第一章 TiDB概述
TiDB官网:https://pingcap.com/index.html
TiDB可以理解为是MySQL的加强版/分布式MySQL/MySQLPlus

TiDB 简介
TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。
TiDB数据库具备「分布式强一致性事务、在线弹性水平扩展、故障自恢复的高可用、跨数据中心多活」等核心特性,是大数据时代理想的数据库集群和云数据库解决方案。目前,已被近 1000 家不同行业的领先企业应用在实际生产环境,涉及互联网、游戏、银行、保险、证券、航空、制造业、电信、新零售、政府等多个行业,包括美国、欧洲、日本、东南亚等海外用户。
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
第二章 TiDB架构特性
2.1 TiDB 整体架构
TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件和简化云上部署管理的 TiDB Operator 组件。


2.1.1 TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
2.1.2 PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点。
2.1.3 TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
2.1.4 TiSpark
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
2.1.5 TiDB Operator
TiDB Operator 提供在主流云基础设施(Kubernetes)上部署管理 TiDB 集群的能力。它结合云原生社区的容器编排最佳实践与 TiDB 的专业运维知识,集成一键部署、多集群混部、自动运维、故障自愈等能力,极大地降低了用户使用和管理 TiDB 的门槛与成本。
2.2 TiDB 核心特性
-
高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
对于用户使用的时候,可以透明地从MySQL切换到TiDB 中,只是“新MySQL”的后端是存储“无限的”,不再受制于Local的磁盘容量。在运维使用时也可以将TiDB当做一个从库挂到MySQL主从架构中。
-
分布式事务
TiDB 100% 支持标准的 ACID 事务。
-
一站式 HTAP 解决方案
HTAP: Hybrid Transactional/Analytical Processing
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
-
云原生 SQL 数据库
TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,配合 TiDB Operator 项目 可实现自动化运维,使部署、配置和维护变得十分简单。
-
水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
-
真正金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
TiDB 具备如上众多特性,其中两大核心特性为:水平扩展与高可用
2.2.1 水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力(TiDB)和存储能力(TiKV)。
TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。
TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。
PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。
所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
2.2.2 高可用

高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
-
TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
-
PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
-
TiKV
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 节点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 30 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
2.3 TiDB 存储和计算能力
2.3.1 存储能力-TiKV
TiKV Server通常是3+的,TiDB每份数据缺省为3副本,这一点与HDFS有些相似,但是通过Raft协议进行数据复制,TiKV Server上的数据的是以Region为单位进行,由PD Server集群进行统一调度,类似HBASE的Region调度。
TiKV集群存储的数据格式是KV的,在TiDB中,并不是将数据直接存储在 HDD/SSD中,而是通过RocksDB实现了TB级别的本地化存储方案,着重提的一点是:RocksDB和HBASE一样,都是通过 LSM树作为存储方案,避免了B+树叶子节点膨胀带来的大量随机读写。从何提升了整体的吞吐量。
2.3.2 计算能力-TiDB Server
TiDB Server本身是无状态的,意味着当计算能力成为瓶颈的时候,可以直接扩容机器,对用户是透明的。理论上TiDB Server的数量并没有上限限制。
第三章 TiDB安装部署
https://pingcap.com/docs-cn/stable/overview/#部署方式
3.1 TiDB-Local单机版
1.下载安装包
wget http://download.pingcap.org/tidb-latest-linux-amd64.tar.gz
2.解压文件
tar -zxvf tidb-latest-linux-amd64.tar.gz -C /opt/server/
3.启动
cd tidb-v5.0.1-linux-amd64/
#启动PD
./bin/pd-server --data-dir=pd --log-file=pd.log &
#启动tikv
