 网络拓扑结构-网络图的凝聚性特征
网络拓扑结构-网络图的凝聚性特征

前述网络基础概述
中提到,在数学中,“网络”(networks)通常被称为“图”(graphs),一个图G=(V,E)是一种包含“节点”集合V与“边”集合E的数学结构,其中E的元素是不同节点的无序组合{u,v},u,v∈V。同时,对网络的基础要点做了简介。
关于网络节点和边的特征,已在上篇作了简介,
本篇继续在网络整体或局部水平上描述网络图结构,以及关注用于描述网络图凝聚性的特征。
几种特殊的图类型
图有各种的“形状和尺寸”,以下简介几种特殊类型的图。
“完全图”(complete graph)是指每个节点与其它所有节点都有边连接的一类图。这一概念再实际中最有用的地方在于定义了一个“团”(或称“派系”,clique),即一个完全子图。
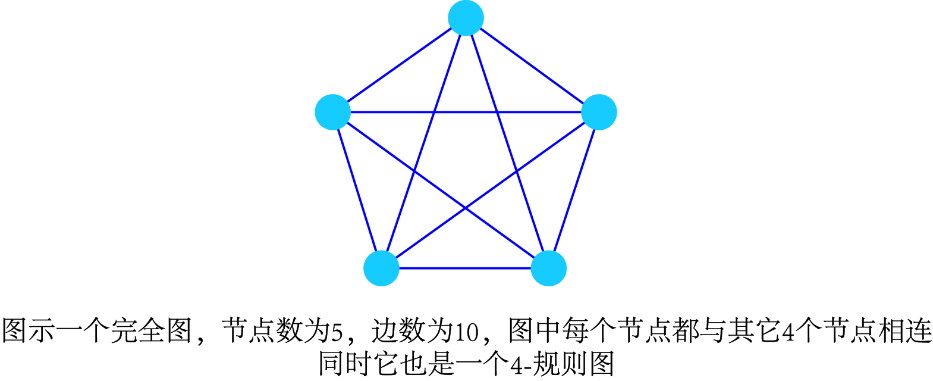
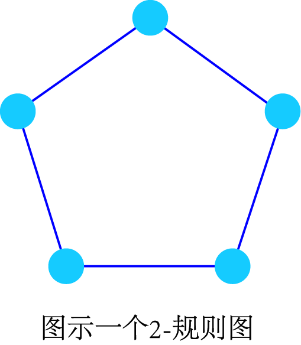
“规则图”(regular graph)是每个节点的度都相同的一类图。度均为d的规则图称为“d-规则”(d-regular)。
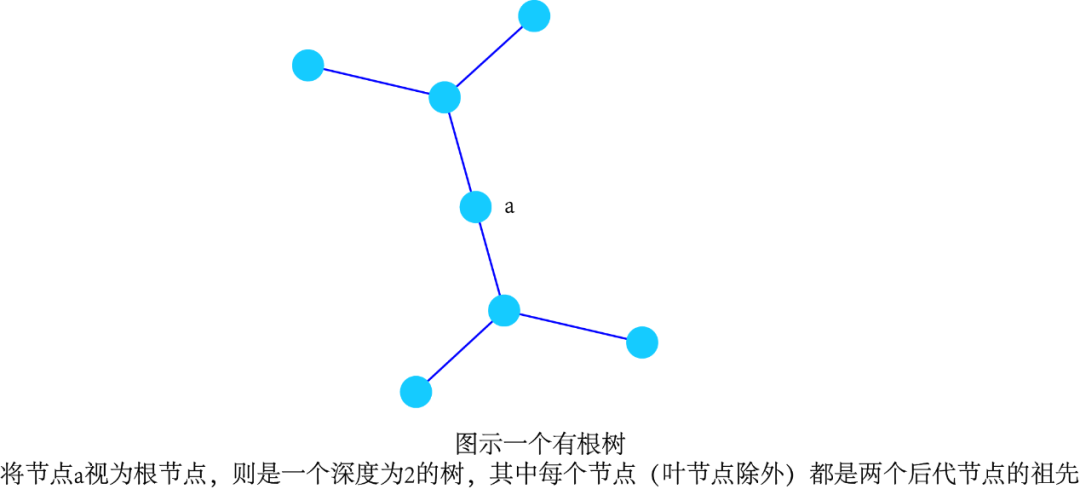
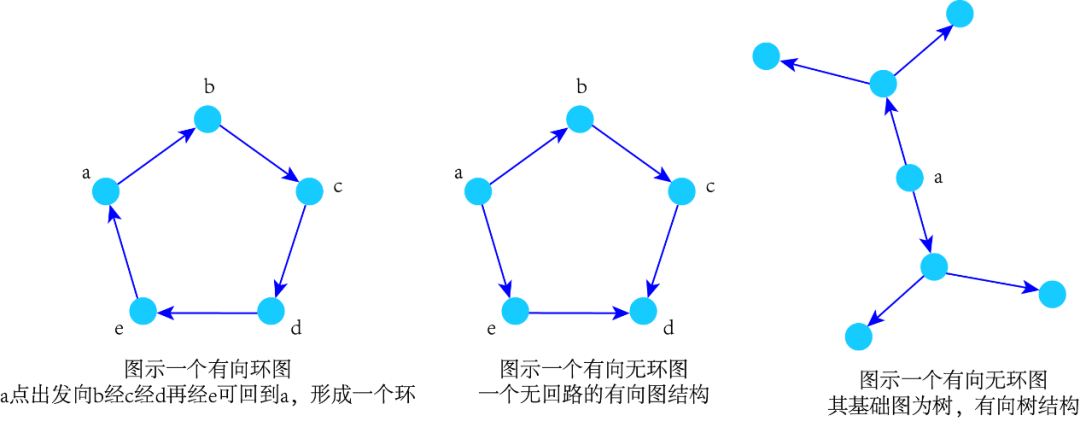
连通的无环图称为“树”(tree)。这种图的不相交的并集称为“森林”(forest)。树在网络分析中具有基础性的重要地位。比如,在许多算法的高效实现中,树是关键的数据结构。若一个有向图的基础图是树,则称其为“有向树”(directed tree)。这种树通常会有一个“根节点”(root)。这是唯一一个从其出发,总存在有向路径到达图中其它节点的特殊节点。这样的树称为一个“有根树”(rooted tree)。从根节点出发的路径中,某个节点之前的节点称为它的“祖先”(ancestor)节点,之后的节点称为它的“后代”(descendent)节点。直接相连的祖先节点称为“父节点”(parents),直接相连的后代节点称为“子节点”(children)。若一个节点不存在任何子节点,称为“叶节点”(leaf)。从根节点到最远的叶节点的距离称为树的“深度”(depth)。
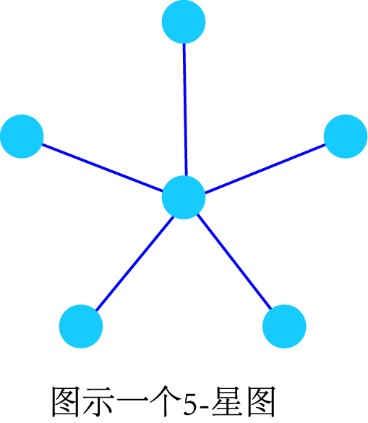
“k-星”(k-star)是一种树图的特殊情况,只包含一个根节点和k个叶节点。这种图对于抽象出一个节点及其直接相连邻居的关系(忽略邻居之间的连接)会很有用。
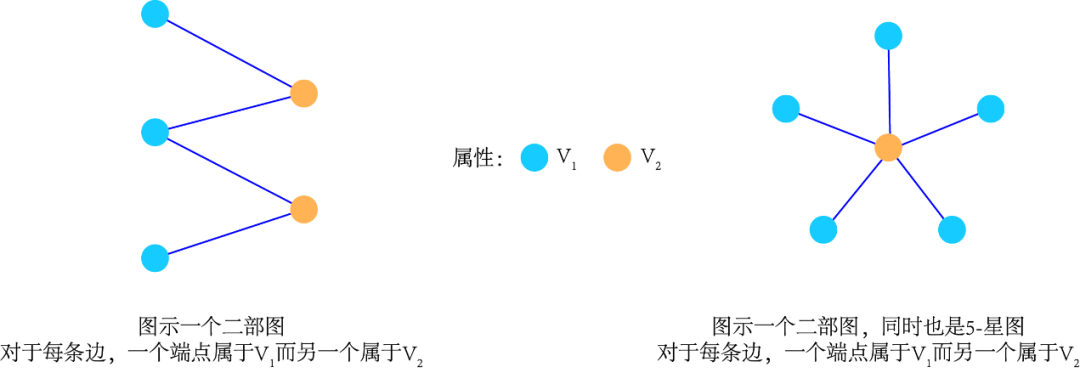
“二部图”(bipartite graph)是指图G=(V,E)中的节点集合V能够分为两个不相交的子集V1和V2,且E中每条边的一个端点属于V1而另一个属于V2。这类图通常被用于表示“成员”关系网络,例如用V1中的节点表示“成员”,用V2中的节点表示对应的“组织”。
