IMM交互多模型介绍
- 1. 简介
- (1)IMM(Interacting Multiple Model)
- (2)马尔科夫概率转移矩阵
- 2. 算法流程
- (1)输入交互(模型j)
- (2)卡尔曼滤波(模型j)
- (3)模型概率更新
- (4)输出交互
1. 简介
(1)IMM(Interacting Multiple Model)
IMM算法采用多个Kalman滤波器进行并行处理。每个滤波器对应不同的状态空间模型,不同的状态空间模型描述不同的目标运行模式,所以每个滤波器对目标状态的估计结果不同。IMM算法的基本思想是在每一时刻,假设某个模型在现在时刻有效的条件下,通过混合前一时刻所有滤波器的状态估计值来获得与这个特定模型匹配的滤波器的初始条件,然后对每个模型并行实现正规滤波(预测和修正)步骤;最后,以模型匹配似然函数为基础更新模型概率,并组合所有滤波器修正后的状态估计值(加权和)以得到状态估计。因此IMM算法的估计结果是对不同模型所得估计的混合,而不是仅仅在每一个时刻选择完全正确的模型来估计。
(2)马尔科夫概率转移矩阵
假定某大学有1万学生,每人每月用1支牙膏,并且只使用“中华”牙膏与“黑妹”牙膏两者之一。根据本月(12月)调查,有3000人使用黑妹牙膏,7000人使用中华牙膏。又据调查,使用黑妹牙膏的3000人中,有60%的人下月将继续使用黑妹牙膏,40%的人将改用中华牙膏; 使用中华牙膏的7000人中, 有70%的人下月将继续使用中华牙膏,30%的人将改用黑妹牙膏。据此,可以得到如表-1所示的统计表。
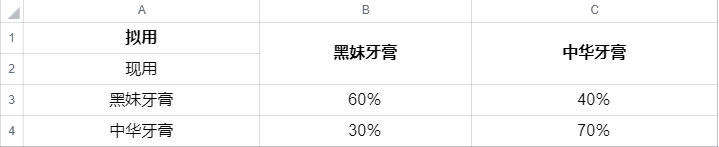
上表中的4个概率就称为状态的转移概率,而这四个转移概率组成的矩阵
P
=
[
60
%
40
%
30
%
70
%
]
P = \left[ \begin{array}{ccc} \ 60 \% & 40 \% \\ \ 30 \% & 70 \% \end{array} \right]
P=[ 60% 30%40%70%]
称为转移概率矩阵。可以看出, 转移概率矩阵的一个特点是其各行元素之和为1。 在本例中,其经济意义是:现在使用某种牙膏的人中,将来使用各种品牌牙膏的人数百分比之和为1。
用转移概率矩阵预测市场占有率的变化
有了转移概率矩阵,就可以预测,到下个月(1月份)使用黑妹牙膏和中华牙膏的人数,计算过程如下:
300060%+700030% = 3900个
300040%+700070% = 6100个
即:1月份使用黑妹牙膏的人数将为3900,而使用中华牙膏的人数将为6100个。
在IMM中,各模型之间的转移由马尔科夫概率转移矩阵确定,其中的元素
p
i
j
p_{ij}
pij表示目标由第
i
i
i个运动模型转移到第
j
j
j个运动模型的概率,概率转移矩阵如下:
P
=
[
p
11
.
.
.
p
1
r
.
.
.
.
.
.
.
.
.
p
r
1
.
.
.
