这两天学习cs231n的课程,顺便做一做该课程配套的作业。在assignment1中有遇到用multiclass SVM来对cifar10进行分类的问题。其中,为了进行训练,需要计算loss 和相关梯度。由于自己太菜,花了好长时间才完整梯度的求解。所以在这里记录一下具体的loss function关于权重参数矩阵W的求导过程。不足之处还请多多指教。
1. loss function
假设有训练数据 ,N为训练数据的个数,D为每个训练数据的维度。训练数据X对应于相应的标签
,N为训练数据的个数,D为每个训练数据的维度。训练数据X对应于相应的标签 .假设一共有类别数C。那么对于multiclass SVM来说,其loss function 可以表示如下:
.假设一共有类别数C。那么对于multiclass SVM来说,其loss function 可以表示如下:

其中,W为我们需要训练的权重,其维度为 。Xi 表示矩阵X的第i行,Wj表示矩阵W的第j列。yi表示数据Xi对应的正确标签值(对于cifar10 来说,总共有10类,yi的取值在0-9之间)。我们通过
。Xi 表示矩阵X的第i行,Wj表示矩阵W的第j列。yi表示数据Xi对应的正确标签值(对于cifar10 来说,总共有10类,yi的取值在0-9之间)。我们通过 来获得每一个数据在不同类别下的得分。
来获得每一个数据在不同类别下的得分。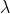 为正则项系数。
为正则项系数。
上式中max的含义是:对于第i个数据Xi与权重矩阵W的每一列Wj相乘,得到的是第i个数据对第j类的得分。只有Xi对正确的那一类yi的得分比其他类j的得分大1, 该部分的值才为0。否则,就有一个大于零的值加到loss函数中。
2. 两种计算梯度(导数)的形式
要求L对于W的梯度dW,就是求L对于W的导数。这里有两种形式。第一种是将W分成列,一次求解L对每一列的导数,这样累到一块就是L对W的导数;第二种方式是通过某种手段直接求L对W的梯度。接下来我们分别对这两种方法进行说明。
2.1 分块求解
通过式(1)可以看到,在很多情况下max得到的值是0,所以这种情况下导数为零。我们不妨将dW初始化为全零矩阵 dW=np.zeros([D,C]),然后只对非零部分进行修改即可。
当 时,式(1)就可以简化成如下形式:
时,式(1)就可以简化成如下形式:

下边我们对dW求解的前提都是基于。因为当这个条件不满足时,对应的dW为0。
按照前边所说,分块纠结就是依次对W的每一列求导。所以我们可以得到下式


此时,我们需要分两种情况讨论:
1、 当

2、 当 

注意,对于式(6),并不是单纯地将C-1个Xi相加。因为对于某个j,很有可能计算得到的 ,这种情况下得到的值是0。所以我们需要统计满足对应的j的个数,用这个系数乘Xi.
,这种情况下得到的值是0。所以我们需要统计满足对应的j的个数,用这个系数乘Xi.
下边放代码
def svm_loss_naive(W, X, y, reg):
"""
Structured SVM loss function, naive implementation (with loops).
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
dW = np.zeros(W.shape) # initialize the gradient as zero
# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in xrange(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in xrange(num_classes):
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
if j == y[i]:
continue #do nothing when j=y[i]
loss += margin #the loss would increase only when margin>0
dW[:,j]+=X[i].T #corresponding to equation(5)
dW[:,y[i]]+=-X[i].T #corresponding to equation(6). The condition margin>0 is satisfied, so it could be accumulated to d(L_i)/d(W_yi)
dW=dW/num_train #1/N
# Right now the loss is a sum over all training examples, but we want it
# to be an average instead so we divide by num_train.
loss /= num_train
# Add regularization to the loss. element-wise multiply
loss += reg * np.sum(W * W)
#############################################################################
# TODO: #
# Compute the gradient of the loss function and store it dW. #
# Rather that first computing the loss and then computing the derivative, #
# it may be simpler to compute the derivative at the same time that the #
# loss is being computed. As a result you may need to modify some of the #
# code above to compute the gradient. #
#############################################################################
dW=dW+2*reg*W #don't forget the derivation of regularization
return loss, dW
2.2 直接求解
通过2.1的分析,我们可以看出来,实际上dW中的元素都是由Xi构成的。所以我们可以考虑这样一个问题,是否存在一个矩阵M,使得Xi与M作用后可以直接得到dW。即 。 其中,
。 其中,  。
。
在2.1中,我们通过对i进行循环,通过X[i].dot(W)来算每一个数据Xi在各个类别下的得分。在这里,既然是直接求解,就不能用循环。我们直接用scores=X.dot(W) 来求得一个N*C的矩阵,里边存放着不同对数Xi对不同类别的得分,对应式(2)中的 。
。
然后,我们可以通过scores得到 。 代码实现为:
。 代码实现为:
X_correct_scores=scores[range(num_train),y].reshape(-1,1)
上边这一句的代码的含义是: y中存放着X中每一个数据Xi的正确标签值,且 ,num_train 在这里就是N。所以scores[range(num_train),y]实际上就是取出scores中 第i行,第yi列的数据。该数据就是Xi对于正确类别yi的得分。然后将得到是数据变成N*1的矩阵。
,num_train 在这里就是N。所以scores[range(num_train),y]实际上就是取出scores中 第i行,第yi列的数据。该数据就是Xi对于正确类别yi的得分。然后将得到是数据变成N*1的矩阵。
有了scores和X_correct_scores,我们就可以计算非常重要的 。这里将其结果记为margin. 对应的代码为:
。这里将其结果记为margin. 对应的代码为:
margin=scores-X_correct_scores+1
注意,这里得到的margin是包含了 这一项的。而原本的计算公式 式(2)中要求。 所以我们需要将margin中第i行, 第yi列减去1:
这一项的。而原本的计算公式 式(2)中要求。 所以我们需要将margin中第i行, 第yi列减去1:
margin[range(num_train),y]-=1
然后我们将margin中所有元素加和并求平均,再补充上正则项就可以求得loss function的值了。
此时,我们手中有一个margin矩阵,里边包含了我们所需要的重要信息——所有位置的 的值。通过2.1的分析我们知道,要求解dW,一个很重要的条件是,即margin>0。接下来,我们来看看如何用margin来构造矩阵M,从而直接求得dW。
我们首先通过:
sign=margin>0
来得到margin中各个位置的符号。sign为一个N*C的矩阵,里边的元素为True和False, 表示margin中对应位置的元素是否大于0.
然后我们可以通过sign来统计对于每一个Xi,有多少个Wj满足margin>0。这对我们求解式(6)即 非常重要:
非常重要:
mark=np.sum(sign,axis=1)
我们将sign按每一行相加,就可以得到每一个Xi对应的margin>0的个数。
此时,我想再强调一下各个矩阵的维度,方便理解:
 ,
,  , ,
, , 
其中N为数据X的个数, D为每一个数据Xi的维度, C为所有数据可能的类别。我们要通过X,margin,M来得到dW,为了满足矩阵乘法运算的维度要求,显然有 