“有向无环图”(directed acyclic graph,DAG)是树的概念的一般化推广。正如其名称,DAG是有向且不存在有向环的一类图。但与有向树不同,其基础不一定是树,因为将有向边替换为无向边的过程可能会产生包含环的图。在DAG上通常可以利用其类似树的结构这一特征,设计出高效的算法。
子图和团
网络分析中的许多问题与网络的凝聚性相关,即网络图中节点的子集与相应的边以何种程度聚合在一起。定义网络凝聚性特征的一种方法是规定某种感兴趣子图类型。
其中典型例子是团,上文提到,团是一类完全子图,集合内所有节点都由边相互连接,因而是完全凝聚的节点子集。所有尺寸的团的普查(census)可以提供一个“快照”,帮助了解图的结构。不过经常存在冗余问题,即大尺寸的团包含了小尺寸的团。“极大团”(maximal clique)是不被任何更大的团包含的一类图团。实际上,大尺寸的团很稀少,团的存在要求图G本身相当稠密,但现实世界的网络多是稀疏的。
团的概念存在各种弱化了条件的版本。例如,图G的k核(k-core)是一个图G的子图,其中所有节点的度至少为k,且不被包含于满足条件的其它子图中(即它是满足条件的最大的子图)。核的概念在可视化中非常流行,因为他提供了一种将网络分解到类似洋葱的不同“层”(layer)的方法。这种分解可以与辐射布局有效地结合起来。
在团及其变体之外,有一些其他类型子图可以用于定义网络凝聚性。二元组(dyad)和三元组(triad)是两个基本的量(Davis and Leinhardt, 1967; Holland and Leinhardt, 1970)。二元组关注两个节点,它们在有向图中有三种可能的状态:空(null,不存在边)、非对称(asymmetric,存在一条有向边)、双向(mutual,两条有向边)。类似地,三元组是三个节点,共有16种可能的状态(图下所示)。对图G中每个状态观察到的次数进行统计,得到的是这两类子图可能状态的一个普查,可以帮助深入理解图中连接的本质。
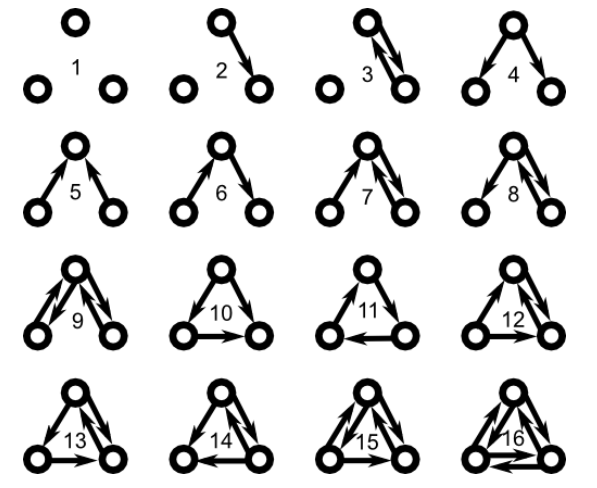
更一般些,原则上可以对任意感兴趣的子图进行普查。感兴趣的小型连通子图通常称为模体(motifs)。生物网络研究中模体是一个热门概念,通常将这类网络亚结构与生物的功能联系起来。
以及下文提到的“模块”等概念,也可视为一种“子图”类型。
在网络图中识别特定子图的示意,在图中对感兴趣的子图结构进行分析,可帮助深入理解图中连接的本质等。
网络连通性
网络图最基本的连通性概念是“邻接性”。当两个节点u,v∈V之间通过E中的一条边连接,称两者是“邻接的”(adjacent)。这些节点也可以被称为“邻居”(neighbors)。类似地,两条边e1,e2∈E若通过一个V中的共同端点相连,称两者是邻接的。当节点v∈V是边e∈E的一个断点时,称v与e是“关联的”(incident)。