./bin/tikv-server --pd="127.0.0.1:2379" --data-dir=tikv --log-file=tikv.log &
#启动tidb-server
./bin/tidb-server --store=tikv --path="127.0.0.1:2379" --log-file=tidb.log &
3.2 TiDB-Docker集群版
准备环境:
Docker(17.06.0 及以上版本)
Docker Compose
Git
1.下载 tidb-docker-compose
git clone https://github.com/pingcap/tidb-docker-compose.git
2.启动docker
sudo systemctl start docker
3.拉取镜像
cd tidb-docker-compose
docker-compose pull
4.启动集群
docker-compose up -d
5.访问集群
mysql -h 127.0.0.1 -P 4000 -u root
6.访问集群 Grafana 监控页面:
http://node1:3000/
默认用户名和密码均为 admin。
7.集群数据可视化:
http://node1:8010/
踩坑:
如果死活连接不上,看一下是不是磁盘不够了,在tikv.toml里面配置 reserve-space = “0MB”
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#reserve-space
安装Docker Compose
1.Compose 安装
sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
2.将可执行权限应用于二进制文件:
sudo chmod +x /usr/local/bin/docker-compose
3.创建软链:
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
4.测试是否安装成功:
docker-compose --version
第四章 TiDB实践案例
4.1 TiDB-SQL操作
同mysql一致
4.2 TiDB-读取历史数据
TiDB 实现了通过标准 SQL 接口读取历史数据功能,无需特殊的 client 或者 driver。当数据被更新、删除后,依然可以通过 SQL 接口将更新/删除前的数据读取出来。
另外即使在更新数据之后,表结构发生了变化,TiDB 依旧能用旧的表结构将数据读取出来。
4.2.1 说明
为支持读取历史版本数据, 引入了一个新的 system variable: tidb_snapshot ,这个变量是 Session 范围有效,可以通过标准的 Set 语句修改其值。其值为文本,能够存储 TSO 和日期时间。TSO 即是全局授时的时间戳,是从 PD 端获取的; 日期时间的格式可以为: “2020-10-08 16:45:26.999”,一般来说可以只写到秒,比如”2020-10-08 16:45:26”。 当这个变量被设置时,TiDB 会用这个时间戳建立 Snapshot(没有开销,只是创建数据结构),随后所有的 Select 操作都会在这个 Snapshot 上读取数据。
注意:
TiDB 的事务是通过 PD 进行全局授时,所以存储的数据版本也是以 PD 所授时间戳作为版本号。在生成 Snapshot 时,是以 tidb_snapshot 变量的值作为版本号,如果 TiDB Server 所在机器和 PD Server 所在机器的本地时间相差较大,需要以 PD 的时间为准。
当读取历史版本操作结束后,可以结束当前 Session 或者是通过 Set 语句将 tidb_snapshot 变量的值设为 “",即可读取最新版本的数据。
4.2.2 历史数据保留策略
TiDB 使用 MVCC 管理版本,当更新/删除数据时,不会做真正的数据删除,只会添加一个新版本数据,所以可以保留历史数据。历史数据不会全部保留,超过一定时间的历史数据会被彻底删除,以减小空间占用以及避免历史版本过多引入的性能开销。
TiDB 使用周期性运行的 GC(Garbage Collection,垃圾回收)来进行清理,关于 GC 的详细介绍参见 https://docs.pingcap.com/zh/tidb/dev/garbage-collection-overview。
这里需要重点关注的是 tikv_gc_life_time 和 tikv_gc_safe_point 这条。tikv_gc_life_time 用于配置历史版本保留时间,可以手动修改;tikv_gc_safe_point 记录了当前的 safePoint,用户可以安全地使用大于 safePoint 的时间戳创建 snapshot 读取历史版本。safePoint 在每次 GC 开始运行时自动更新。
4.2.3 示例
1.初始化阶段,创建一个表,并插入几行数据:
create table t (c int);
insert into t values (1), (2), (3);
2.查看表中的数据:
select * from t;
3.查看当前时间:
select now();
4.更新某一行数据:
update t set c=22 where c=2;
5.确认数据已经被更新:
select * from t;
6.设置一个特殊的环境变量,这个是一个 session scope 的变量,其意义为读取这个时间之前的最新的一个版本。
set @@tidb_snapshot="2020-02-02 16:45:26";
注意:
这里的时间设置的是 update 语句之前的那个时间。
在 tidb_snapshot 前须使用 @@ 而非 @,因为 @@ 表示系统变量,@ 表示用户变量。
7.这里读取到的内容即为 update 之前的内容,也就是历史版本:
select * from t;
8.清空这个变量后,即可读取最新版本数据:
set @@tidb_snapshot="";
select * from t;
4.3 整合Spark-TiSpark
4.3.1 准备数据
向 TiDB 集群中插入一些样本数据:
docker-compose exec tispark-master bash
cd /opt/spark/data/tispark-sample-data
mysql -h tidb -P 4000 -u root < dss.ddl
4.3.2 启动Spark shell
当样本数据加载到 TiDB 集群之后,访问 Spark shell。
docker-compose exec tispark-master /opt/spark/bin/spark-shell
...
