scikit-learn提供了Scaler来进行数据的标准化处理,例如StandardScaler类是一个用来讲数据进行均值方差归一化的类。
所谓归一化和标准化,即应用下列公式:
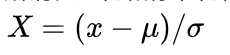
使得新的X数据集方差为1,均值为0
在使用Scaler时有transform和fit_transform两种方法,有什么区别呢?
fit_transform方法是fit和transform的结合,fit_transform(X_train) 意思是找出X_train的均值和标准差,并应用在X_train上。
这时对于X_test,我们就可以直接使用transform方法。因为此时StandardScaler已经保存了X_train的均值和标准差
二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)
fit_transform(partData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该partData进行转换transform,从而实现数据的标准化、归一化等等。。
根据对之前部分fit的整体指标,对剩余的数据(restData)使用同样的均值、方差、最大最小值等指标进行转换transform(restData),从而保证part、rest处理方式相同。
必须先用fit_transform(partData),之后再transform(restData)
如果直接transform(partData),程序会报错
如果fit_transfrom(partData)后,使用fit_transform(restData)而不用transform(restData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异
使用示例:
RS = RobustScaler(quantile_range=(20.0, 80.0))
train = RS.fit_transform(train)
test = RS.transform(test)
————————————————
来源:https://blog.csdn.net/qq_35290785/article/details/97050965
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)