本文章基于yolov5-6.2版本。主要讲解的是yolov5是怎么在最终的特征图上得出物体边框、置信度、物体分类的。
一、总体框架
首先贴出总体框架,直接就拿官方文档的图了,本文就是接着右侧的那三层输出开始讨论。
- Backbone: New CSP-Darknet53
- Neck: SPPF, New CSP-PAN
- Head: YOLOv3 Head
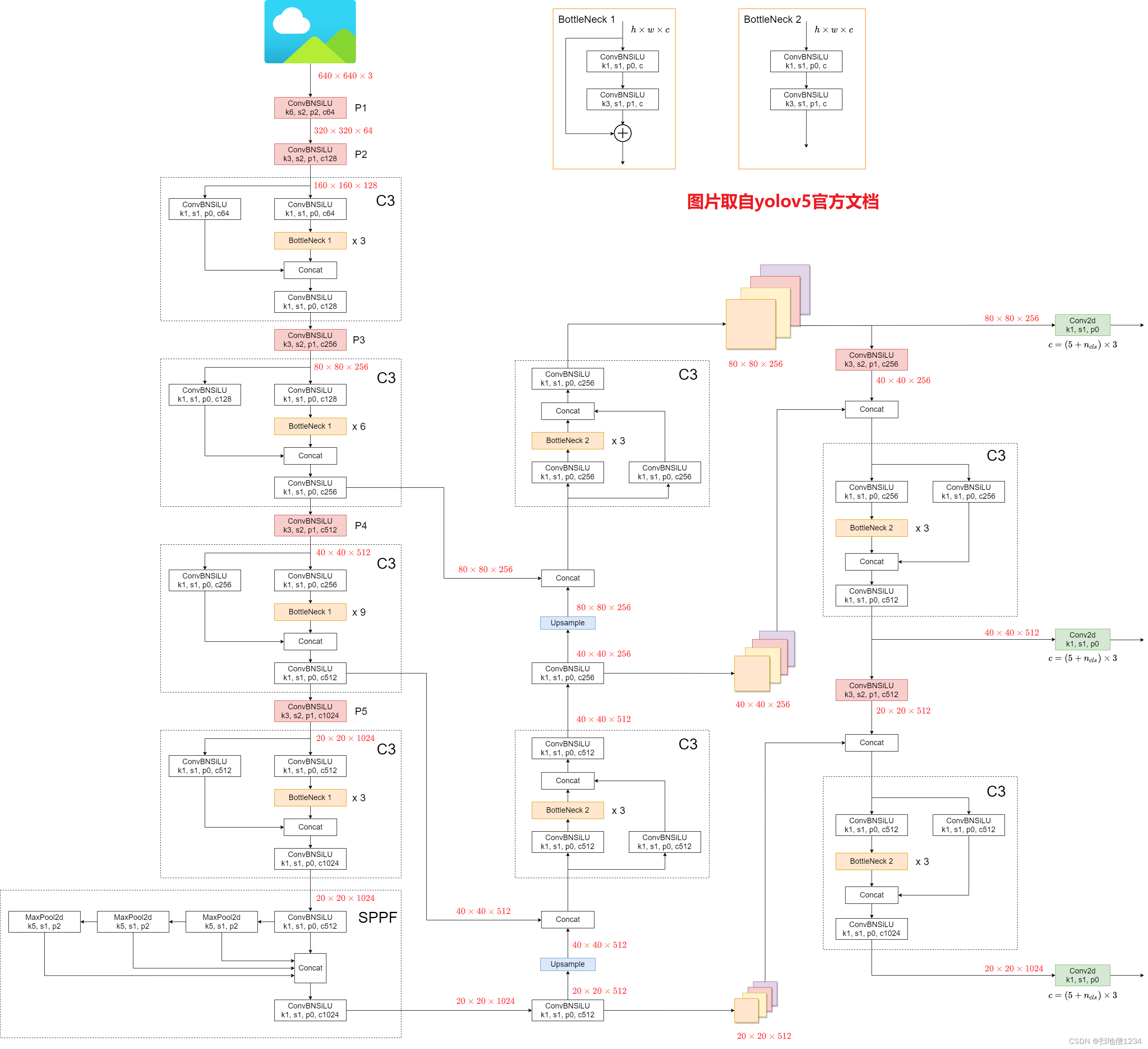
这三个输出层分别就是浅、中、深层啦,浅层特征图分辨率是80乘80,中层是40乘40,深层是20乘20,一般来说浅层用于预测小物体,深层用于预测大物体。另外说明一下,浅、中、深三层的特征图输出通道数不一定是256、512、1024,要看你用的是哪一种规格的模型。比如yolov5s的话,那这三层的通道数分别是128、256、512,可以导出onnx格式用Netron看一下模型结构来确定。
简要说一下原因,这个是由对应的模型配置文件,即models目录里的yolov5s.yaml,yolov5m.yaml等等来决定的,看你用哪一个,第二个红框里的就是每一层的输出通道数了,但是它是要乘上第一个红框里的值的,即width_multiple这个配置,你会发现几个模型配置文件的内容都差不多,区别就区别在这里的depth_multiple和width_multiple。