p
r
r
]
P = \left[ \begin{array}{ccc} \ p_{11} & ...& p_{1r} \\ \ ... & ... &...\\ \ p_{r1}&...&p_{rr}\\ \end{array} \right]
P=⎣⎡ p11 ... pr1.........p1r...prr⎦⎤
2. 算法流程
IMM算法是以递推方式进行的,每次递推主要分为以下四个步骤:
(1)输入交互(模型j)
由目标的状态估计
X
i
^
(
k
−
1
∣
k
−
1
)
\hat{X_i}(k-1|k-1)
Xi^(k−1∣k−1)与上一步中每个滤波器的模型概率
μ
j
(
k
−
1
)
μ_j(k-1)
μj(k−1)得到混合估计
X
0
j
^
(
k
−
1
∣
k
−
1
)
\hat{X_{0j}}(k-1|k-1)
X0j^(k−1∣k−1)和协方差
P
0
j
(
k
−
1
∣
k
−
1
)
P_{0j}(k-1|k-1)
P0j(k−1∣k−1),将混合估计作为当前循环的初始状态。具体的参数计算如下:
模型j的预测概率(归一化常数)为
c
j
ˉ
=
∑
i
=
1
r
p
i
j
μ
i
(
k
−
1
)
\bar{c_j} = \sum_{{i=1}}^{r}p_{ij}μ_i(k-1)
cjˉ=i=1∑rpijμi(k−1)
模型
i
i
i到模型
j
j
j的混合概率
μ
i
j
(
k
−
1
∣
k
−
1
)
=
∑
i
=
1
r
p
i
j
μ
i
(
k
−
1
)
/
c
j
ˉ
μ_{ij}(k-1|k-1) = \sum_{i=1}^{r}p_{ij}μ_i(k-1)/\bar{c_j}
μij(k−1∣k−1)=i=1∑rpijμi(k−1)/cjˉ
模型j的混合状态估计
X
0
j
^
(
k
−
1
∣
k
−
1
)
=
∑
i
=
1
r
X
i
^
(
k
−
1
∣
k
−
1
)
μ
i
j
(
k
−
1
∣
k
−
1
)
\hat{X_{0j}}(k-1|k-1) = \sum_{i=1}^{r}\hat{X_i}(k-1|k-1)μ_{ij}(k-1|k-1)
X0j^(k−1∣k−1)=i=1∑rXi^(k−1∣k−1)μij(k−1∣k−1)
模型j的混合协方差估计
P
0
j
(
k
−
1
∣
k
−
1
)
=
∑
i
=
1
r
μ
i
j
(
k
−
1
∣
k
−
1
)
{
P
i
(
k
−
1
∣
k
−
1
)
+
[
X
i
^
(
k
−
1
∣
k
−
1
)
−
X
i
^
(
k
−
1
∣
k
−
1
)
]
∗
[
X
i
^
(
k
−
1
∣
k
−
1
)
−
X
i
^
(
k
−
1
∣
k
−
1
)
]
T
}
P_{0j}(k-1|k-1) = \sum_{i=1}^{r}μ_{ij}(k-1|k-1)\{P_i(k-1|k-1)\\+[\hat{X_i}(k-1|k-1) - \hat{X_i}(k-1|k-1)]*[\hat{X_i}(k-1|k-1) - \hat{X_i}(k-1|k-1)]^T\}
P0j(k−1∣k−1)=i=1∑rμij(k−1∣k−1){Pi(k−1∣k−1)+[Xi^(k−1∣k−1)−Xi^(k−1∣k−1)]∗[Xi^(k−1∣k−1)−Xi^(k−1∣k−1)]T}
式中,
p
i
j
p_{ij}
pij为模型
i
i
i到模型
j
j
j的转移概率;
μ
j
(
k
−
1
)
μ_j(k-1)
μj(k−1)为模型j在
k
−
1
k-1
k−1时刻的概率。
(2)卡尔曼滤波(模型j)
以
X
0
j
^
(
k
−
1
∣
k
−
1
)
\hat{X_{0j}}(k-1|k-1)
X0j^(k−1∣k−1)、
P
0
j
^
(
k
−
1
∣
k
−
1
)
\hat{P_{0j}}(k-1|k-1)