另一个有用的概念用于描述与图相关的移动。例如,图G中,从v0到vl的“通路”(walk),是一个节点和边交替的序列{v0,e1,v1,e2,…,vl-1,el,vl},其中ei的端点是{vi-1,vi}。通路的“长度”(length)为l。对通路的概念继续完善,定义“迹”(trail)为不存在重复边的通路,以及“路径”(path)为不存在重复节点的通路。起点和终点相同的迹称为“回路”(circuit)。类似地,对于长度至少为3的通路,当其起点和终点相同但其它所有节点都不同时,称为“环”(cycle)。不存在环的图称为“无环的”(acyclic)。在有向图中,这些概念可以自然地通用。例如,从v0到vl的“有向通路”(directed walk),是v0和vl间通过有向边首尾相连的一个序列。
若图G中存在从节点u到另一个节点v的一条通路,则可以称节点v从u是“可达的”(reachable)。若所有节点从任一其他节点均可达,则称图G为“连通的”(connected)。图的“组件”(component)是一个最大化的连通子图,即它是图G的一个连通子图,且任意增加V中的一个剩余节点时都会破坏连通性。
与组件概念相比,一个更好的连通性定义源于以下问题:如果从图中任意移除包括k个节点(或边)的子集,剩余的子图是否还是连通的?这种思路可以使用节点和边连接通度的概念,以及节点和边的割等相关概念进行精确定义。若图G满足(1)节点数Nv>k,(2)移除基数|X|的任意节点子集X⊂V,得到的子图是连通的,则称图“k节点连通”(k-vertex-connected)。类似地,若(1)Nv≥2,且(2)移除基数|Y|的任意边的子集,得到的子图是连通的,则称图G是“k边连通”(k-edge-connected)。若图G是k节点(边)连通的,最大的整数k称为图的“节点(边)连通度”(vertex (edge) connectivity)。可以证明,节点连通度的上界为边连通度,而边连通度的上界为图G中节点的最小值dmin。如果移除图中的某个节点(边)的集合破坏了图的连通,这个集合称为“点割集(边割集)”(vertex-cut,edge-cut)。能破坏图连通性的单个节点称为“割点”(cut vertex),有时也称为“关节点”(articulation point)。
对于有向图,存在两种连通性概念。若图G的“基础图”(underlying graph,即从G中去除边的方向得到的图)是连通的,则称图为“弱连通”(weakly connected)。若每个节点v均可以从任一节点u通过有向通路到达,则称图为“强连通”(strongly connected)。
重要的网络拓扑属性
在这里,简介几种重要的网络拓扑属性,除了包含了用于描述网络凝聚性的特征外,还包含了用于描述网络规模等的特征。
平均度(Average degree)和平均加权度(Average weighted degree)
对网络整体而言,平均度(average degree)为该网络中所有节点的度的平均值;同样的,平均加权度(average weighted degree)为该网络中所有节点的加权度的平均值。平均度和平均加权度可反映网络整体的连通程度。