二、输出物体边框、置信度、物体分类
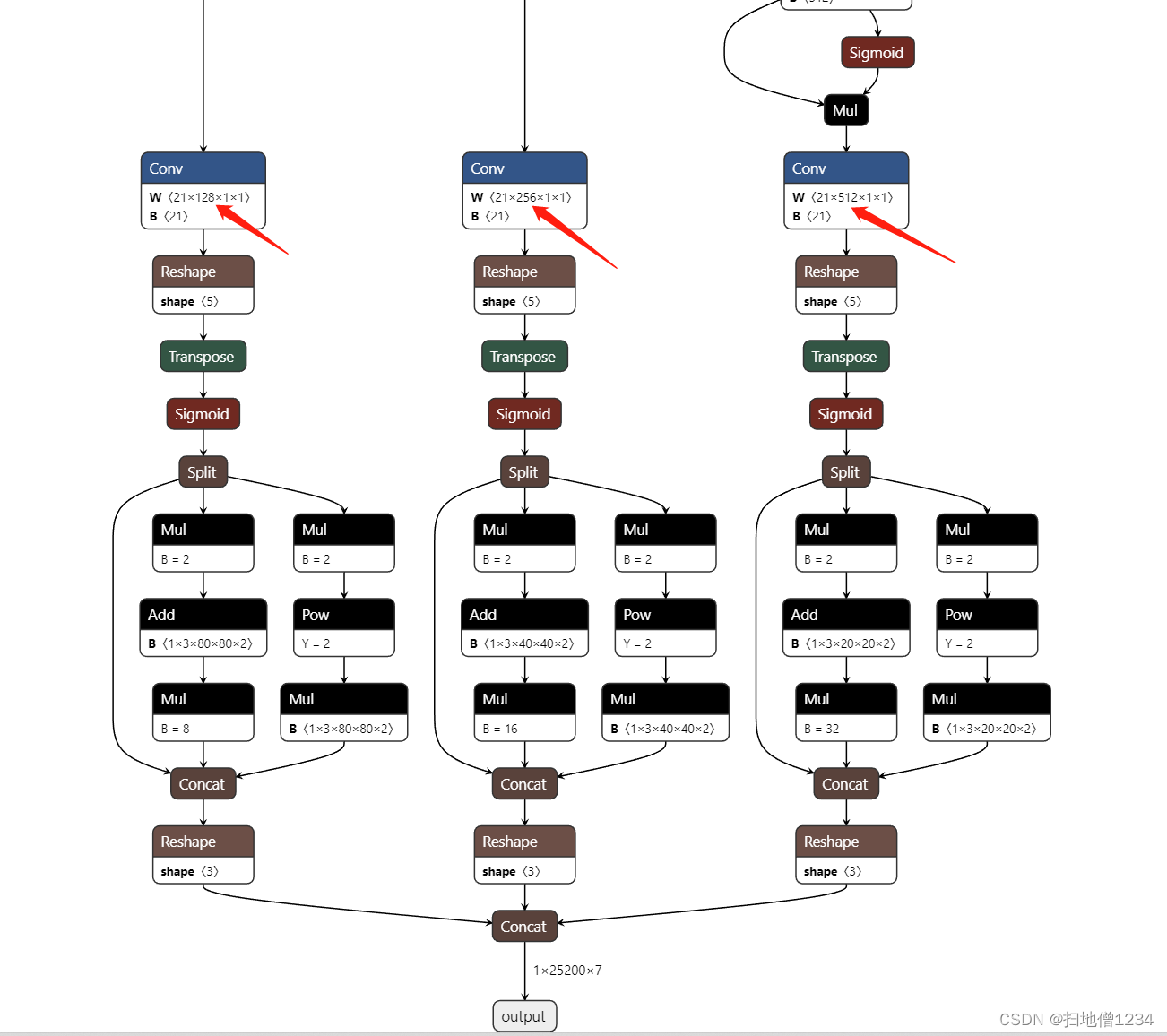
接下来进入正题,每层特征图最终都会经过1乘1卷积,变成(5+分类数)乘3个通道:
0)首先为什么乘以3,因为每一层都有3个anchor,后面再细讲
下面讲的是每一anchor对应的(5+分类数)个通道,假设分类数为2,那一共就是7个通道了,这7个通道分别是xywh(4个通道),置信度(1个通道),分类(此处2分类,就是2个通道)
1)物体边框的4个值,x,y,w,h啦,不过这个x,y并不直接是物体框中心点的坐标,而是它相对于自身所处的格子左上角的偏移,比如下图红色的这个格子(假设现在特征图就是4乘4),这个格子预测出7个值,前4个就是xywh,然后x是0.2,y是0.2,那么中心点就差不多在蓝点所处的位置了(其实这其中还有玄机,一步步来)。然后再把这个中心点的相对值作用到原图的尺度得到最终的坐标。

