行平均或者求和。主要实现有两种方式。
1)数据并行:使用多个AI加速芯片并行训练所有Mini-Batch,每份数据都在单个AI加速芯片上。累积所有Mini-Batch的梯度,结果用于在每个Epoch结束时求和更新网络参数。
2)梯度累积:按顺序执行Mini-Batch,同时对梯度进行累积,累积的结果在最后一个Mini-Batch计算后求平均更新模型变量。
虽然两种技术都挺像的,解决的问题都是内存无法执行更大的Batch size,但梯度累积可以使用单个AI加速芯片就可以完成啦,而数据并行则需要多块AI加速芯片,所以手头上只有一台12G二手卡的同学们赶紧把梯度累积用起来。
梯度累积原理
梯度累积是一种训练神经网络的数据Sample样本按Batch拆分为几个小Batch的方式,然后按顺序计算。
在进一步讨论梯度累积之前,我们来看看神经网络的计算过程。
深度学习模型由许多相互连接的神经网络单元所组成,在所有神经网络层中,样本数据会不断向前传播。在通过所有层后,网络模型会输出样本的预测值,通过损失函数然后计算每个样本的损失值(误差)。神经网络通过反向传播,去计算损失值相对于模型参数的梯度。最后这些梯度信息用于对网络模型中的参数进行更新。
优化器用于对网络模型模型权重参数更新的数学公式。以一个简单随机梯度下降(SGD)算法为例。假设Loss Function函数公式为:
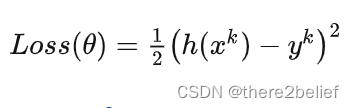
在构建模型时,优化器用于计算最小化损失的算法。这里SGD算法利用Loss函数来更新权重参数公式为:
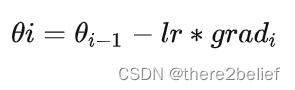
其中theta是网络模型中的可训练参数(权重或偏差),lr是学习率,grad是相对于网络模型参数的损失。
梯度累积则是只计算神经网络模型,但是并不及时更新网络模型的参数,同时在计算的时候累积计算时候得到的梯度信息,最后统一使用累积的梯度来对参数进行更新。
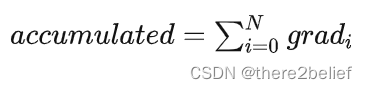
在不更新模型变量的时候,实际上是把原来的数据Batch分成几个小的Mini-Batch,每个step中使用的样本实际上是更小的数据集。
在N个step内不更新变量,使所有Mini-Batch使用相同的模型变量来计算梯度,以确保计算出来得到相同的梯度和权重信息,算法上等价于使用原来没有切分的Batch size大小一样。即:
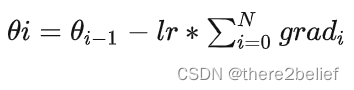
最终在上面步骤中累积梯度会产生与使用全局Batch size大小相同的梯度总和。

当然在实际工程当中,关于调参和算法上有两点需要注意的:
学习率 learning rate:一定条件下,Batch size越大训练效果越好,梯度累积则模拟了batch size增大的效果,如果accumulation steps为4,则Batch size增大了4倍,根据ZOMI的经验,
使用梯度累积的时候需要把学习率适当放大。
归一化 Batch Norm:accumulation steps为4时进行Batch size模拟放大效果,和真实Batch size相比,数据的分布其实并不完全相同,4倍Batch size的BN计算出来的均值和方差与实际数据均值和方差不太相同,因此有些实现中会使用Group Norm来代替Batch Norm。
梯度累积的PyTorch实现
自动累积
PyTorch默认会对梯度进行累加。即,PyTorch会在每一次backward()后进行梯度计算,但是梯度不会自动归零,如果不进行手动归零的话,梯度会不断累加.