对于每个节点的度和加权度的定义,详见“节点和边特征”。
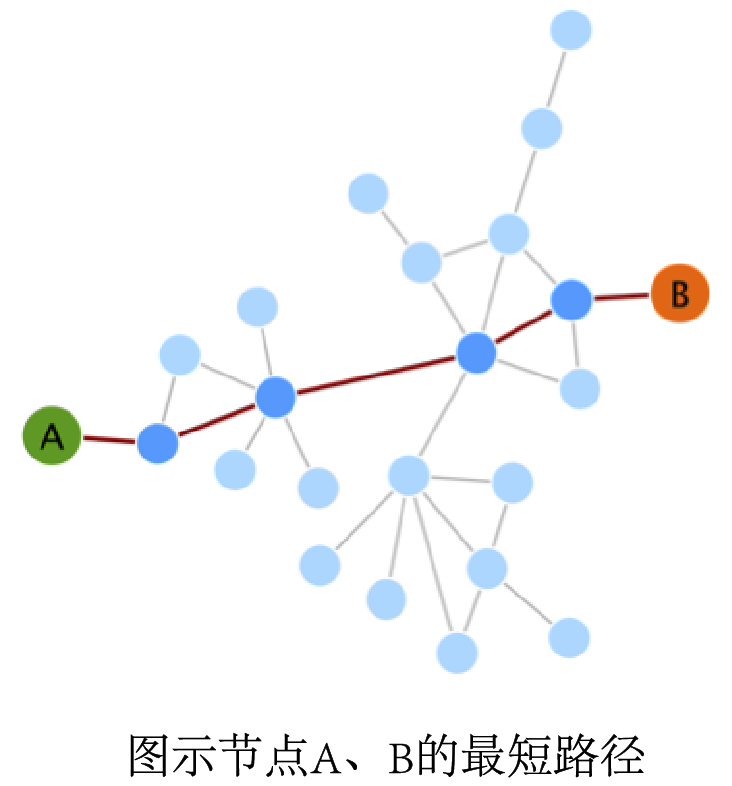
距离(Distance)和网络直径(Diameter)
网络图中节点间的“距离”(distance)这一概念,被定义为节点间最短路径的长度(若不存在路径则为正无穷)。这一距离也常被称为“捷径距离”(geodesic distance),其中“捷径”(geodesic)是最短路径的另一个名字。
网络图中最长的距离的值被称为图的“直径”(diameter)。网络直径可反映网络的规模。
图密度(Density)
一个图的“密度”(density)是指实际出现的边与可能的边的频数之比,反映了网络的凝聚性特征。例如,对于不存在自环和多重边的(无向)图G,子图H=(VH,EH)的密度为:
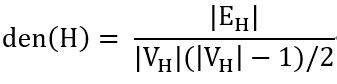
若为有向图,则:
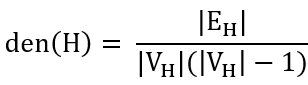
den(H)的值处于0到1之间,提供了一种H与团的接近程度的度量。由于子图H可以自由选择,这使简单的密度概念变得很有趣。例如,令H=G,得到的是整个图G的密度;而令H=Hv为节点v∈V的邻居集合以及节点间的边,度量的是v直接相邻邻居的密度。
聚类系数(clustering coefficient)
相对频率也可以用于定义图中的“聚集性”(clustering)概念,反映了网络的凝聚性特征。例如,术语“聚类系数”(clustering coefficient)的标准定义如下:
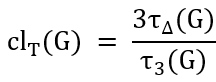
其中,τ∆ (G)指的是图G中三角形个数(三角形指尺寸为3的团),而τ3 (G)是连通的三元组(即由两条边连接的三个节点,有时也称为2-星,2-star)个数。clT (G)的值也被称为图的“传递性”(transitivity)。表示“传递性三元组的比例”。
注意,clT (G)是对全局聚集性的度量,所概括的是联通三元组闭合形成三角形的相对频率。
图分割(graph partitioning)和模块度(Modularity)
图分割(graph partitioning)问题在复杂网络方面的文献中也常被称为社团发现(community detection)问题。模块度(modularity)是社团发现中用来衡量社团划分质量的一种方法,一个相对好的结果在社团(community)内部的节点连接度较高,而在社团外部节点的连接度较低。
分割(partitioning)泛指将元素的集合划分到“自然的”子集之中的过程。更正式地,一个有限集S的分割ℒ={C1,…,CK}是将S分割为K个不相交的非空子集Ck,满足UKk=1Ck=S。在网络图的分析中,分割是一种无监督的方法,用于发现具有“凝聚性”的节点子集,揭示潜在的关系模式。开发社团发现的算法一直是研究的热点,算法有很多,如层次聚类、谱分割等,更多的领域综述可参考Fortunato等的文章(Fortunato and Lancichinetti, 2009)。