但是呢如果像上面这样直接预测一个相对格子左上角的偏移的这样一个值呢,会比较不稳定,它可能预测的值很大,比如x给你预测一个10出来,那就是往右数10个格子了,偏差这么大不利用网络收敛,也没有意义,因为这个格子里的特征跟右边第10个格子的特征相差可能很大了。
所以要加一个限制,首先给它sigmoid一下,这样其值范围就变成0-1了(小数),此时它的波动就在自己的这个格子内,然后乘以2再减0.5,如下图(直接拿官方文档的图了~~)

这样它的波动范围就是下图的黄框的范围。

限制为0-1好理解,自己这个格子的预测范围就在自己格子内麻,为啥又变成了-0.5-1.5呢,因为这样更容易得到0-1范围内的值。如果的范围限制为0-1,而且是用sigmoid来限制的话,那接近0和1这两个位置的导数就会很小,梯度更新的时候就会慢。
然后就是宽高,宽高也不是直接预测出物体边框的宽高啦,而是基于anchor的,预测出来的值会乘上anchor的宽高得出最终的宽高,并且,这里仍然是先用sigmoid将输出值限制为0-1,然后再乘以2,再来个平方,这样最终的值的范围就是0-4了。

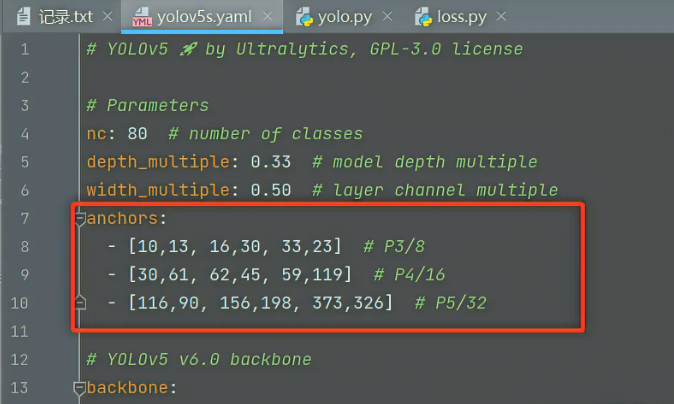
之前说了每一层有3个anchor,这些anchor还是配置在模型的配置文件里的,比如models/yolov5s.yaml,P3就是浅层的(80乘80的格子),P4是中层的(40乘40),P5是深层的(20乘20),然后这里的anchor的大小呢就是绝对值(按照640乘640的图来算的,如果你的输入图不是640乘640,那输入图是会resize一下再进行推理的)
比如现在是深层的输出,2分类,那么深层的特征图经过最后的1乘1卷积后,会得到3乘(5+2)=21个通道,每7个通道就对应一个anchor了,现在看第2个7个通道(即7-13,从0开始算),那么它对应的anchor就应该是156,198这个,那么预测出来的宽高值经过sigmoid,再乘2,再平方之后,还分别要乘上156和198,得出最终的物体宽高(基于640乘640的图的),然后再按比例得到原图的物体宽高。
2)置信度
代表预测出的物体边框和分类的可信度,最终的范围肯定是0-1了(小数),跟前面的一样,会用sigmoid来把它的范围限制为0-1。
这边可能有一个问题,那个xy不是sigmoid()乘2减0.5吗,这里咋不这么干,那是因为xy的值真的是可以达到-0.5或1.5的,那样的话就变成预测的物体中心点跑到相邻格子里去了,这也不是不行的啦。但置信度只能是0-1!
3)分类
有几个分类,就会再加几个通道,分别代表对应分类的概率,都是用sigmoid把他们的概率限制为0-1,在计算损失的时候,标签对应分类所在通道的直值为1,其它都为0了,然后分别计算BCE损失。
三、源码
最终输出层的相关源码主要就是models/yolo.py的Detect类的源码了,添加了相应的注释。
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors,除以2是因为[10,13, 16,30, 33,23]这个长度是6,对应3个anchor
self.grid = [torch.zeros(1)] * self.nl # init grid,下面会计算grid,grid就是每个格子的x,y坐标(整数,比如0-19)
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2),注意后面就可以通过self.anchors来访问它了
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv,3个输出层最后的1乘1卷积
self.inplace = inplace # use inplace ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl): # 三个输出层分别处理