P0j^(k−1∣k−1)及
Z
(
k
)
Z(k)
Z(k)作为输入进行Kalman滤波,来更新预测状态
X
j
^
(
k
∣
k
)
\hat{X_j}(k|k)
Xj^(k∣k)和滤波协方差
P
j
(
k
∣
k
)
P_j(k|k)
Pj(k∣k)。
预测
X
j
^
=
Φ
j
(
k
−
1
)
X
0
j
^
(
k
−
1
∣
k
−
1
)
\hat{X_j} = Φ_j(k-1)\hat{X_{0j}}(k-1|k-1)
Xj^=Φj(k−1)X0j^(k−1∣k−1)
预测误差协方差
P
j
(
k
∣
k
−
1
)
=
Φ
j
P
0
j
(
k
−
1
∣
k
−
1
)
Φ
j
T
+
G
j
Q
j
G
j
T
P_j(k|k-1)=Φ_jP_{0j}(k-1|k-1)Φ_j^T+G_jQ_jG_j^T
Pj(k∣k−1)=ΦjP0j(k−1∣k−1)ΦjT+GjQjGjT
Kalman增益
K
j
(
k
)
=
P
j
(
k
∣
k
−
1
)
H
T
[
H
P
j
(
k
∣
k
−
1
)
H
T
+
R
]
−
1
K_j(k) = P_j(k|k-1)H^T[HP_j(k|k-1)H^T+R]^{-1}
Kj(k)=Pj(k∣k−1)HT[HPj(k∣k−1)HT+R]−1
滤波
X
j
(
k
∣
k
)
^
=
X
j
^
(
k
∣
k
−
1
)
+
K
j
(
k
)
[
Z
(
k
)
−
H
(
k
)
X
j
(
k
∣
k
−
1
)
]
\hat{X_j(k|k)} = \hat{X_j}(k|k-1) + K_j(k)[Z(k)-H(k)X_j(k|k-1)]
Xj(k∣k)^=Xj^(k∣k−1)+Kj(k)[Z(k)−H(k)Xj(k∣k−1)]
滤波协方差
P
j
(
k
∣
k
)
=
[
I
−
K
j
(
k
)
H
(
k
)
]
P
j
(
k
∣
k
−
1
)
P_j(k|k) = [I - K_j(k)H(k)]P_j(k|k-1)
Pj(k∣k)=[I−Kj(k)H(k)]Pj(k∣k−1)
(3)模型概率更新
采用似然函数来更新模型概率
μ
j
(
k
)
μ_j(k)
μj(k),模型j的似然函数为
Λ
j
(
k
)
=
1
(
2
π
)
n
/
2
∣
S
j
(
k
)
∣
1
/
2
e
x
p
{
−
1
2
ν
j
T
S
j
−
1
(
k
)
ν
j
}
Λ_j(k) = \frac{1}{(2π)^{n/2}|S_j(k)|^{1/2}}exp\{-\frac{1}{2}ν_j^{T}S_j^{-1}(k)ν_j\}
Λj(k)=(2π)n/2∣Sj(k)∣1/21exp{−21νjTSj−1(k)νj}
式中,
ν
j
(
k
)
=
Z
(
k
)
−
H
(
k
)
X
j
^
(
k
∣
k
−
1
)
ν_j(k) = Z(k) - H(k)\hat{X_j}(k|k-1)
νj(k)=Z(k)−H(k)Xj^(k∣k−1)
S
j
(
k
)
=
H
(
k
)
P
j
(
k
∣
k
−
1
)
H
(
k
)
T
+
R
(
k
)
S_j(k) = H(k)P_j(k|k-1)H(k)^T+R(k)
Sj(k)=H(k)Pj(k∣k−1)H(k)T+R(k)
则模型
j
j
j的概率为
μ
j
(
k
)
=
Λ
j
(
k
)
c
j
ˉ
/
c
μ_j(k) = Λ_j(k)\bar{c_j}/c
μj(k)=Λj(k)cjˉ/c
式中,
c
c
c为归一化常数,且
c
=
∑
j
=
1
r
Λ
j
(
k
)
c
j
ˉ
c = \sum_{j=1}^{r}Λ_j(k)\bar{c_j}
c=∑j=1rΛj(k)cjˉ。
(4)输出交互
基于模型概率,对每个滤波器的估计结果加权合并,得到总的状态估计
X
^
(
k
∣
k
)
