论文
DeepPruner: Learning Efficient Stereo Matching via Differentiable PatchMatch
摘要
DeepPruner这篇文章,本人在2019年上半旬就大致读过一次,但是那时候脑袋里一直在想PatchMatch Stereo,加上又对深度学习不太了解,所以并没有搞懂这篇文章到底写了啥。现在又看了一篇,终于了解了,DeepPruner的核心其实就是深度裁剪,和PatchMatch其实没啥关系。。。
方法
下图展示了DeepPruner的整个结构,首先就是利用SPP从影像上提取特征,这个已经没啥好继续说的了。除此之外,其他比较重要的模块就是可微PatchMatch、深度范围估计和cost volumn回归,后边逐个展开说明一下。
注意,本人在看论文的时候,文章中只说了在什么地方用第一个阶段的可微PatchMatch,第二个没有介绍,这里需要看代码确认。

1. 可微PatchMatch
DeepPruner花费了大量的篇幅来讲这个模块,但是实际上和PatchMatch没啥关系。简单阐述这篇文章里是怎么做的(这里可能和论文有一点区别,个人感觉这样更容易理解,具体的可能还要看代码实现):
第一步,将视差范围分成
k
k
k份,保证视差取值的均匀性;
第二步,随机选取
i
i
i个视差,每份视差中只选取一个;
第三步,基于随机生成的视差构建cost,计算方法就是左右特征的点积;
第四步,每个像素逐个利用附近的4个像素的
i
i
i视差值和自己的
i
i
i视差值计算cost,共计
2
∗
i
2*i
2∗i个视差值,然后选出最大的
i
i
i个;
第五步,重复迭代步骤三、四一定次数;
第六步,使用soft max回归出最终的视差结果,计算公式如下:
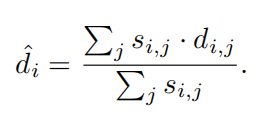
以上所有步骤如下图所示,展示了可微PatchMatch的整个过程。

2. 深度范围估计
深度范围估计是DeepPruner中Pruner的核心,但是文章中只用了一小段介绍。。。大致思路就是利用特征和可微PatchMatch预估出来的深度,为每一个像素估计一个大致的深度范围
R
=
[
l
,
u
]
R=[l,u]
R=[l,u]。
为啥DeepPruner比别的方法快,一个最重要的原因就是这里,提前裁剪掉大部分的深度值,保证后续进行代价聚合时,只需要在一个很小的范围里操作就可以了。
3. 代价聚合
基于前文估计的深度范围
R
R
R,作者构建了一个cost volumn;然后再使用了老方法( 三维卷积和refine模块)得到最终的预测结果。
loss
DeepPruner的输出挺多的,所以loss也稍显复杂,其整个公式如下,其中
y
c
o
s
t
y_{cost}
ycost是三维卷积后的结果,
y
r
e
f
i
n
e
y_{refine}
yrefine是优化的结果,
l
l
l是视差范围下限,
u
u
u是视差范围的上限。
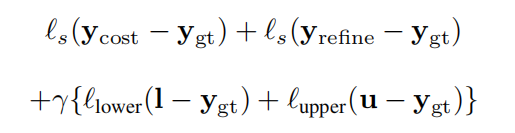
l
s
l_s
ls的计算,我们已经很熟悉了,公式也看了很多遍了,如下
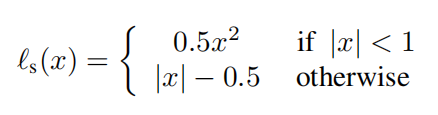
l
l
o
w
e
r
l_{lower}
llower和
l
u
p
p
e
r
l_{upper}
lupper让我想起了单目深度估计里的相对深度关系,公式如下,其中
0
<
λ
<
0.5
0<\lambda<0.5
0<λ<0.5,鼓励
l
<
g
t
,
u
>
g
t
l<gt,u>gt
l<gt,u>gt。

结果
总的来说,这篇文章还是非常棒的。但是我花了太久才看懂。。有空要跑跑代码。

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)