“凝聚性”节点子集一般指这样的节点集合:(1)内部联系紧密,(2)与其它节点相对分离。更正式地说,图分割算法通常试图寻找图G=(V,E)中节点集V的一个分割ℒ={C1,…,CK},使得连接Ck与Ck’之中节点的边集合E(Ck,Ck’)规模相对较小,而连接Ck内部节点的边集合E(Ck)=E(Ck,Ck)规模较大。
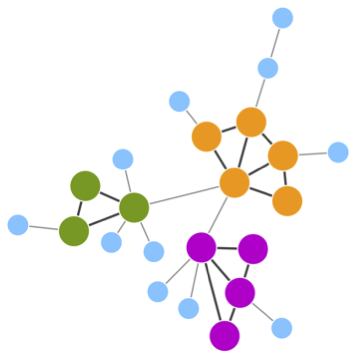
分割后的产生的各部分子图也常被称为“模块”(Module),各模块也常视为一种“子图”类型用于描述问题。如下展示了一例网络分割模块后的结果,其中按模块对节点着色。

同配混合(assortative mixing)
节点间依据某些特征进行选择性连接,被称为同配混合(assortative mixing),用于量化给定网络中同配程度的指标称为同配系数(assortativity coefficient),本质上是相关系数概念的一种变体。
需要注意的是,这里涉及的节点特征可以是分类、有序或者连续的变量。
考虑分类特征的情况:假设图G中每个节点可以使用M个类别中的一个进行标记,此时的同配系数定义为:
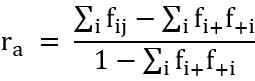
其中,fij是G中连接第i类节点与第j类节点的边所占的比例,而fi+和f+i分别是结果矩阵5f的边际行和与列和。
同配系数ra的值介于-1和1之间。当图的混合模式与保留边际度分布时随机分配边的结果一致,该值为0。类似地,当图的混合模式为完全同配(即边只连接同一类节点)时该值为1。但是,当混合模式为完全异配,即图中每条边连接的都是不同类型的节点时,上式中的系数不一定为-1。更多分析见Newman的综述(Newman, 2002)。
当感兴趣的节点特征为连续变量而非离散,使用(xe,ye)表示由一条边e∈E连接的两个节点的特征。量化这一特征同配性的一个自然选择是(xe,ye)的Pearson相关系数:
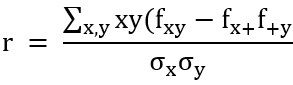
该值是对所有观察变量对(x,y)的概括,fxy、fx+和f+y的定义与分类变量类似,σx与 σy分别是{fx+}与{f+y}频率分布的标准差。
同配系数r经常在网络结构研究中用于概括相邻节点的度-度相关性。
互惠性(reciprocity)
有向图中独有的一个概念是“互惠性”(reciprocity),即有向网络中的边多大程度上是互惠的。计算相对频率的单位可以是二元组或者有向边,对应有两种表示这一概念的方法。当采用二元组作为基本单位,互惠性被定义为有互惠(双向)有向边的二元组数量,除以只有单一非互惠的二元组数量。另一种情况下,互惠性定义为互惠边的总数除以所有边的数量。