Spark context available as 'sc' (master = local[*], app id = local-1527045927617).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_172)
Type in expressions to have them evaluated.
Type :help for more information.
4.3.3 执行Spark代码
scala> import org.apache.spark.sql.TiContext
...
scala> val ti = new TiContext(spark)
...
scala> ti.tidbMapDatabase("TPCH_001")
...
scala> spark.sql("select count(*) from lineitem").show
+--------+
|count(1)|
+--------+
| 60175|
+--------+
你也可以通过 Python 或 R 来访问 Spark:
docker-compose exec tispark-master /opt/spark/bin/pyspark
docker-compose exec tispark-master /opt/spark/bin/sparkR
下面执行另一个复杂一点的 Spark SQL:
scala> spark.sql(
"""select
| l_returnflag,
| l_linestatus,
| sum(l_quantity) as sum_qty,
| sum(l_extendedprice) as sum_base_price,
| sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
| sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
| avg(l_quantity) as avg_qty,
| avg(l_extendedprice) as avg_price,
| avg(l_discount) as avg_disc,
| count(*) as count_order
|from
| lineitem
|where
| l_shipdate <= date '1998-12-01' - interval '90' day
|group by
| l_returnflag,
| l_linestatus
|order by
| l_returnflag,
| l_linestatus
""".stripMargin).show
结果为:
+------------+------------+---------+--------------+--------------+
|l_returnflag|l_linestatus| sum_qty|sum_base_price|sum_disc_price|
+------------+------------+---------+--------------+--------------+
| A| F|380456.00| 532348211.65|505822441.4861|
| N| F| 8971.00| 12384801.37| 11798257.2080|
| N| O|742802.00| 1041502841.45|989737518.6346|
| R| F|381449.00| 534594445.35|507996454.4067|
+------------+------------+---------+--------------+--------------+
(续)
-----------------+---------+------------+--------+-----------+
sum_charge| avg_qty| avg_price|avg_disc|count_order|
-----------------+---------+------------+--------+-----------+
526165934.000839|25.575155|35785.709307|0.050081| 14876|
12282485.056933|25.778736|35588.509684|0.047759| 348|
1029418531.523350|25.454988|35691.129209|0.049931| 29181|
528524219.358903|25.597168|35874.006533|0.049828| 14902|
-----------------+---------+------------+--------+-----------+
4.4 数据迁移-TiDB Lightning
MySQL --> TiDB
4.4.1 TiDB Lightning介绍
TiDB Lightning 是一个将全量数据高速导入到 TiDB 集群的工具,目前支持 Mydumper 或 CSV 输出格式的数据源。你可以在以下两种场景下使用 Lightning:
1.迅速导入大量新数据。
2.备份恢复所有数据。
TiDB Lightning 主要包含两个部分:
1.tidb-lightning(“前端”):主要完成适配工作,通过读取数据源,在下游 TiDB 集群建表、将数据转换成键/值对 (KV 对) 发送到 tikv-importer、检查数据完整性等。
2.tikv-importer(“后端”):主要完成将数据导入 TiKV 集群的工作,把 tidb-lightning 写入的 KV 对缓存、排序、切分并导入到 TiKV 集群。

4.4.2 准备迁移工具
wget https://download.pingcap.org/tidb-enterprise-tools-latest-linux-amd64.tar.gz
wget https://download.pingcap.org/tidb-toolkit-latest-linux-amd64.tar.gz