![dW=[X_{1}^{T},X_{2}^{T}, \cdots, X_{N}^{T} ]_{D\times N} \left[ \begin{matrix} m_{11} & m_{12} & \cdots& m_{1C} \\ \vdots & \vdots & &\vdots \\ m_{N1}& m_{N2} & \cdots &m_{NC} \end{matrix} \right] _{N\times C}\tag{3}](https://private.codecogs.com/gif.latex?dW%3D%5BX_%7B1%7D%5E%7BT%7D%2CX_%7B2%7D%5E%7BT%7D%2C%20%5Ccdots%2C%20X_%7BN%7D%5E%7BT%7D%20%5D_%7BD%5Ctimes%20N%7D%20%5Cleft%5B%20%5Cbegin%7Bmatrix%7D%20m_%7B11%7D%20%26%20m_%7B12%7D%20%26%20%5Ccdots%26%20m_%7B1C%7D%20%5C%5C%20%5Cvdots%20%26%20%5Cvdots%20%26%20%26%5Cvdots%20%5C%5C%20m_%7BN1%7D%26%20m_%7BN2%7D%20%26%20%5Ccdots%20%26m_%7BNC%7D%20%5Cend%7Bmatrix%7D%20%5Cright%5D%20_%7BN%5Ctimes%20C%7D%5Ctag%7B3%7D)
1、 当
2、 当
当时,我们只需要margin中第i行第j列的元素大于零,此时 就为Xi,也就是说与Xi相乘的系数为1。所以M中第i行第j列的元素值为1. 举个例子: 对于i=1来说。 如果margin的第1行第2列的元素大于零(
就为Xi,也就是说与Xi相乘的系数为1。所以M中第i行第j列的元素值为1. 举个例子: 对于i=1来说。 如果margin的第1行第2列的元素大于零( ),则dW的第2列就存在X1,此时为了让dW的第二列存在X1,则m12应该为1。对于i=2来说,如果margin的第2行的第二列元素大于零(
),则dW的第2列就存在X1,此时为了让dW的第二列存在X1,则m12应该为1。对于i=2来说,如果margin的第2行的第二列元素大于零( ),则dW的第2列还应存在X2,此时,为了让dW第二列存在X2,则m22应该为1。而dW第二列中X1和X2应该相加起来,从而满足公式(3)。
),则dW的第2列还应存在X2,此时,为了让dW第二列存在X2,则m22应该为1。而dW第二列中X1和X2应该相加起来,从而满足公式(3)。
我们将M矩阵初始化为全零矩阵,然后对于margin大于零的部分,我们将在M矩阵的对应位置赋值为1。注意,margin大于零的部分已经排除了的可能。因为我们之前求解margin时,  的值为0。至此,我们解决了式(5)。具体的代码如下:
的值为0。至此,我们解决了式(5)。具体的代码如下:
M=np.zeros(sign.shape)
M=M+sign #sign中True的位置对应margin>0的部分,所以可以直接相加
下来我们来看式(6)的求解。
通过上边的讲解,我们可以推得,当时,与Xi相乘的系数不再是1,而是时,margin(i,j)>0的个数。前边通过mark,我们得到了margin每一行i中大于零的个数mark_i。然后我们将M矩阵对应的M(i,y_i)部分的系数改成-mark_i即可。具体代码如下:
M[range(num_train),y]=-mark
至此,我们就求得了M矩阵的所有元素。然后通过可以得到对应的dW。别忘记还有正则项的导数部分2*reg*W。
下边是完整的代码:
def svm_loss_vectorized(W, X, y, reg):
"""
Structured SVM loss function, vectorized implementation.
Inputs and outputs are the same as svm_loss_naive.
"""
loss = 0.0
dW = np.zeros(W.shape) # initialize the gradient as zero
num_train = X.shape[0]
num_type = W.shape[1]
#############################################################################
# TODO: #
# Implement a vectorized version of the structured SVM loss, storing the #
# result in loss. #
#############################################################################
scores = X.dot(W)
X_correct_scores=scores[range(num_train),y].reshape(-1,1)
margin=scores-X_correct_scores+1
margin[range(num_train),y]-=1
loss=np.sum(np.maximum(margin,0))/num_train+reg*np.sum(W*W)
#############################################################################
# END OF YOUR CODE #
#############################################################################
#############################################################################
# TODO: #
# Implement a vectorized version of the gradient for the structured SVM #
# loss, storing the result in dW. #
# #
# Hint: Instead of computing the gradient from scratch, it may be easier #
# to reuse some of the intermediate values that you used to compute the #
# loss. #
#############################################################################
sign=margin>0 #score>0的部分标记为true N*C
mark=np.sum(sign,axis=1) #N*1 对于每一个数据X[i],其得分大于0的个数。
M=np.zeros(sign.shape)
M[range(num_train),y]=-mark #当j=yi的时候,dLi/dw_yi 应该等于Xi*一个系数(即mark)
M=M+sign #对于margin大于零且j!=yi的部分(这部分已经除去了j=yi的情况。因为j=yi时,margin对应的部分等于0),系数为1
dW=X.T.dot(M)/num_train+2*reg*W
#############################################################################
# END OF YOUR CODE #
#############################################################################
return loss, dW
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)