x[i] = self.m[i](x[i]) # conv,经过这个1乘1卷积就变成(5+分类数)个通道了
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)--这里的85对应coco数据集,5+80个分类
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
# 这里的grid[i]即对应输出层的3个anchor层的每个格子的坐标,方便进行批量计算,乘上对应的stride[i](下采样率),就得到基于640乘640的图的坐标了
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
# anchor_grid[i]也是一样,不过它的形状是(1, self.na, 1, 1, 2),跟y[..., 2:4]计算时是会自动广播的,最终得到的宽高也是基于640乘640的图的宽高
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
# 这段是非inplace操作,计算方法是一样的
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')):
d = self.anchors[i].device
t = self.anchors[i].dtype
shape = 1, self.na, ny, nx, 2 # grid shape
# grid其实就是特征图网络的坐标,比如20乘20的,其坐标分别是0,0 0,1...0,19 1,0 1,1...19,19,第2个维度na就是anchor数啦
y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
if torch_1_10: # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid(y, x, indexing='ij')
else:
yv, xv = torch.meshgrid(y, x)
# 注意这边先给它把0.5给减了
grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
# anchor_grid即每个格子对应的anchor宽高,stride是下采样率,三层分别是8,16,32,这里为啥要乘呢,因为在外面已经把anchors给除了对应的下采样率,这里再乘回来
anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
return grid, anchor_grid
此处单独说一下torch.meshgrid,它其实就是用于得到网格坐标的,简化代码如下,假设现在是2乘2的网络
y, x = torch.arange(2), torch.arange(2)
yv, xv = torch.meshgrid(y, x, indexing='ij')
print(f'yv={yv}')
print(f'xv={xv}')
grid = torch.stack((xv, yv), 2)
print(f'grid={grid}')
输出如下:

grid对应的就是如下图,得到这个网络坐标就可以直接跟输出层的x,y做批量运算了。

四、NMS
Detect类foward之后确实是整个网络最终的输出,不过这个输出还得再经过NMS,提取出最终的答案,即这张图上到底有几个物体,边框、置信度、分类分别是什么。NMS后面再讨论~~
————————————————
原文链接:https://blog.csdn.net/ogebgvictor/article/details/127481011
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)