4.4.3 准备MySQL数据
CREATE DATABASE mytest;
USE mytest;
CREATE TABLE mytest.t1 (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
c CHAR (32),
PORT INT
);
insert into t1 values (),(),(),(),(),(),(),();
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
update t1 set c=md5(id), port=@@port;
CREATE TABLE mytest.t2 (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
c CHAR (32),
PORT INT
);
insert into t2 values (),(),(),(),(),(),(),();
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
update t2 set c=md5(id), port=@@port;
4.4.4 导出数据
将数据导出到/data/my_database目录中
mkdir -p /data/my_database/
cd /export/servers/tidb-enterprise-tools-latest-linux-amd64/bin
./mydumper -h 127.0.0.1 -P 3306 -u root -p Root@1234 -t 16 -F 256 -B mytest -T t1,t2 --skip-tz-utc -o /data/my_database/
说明:
-B mytest :从 mytest 数据库导出。
-T t1,t2:只导出 t1 和 t2 这两个表。
-t 16:使用 16 个线程导出数据。
-F 256:将每张表切分成多个文件,每个文件大小约为 256 MB。
–skip-tz-utc:添加这个参数则会忽略掉 TiDB 与导数据的机器之间时区设置不一致的情况,禁止自动转换。
4.4.5 启动tikv-importer
cd /export/servers/tidb-toolkit-latest-linux-amd64/bin
vim tikv-importer.toml
# TiKV Importer 配置文件模版
# 日志文件。
log-file = "tikv-importer.log"
# 日志等级:trace、debug、info、warn、error、off。
log-level = "info"
[server]
# tikv-importer 监听的地址,tidb-lightning 需要连到这个地址进行数据写入。
addr = "192.168.1.101:8287"
[import]
# 存储引擎文档 (engine file) 的文件夹路径。
import-dir = "/mnt/ssd/data.import/"
nohup ./tikv-importer -C tikv-importer.toml > nohup.out &
4.4.6 启动tidb-lightning
vim run.sh
#!/bin/bash
nohup ./tidb-lightning \
--importer 192.168.1.101:8287 \
-d /data/my_database/ \
--pd-urls 0.0.0.0:2379 \
--tidb-host 192.168.1.101 \
--tidb-user root \
--log-file tidb-lightning.log \
> nohup.out &
chmod 755 run.sh
./run.sh
第五章 TiDB技术内幕
5.1 TiDB 技术内幕 - 存储
5.1.1 Key-Value
1.这是一个巨大的 Map,也就是存储的是 Key-Value pair
2.这个 Map 中的 Key-Value pair 按照 Key 的二进制顺序有序,也就是我们可以 Seek 到某一个 Key 的位置,然后不断的调用 Next 方法以递增的顺序获取比这个 Key 大的 Key-Value
5.1.2 RocksDB
任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV 也不例外。但是 TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是一个非常优秀的开源的单机存储引擎,可以满足我们对单机引擎的各种要求,而且还有 Facebook 的团队在做持续的优化,这样我们只投入很少的精力,就能享受到一个十分强大且在不断进步的单机引擎。当然,我们也为 RocksDB 贡献了一些代码,希望这个项目能越做越好。这里可以简单的认为 RocksDB 是一个单机的 Key-Value Map。
底层LSM树将对数据的修改增量保存在内存中,达到指定大小限制之后批量把数据flush到磁盘中,磁盘中树定期可以做merge操作,合并成一棵大树,以优化性能。
5.1.3 Raft
Raft 是一个一致性协议,提供几个重要的功能:
- Leader 选举
- 成员变更
- 日志复制
TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到 Group 的多数节点中。

到这里我们总结一下,通过单机的 RocksDB,我们可以将数据快速地存储在磁盘上;通过 Raft,我们可以将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。通过实现 Raft,我们拥有了一个分布式的 KV,现在再也不用担心某台机器挂掉了。
5.1.4 Region
对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:一种是按照 Key 做 Hash,根据 Hash 值选择对应的存储节点;另一种是分 Range,某一段连续的 Key 都保存在一个存储节点上.
TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,我们将每一段叫做一个 Region,并且我们会尽量保持每个 Region 中保存的数据不超过一定的大小(这个大小可以配置,目前默认是 64mb)。每一个 Region 都可以用 StartKey 到 EndKey 这样一个左闭右开区间来描述。
1.以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多
2.以 Region 为单位做 Raft 的复制和成员管理
5.1.5 MVCC
很多数据库都会实现多版本控制(MVCC),TiKV 也不例外。设想这样的场景,两个 Client 同时去修改一个 Key 的 Value,如果没有 MVCC,就需要对数据上锁,在分布式场景下,可能会带来性能以及死锁问题。 TiKV 的 MVCC 实现是通过在 Key 后面添加 Version 来实现,简单来说,没有 MVCC 之前,可以把 TiKV 看做这样的:
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
有了 MVCC 之后,TiKV 的 Key 排列是这样的:
Key1-Version3 -> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
……
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
……
KeyN-Version2 -> Value
KeyN-Version1 -> Value
……
注意,对于同一个 Key 的多个版本,我们把版本号较大的放在前面,版本号小的放在后面(回忆一下 Key-Value 一节我们介绍过的 Key 是有序的排列),这样当用户通过一个 Key + Version 来获取 Value 的时候,可以将 Key 和 Version 构造出 MVCC 的 Key,也就是 Key-Version。然后可以直接 Seek(Key-Version),定位到第一个大于等于这个 Key-Version 的位置。
5.1.6 事务
TiKV 的事务采用的是 Percolator 模型,并且做了大量的优化。TiKV 的事务采用乐观锁,事务的执行过程中,不会检测写写冲突,只有在提交过程中,才会做冲突检测,冲突的双方中比较早完成提交的会写入成功,另一方会尝试重新执行整个事务。当业务的写入冲突不严重的情况下,这种模型性能会很好,比如随机更新表中某一行的数据,并且表很大。但是如果业务的写入冲突严重,性能就会很差,举一个极端的例子,就是计数器,多个客户端同时修改少量行,导致冲突严重的,造成大量的无效重试。
5.2 TiDB 技术内幕 - 计算
5.2.1 关系模型到 Key-Value 模型的映射
TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID),其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。
每行数据按照如下规则进行编码成 Key-Value pair:
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]
对于 Index 数据,会按照如下规则编码成 Key-Value pair:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID
假设表中有 3 行数据:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