R语言获得网络拓扑结构
接下来,展示使用R的igraph包获得上述提到的重要网络拓扑特征的方法。
网络文件以邻接矩阵作为输入,文件基本格式及igraph包的入门操作可见前文网络基础概述。
示例数据和R代码链接(提取码:a2cu):
https://pan.baidu.com/s/1Pjee6jfVlm0lALHmP-t1bg
library(igraph)
#输入数据示例,邻接矩阵
#这是一个微生物互作网络,数值“1”表示微生物 OTU 之间存在互作,“0”表示无互作
adjacency_unweight head(adjacency_unweight)[1:6] #邻接矩阵类型的网络文件
#邻接矩阵 -> igraph 的邻接列表,获得非含权的无向网络
igraph = graph_from_adjacency_matrix(as.matrix(adjacency_unweight), mode = 'undirected', weighted = NULL, diag = FALSE)
igraph #igraph 的邻接列表

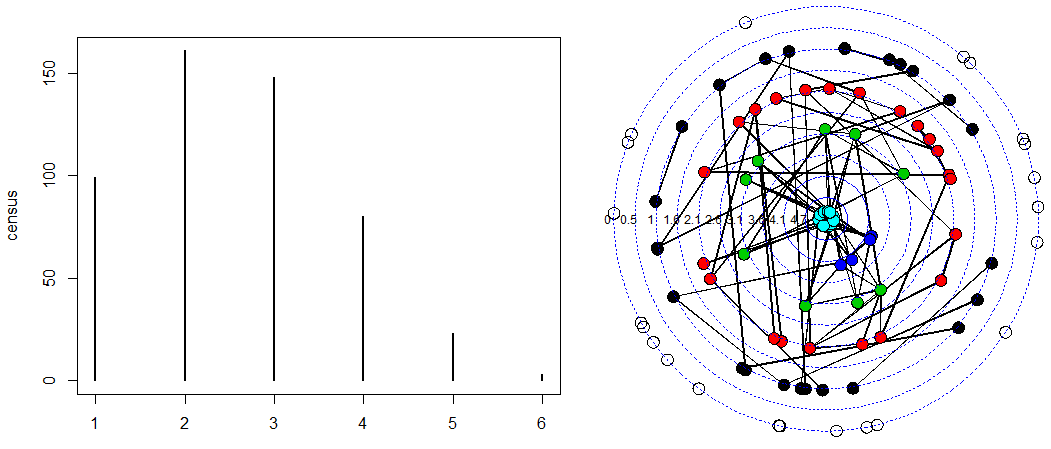
##子图与普查
#所有尺寸的团的普查可以提供一个快照,将显示各尺寸的团的数量
census census
plot(census)
#k 核
cores cores
sna::gplot.target(adjacency_unweight, cores, usearrows = FALSE, vertex.col = cores)
#二元组(dyad)和三元组(triad)
dyad.census(simplify(igraph))
triad.census(simplify(igraph))
#节点数量(number of nodes)和边数量(number of edges)
nodes_num nodes_num
edges_num edges_num
#平均度(average degree)
average_degree #或者,2x边数量/节点数量
average_degree average_degree
#平均加权度(average weighted degree),仅适用于含权网络
#average_weight_degree
#节点和边连通度(connectivity)
nodes_connectivity nodes_connectivity
edges_connectivity edges_connectivity
#平均路径长度(average path length)
average_path_length average_path_length
#网络直径(diameter)
graph_diameter graph_diameter
#图密度(density)
graph_density graph_density