至于为什么PyTorch有这样的特点,discuss.pytorch.org/t/why-do-we… 这里给出了一个解释。我们结合其他的解释大致得出如下:
- 从PyTorch的设计原理上来说,在每次进行前向计算得到预测值时,会产生一个用于梯度回传的计算图,这张图储存了进行反向传播需要的中间结果,当调用了.backward()后,会从内存中将这张图进行释放。
- 利用梯度累加,可以在最多保存一张计算图的情况下进行多任务的训练。在多任务中,对前面共享的张量进行了多次计算操作后,调用不同任务的backward(),那些张量的梯度会自动累加。
- 另外一个理由就是在内存大小不够的情况下叠加多个batch的grad作为一个大batch进行迭代,因为二者得到的梯度是等价的。
- 由于PyTorch的动态图和autograd机制,导致并没有一个确切的点知道何时停止前向操作,因为你不知道什么时候一个计算会结束以及什么时候又会有一个新的开始。所以自动设置梯度为 0 比较棘手。
代码示例
下面给出一个传统代码示例:
for i,(images,target) in enumerate(train_loader):
# 1. input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
outputs = model(images)
loss = criterion(outputs,target)
# 2. backward
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step()
复制代码
单卡梯度累积
- 获取loss: 输入图像和标签,通过计算得到预测值,计算损失函数;
loss.backward()反向传播,计算当前梯度;- 多次循环步骤 1-2, 不清空梯度,使梯度累加在已有梯度上;
- 梯度累加一定次数后,先
optimizer.step()根据累积的梯度更新网络参数,然后optimizer.zero_grad()清空过往梯度,为下一波梯度累加做准备;
for i, (images, target) in enumerate(train_loader):
# 1. input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
outputs = model(images) # 前向传播
loss = criterion(outputs, target) # 计算损失
# 2. backward
loss.backward() # 反向传播,计算当前梯度
# 3. update parameters of net
if ((i+1)%accumulation)==0:
# optimizer the net
optimizer.step() # 更新网络参数
optimizer.zero_grad() # reset grdient # 清空过往梯度
复制代码
DistributedDataParallel 的梯度累积
DistributedDataParallel(DDP)在module级别实现数据并行性。其使用torch.distributed包communication collectives来同步梯度,参数和缓冲区。并行性在单个进程内部和跨进程均有用。
在这种情况下,虽然gradient accumulation 也一样可以应用,但是为了提高效率,需要做相应的调整。
1、单卡模型梯度累计
我们首先回忆单卡模型,即普通情况下如何进行梯度累加。
# 单卡模式,即普通情况下的梯度累加
for data in enumerate(train_loader # 每次梯度累加循环
optimizer.zero_grad()
for _ in range(K):
prediction = model(data / K)
loss = loss_fn(prediction, label) / K
loss.backward() # 积累梯度,不应用梯度改变,执行K次
optimizer.step() # 应用梯度更新,更新网络参数,执行一次
复制代码
在 loss.backward() 语句处,DDP会进行梯度规约 all_reduce。
因为每次梯度累加循环之中有K个步骤,所以有K次 all_reduce。但实际上,每次梯度累加循环中,optimizer.step()只有一次,这意味着我们这K次 loss.backward() 之中,其实只进行一次 all_reduce 即可,前面 K - 1 次 all_reduce 是没有用的。
2、DDP如何加速
于是我们就思考,是否可以在 loss.backward() 之中有一个开关,使得我们在前面K-1次 loss.backward() 之中只做反向传播,不做梯度同步(累积)。
DDP 已经想到了这个问题,它提供了一个暂时取消梯度同步的context函数 no_sync()。在no_sync()context之下,DDP不会进行梯度同步。但是在no_sync()上下文结束之后的第一次 forward-backward 会进行同步。
最终代码如下:
model = DDP(model)
for data in enumerate(train_loader # 每次梯度累加循环
optimizer.zero_grad()
for _ in range(K-1):# 前K-1个step 不进行梯度同步(累积梯度)。
with model.no_sync(): # 这里实施“不操作”
prediction = model(data / K)
loss = loss_fn(prediction, label) / K
loss.backward() # 积累梯度,不应用梯度改变
prediction = model(data / K)
loss = loss_fn(prediction, label) / K
loss.backward() # 第K个step 进行梯度同步(累积梯度)
optimizer.step() # 应用梯度更新,更新网络参数
参考:
https://juejin.cn/post/7000532679191953445
https://www.zhihu.com/question/435093513/answer/2302992975
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)