那么首先每行数据都会映射为一个 Key-Value pair,注意这个表有一个 Int 类型的 Primary Key,所以 RowID 的值即为这个 Primary Key 的值。假设这个表的 Table ID 为 10,其 Row 的数据为:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", "Manager", 30]
除了 Primary Key 之外,这个表还有一个 Index,假设这个 Index 的 ID 为 1,则其数据为:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
5.2.2 元信息管理
Database/Table 都有元信息,也就是其定义以及各项属性,这些信息也需要持久化,我们也将这些信息存储在 TiKV 中。每个 Database/Table 都被分配了一个唯一的 ID,这个 ID 作为唯一标识,并且在编码为 Key-Value 时,这个 ID 都会编码到 Key 中,再加上 m_ 前缀。这样可以构造出一个 Key,Value 中存储的是序列化后的元信息。
除此之外,还有一个专门的 Key-Value 存储当前 Schema 信息的版本。TiDB 使用 Google F1 的 Online Schema 变更算法,有一个后台线程在不断的检查 TiKV 上面存储的 Schema 版本是否发生变化,并且保证在一定时间内一定能够获取版本的变化(如果确实发生了变化)。
5.2.3 SQL on KV 架构
TiDB 的整体架构如下图所示
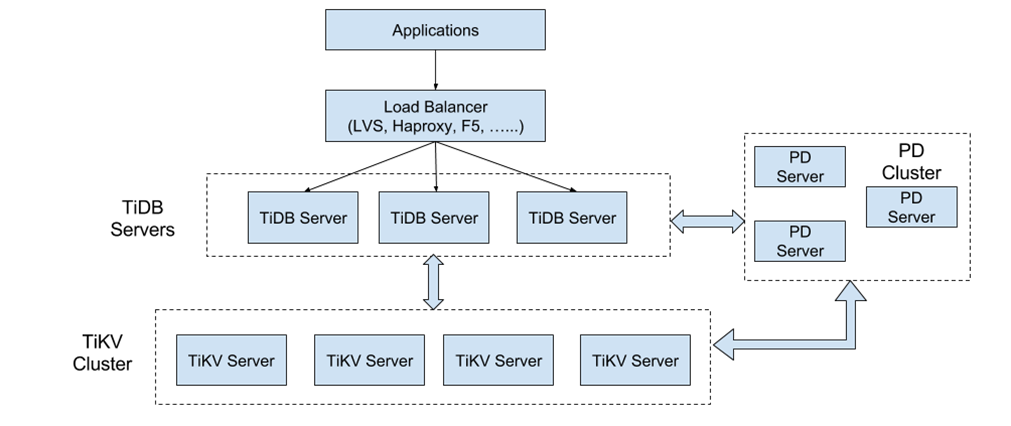
SQL层就是TiDB Servers,这一层节点都是无状态节点,本身并不存储数据,节点之间完全对等,主要的工作就是处理用户请求,执行SQL运算逻辑。
一个查询语句是如何操作底层存储的数据:
比如 Select count(*) from user where name=“TiDB”; 这样一个语句,我们需要读取表中所有的数据,然后检查 Name 字段是否是 TiDB,如果是的话,则返回这一行。这样一个操作流程转换为 KV 操作流程:
• 构造出 Key Range:一个表中所有的 RowID 都在 [0, MaxInt64) 这个范围内,那么我们用 0 和 MaxInt64 根据 Row 的 Key 编码规则,就能构造出一个 [StartKey, EndKey) 的左闭右开区间
• 扫描 Key Range:根据上面构造出的 Key Range,读取 TiKV 中的数据
• 过滤数据:对于读到的每一行数据,计算 name=“TiDB” 这个表达式,如果为真,则向上返回这一行,否则丢弃这一行数据
• 计算 Count:对符合要求的每一行,累计到 Count 值上面 这个方案肯定是可以 Work 的,但是并不能 Work 的很好,原因是显而易见的:
- 在扫描数据的时候,每一行都要通过 KV 操作同 TiKV 中读取出来,至少有一次 RPC 开销,如果需要扫描的数据很多,那么这个开销会非常大
- 并不是所有的行都有用,如果不满足条件,其实可以不读取出来
- 符合要求的行的值并没有什么意义,实际上这里只需要有几行数据这个信息就行
一个查询语句是如何进行分布式运算:
首先我们需要将计算尽量靠近存储节点,以避免大量的 RPC 调用。
其次,我们需要将 Filter 也下推到存储节点进行计算,这样只需要返回有效的行,避免无意义的网络传输。
最后,我们可以将聚合函数、GroupBy 也下推到存储节点,进行预聚合,每个节点只需要返回一个 Count 值即可,再由 tidb-server 将 Count 值 Sum 起来。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)