#聚类系数(clustering coefficient)
clustering_coefficient clustering_coefficient
#介数中心性(betweenness centralization)
betweenness_centralization betweenness_centralization
#度中心性(degree centralization)
degree_centralization degree_centralization
#模块性(modularity),详见 ?cluster_fast_greedy,?modularity,有多种模型
fc modularity
#同配混合(assortative mixing),例如
otu_class V(igraph)$group assortativity.nominal(igraph, (V(igraph)$group == 'class2')+1, directed = FALSE)
#互惠性(reciprocity),仅适用于有向网络
#reciprocity(igraph, mode = 'default')
#reciprocity(igraph, mode = 'ratio')
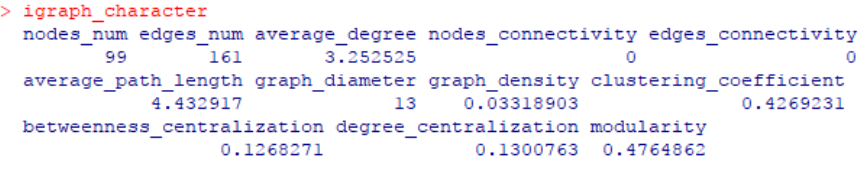
#选择部分做个汇总输出
igraph_character nodes_num, #节点数量(number of nodes)
edges_num, #边数量(number of edges)
average_degree, #平均度(average degree)
nodes_connectivity, #节点连通度(vertex connectivity)
edges_connectivity, #边连通度(edges connectivity)
average_path_length, #平均路径长度(average path length)
graph_diameter, #网络直径(diameter)
graph_density, #图密度(density)
clustering_coefficient, #聚类系数(clustering coefficient)
betweenness_centralization, #介数中心性(betweenness centralization)
degree_centralization, #度中心性
modularity #模块性(modularity)
)
igraph_character
write.table(igraph_character, 'igraph_character.txt', sep = '\t', row.names = FALSE, quote = FALSE)
参考资料
Eric D Kolacayk, Gabor Csardi,
网络数据的统计分析:
R
语言实践(李杨
译)
.
西安交通大学出版社
, 2016.
Math Insight:
https://mathinsight.org/index/general
Network analysis of protein interaction data: an introduction:
https://www.ebi.ac.uk/training/online/course/network-analysis-protein-interaction-data-introduction/graph-theory-some-basic-definitions
Network Centrality Measures and Their Visualization:
https://aksakalli.github.io/2017/07/17/network-centrality-measures-and-their-visualization.html
Davis J, Leinhardt S. The structure of positive interpersonal relations in small groups. J Berger Sociological Theories in Progress Volume, 1967:54.
Fortunato S, Lancichinetti A. Community detection algorithms: a comparative analysis: invited presentation, extended abstract. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2009, 80(2):056117.
Holland P W, Leinhardt S. A Method for Detecting Structure in Sociometric Data. American Journal of Sociology, 1970, 76(3):492-513.
Newman M E J. Mixing patterns in networks. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2002, 67(2):026126.
友情链接
相关性和网络分析基础
Pearson、Spearman、Kendall、Polychoric、Polyserial相关系数简介及R计算
网络分析概述之网络基础简介
网络拓扑结构-节点和边特征的简介和R计算
降维分析
非约束排序(描述性的探索性分析):
主成分分析(PCA):主成分分析(PCA) 同时含数值和分类变量的PCA
模糊主成分分析(FPCA)
对应分析(CA):对应分析(CA) 去趋势对应分析(DCA)
多重对应分析(MCA) 模糊对应分析(FCA)
主坐标分析(PCoA):主坐标分析(PCoA)
非度量多维标度分析(NMDS):非度量多维标度分析(NMDS)
非约束排序中被动添加解释变量
:
被动添加解释变量
约束排序(将解释变量通过回归方程拟合响应变量的统计模型):
冗余分析(RDA):冗余分析(RDA) 基于距离的冗余分析(db-RDA)
主响应曲线(PRC)
典范对应分析(CCA):典范对应分析(CCA)
RDA、CCA的R2校正及约束轴的显著性检验
RDA、CCA的解释变量选择
RD
A
、CCA的变差分解(VAP)
对称分析(这类方法意在描述两个或多个矩阵之间的相关性):
典范相关分析(CCorA)
协惯量分析(CoIA) 多重协惯量分析(MCoIA)
协对应分析(CoCA)
RLQ和第四角分析
多元因子分析(MFA)
监督降维(带监督的降维方法,常用于分类):
判别分析(DA)
聚类和分类
层次聚类(无监督,描述性的探索性分析):
层次聚合:层次聚合分类 层次聚类结果的比较和评估
层次分划:
双向指示种分析(TWINSPAN)
非层次聚类(无监督,描述性的探索性分析):
划分聚类:k均值划分(k-means) 围绕中心点划分(PAM)
模糊聚类:模糊c均值聚类(FCM)
避免不存在的类
潜变量分类(无监督,潜变量也可视为某种意义上的“降维”):
潜类别分析(LCA)
潜剖面分析(
LPA
)
约束聚类(无监督,将解释变量通过回归方程“约束”响应变量的模型):
多元回归树
监督分类(通过已知先验分组构建分类器模型):
决策树 随机森林分类
支持向量机分类
判别分析(DA):线性判别分析(LDA) 二次判别分析(QDA)