\hat{X}(k|k)
X^(k∣k)和总的协方差估计
P
(
k
∣
k
)
P(k|k)
P(k∣k)。
总的状态估计
X
^
(
k
∣
k
)
=
∑
j
=
1
r
X
j
^
(
k
∣
k
)
μ
j
(
k
)
\hat{X}(k|k) = \sum_{j=1}^{r}\hat{X_j}(k|k)μ_j(k)
X^(k∣k)=j=1∑rXj^(k∣k)μj(k)
总的协方差估计
P
(
k
∣
k
)
=
∑
j
=
1
r
μ
j
(
k
)
{
P
j
(
k
∣
k
)
+
[
X
j
^
(
k
∣
k
)
−
X
^
(
k
∣
k
)
]
∗
[
X
j
(
k
∣
k
)
−
X
^
(
k
∣
k
)
^
]
T
}
P(k|k) = \sum_{j=1}^{r}μ_j(k)\{P_j(k|k)+[\hat{X_j}(k|k) - \hat{X}(k|k)]*[\hat{X_j(k|k)- \hat{X}(k|k)}]^T\}
P(k∣k)=j=1∑rμj(k){Pj(k∣k)+[Xj^(k∣k)−X^(k∣k)]∗[Xj(k∣k)−X^(k∣k)^]T}
所以,滤波器的总输出是多个滤波器估计结果的加权平均值。权重即为该时刻模型正确描述目标运动的概率,简称为模型概率。
选取滤波器的目标运动模型,可以从下面3个方面考虑:
①选择一定个数的IMM滤波器,包括较为精确的模型和较为粗糙的模型。IMM滤波算法不仅描述了目标的连续运动状态,而且描述了目标的机动性。
②马尔科夫链状态转移概率的选取对IMM滤波器的性能有较大影响。马尔科夫链状态转移概率矩阵实际上相当于模型状态方程的状态转移矩阵,它将直接影响模型误差和模型概率估计的准确性。一般情况下,当马尔科夫链状态转移概率呈现一定程度的模型性时,IMM滤波器能够更稳健地描述目标运动。
③IMM滤波算法具有模块化的特性。当对目标的运动规律较为清楚时,滤波器可以选择能够比较精确地描述目标运动的模型。当无法预料目标的运动规律时,就应该选择更一般的模型,即该模型应具有较强的鲁棒性。
注意:关于“牙膏”的例子通俗介绍了什么是马尔科夫转移矩阵,例子中涉及到的“转移”是在时间序列上的转移,但是在IMM的输入交互步骤中,“转移”更多的是一种空间状态的转移,是我们为了混合模型而对模型进行“转移”,进而实现模型的混合。其中,模型j的预测概率(归一化常数)为IMM中每个滤波器模型向模型j转移之后得到的概率,它是一种“混合态”概率。如假设IMM使用了两个滤波器,马尔科夫转移矩阵如下:
P
=
[
0.98
0.02
0.02
0.98
]
P = \left[ \begin{array}{ccc} \ 0.98 & 0.02 \\ \ 0.02 & 0.98 \end{array} \right]
P=[ 0.98 0.020.020.98]
滤波器1的概率为0.8,滤波器2的概率为0.2,则滤波器1的预测概率经过状态“转移”之后由两部分组成,一部分来自于转移前的滤波器1,值为
p
00
∗
0.8
=
0.784
p_{00}*0.8 = 0.784
p00∗0.8=0.784;另一部分来自滤波器2,值为
p
10
∗
0.2
=
0.004
p_{10}*0.2 = 0.004
p10∗0.2=0.004,最终,滤波器1的预测概率为0.788。进一步,模型i到模型j的混合概率指的是得到模型j的预测概率过程中,模型i贡献了多少百分比。对应到上例中,模型0到模型0的混合概率为
0.784
/
0.788
=
0.99492
0.784/0.788=0.99492
0.784/0.788=0.99492;模型1到模型0的混合概率为
0.004
/
0.788
=
0.005076
0.004/0.788=0.005076
0.004/0.788=0.005076,这也是模型j的预测概率被称为归一化常数的原因。以上均是模型混合过程中关于概率的操作,概率与状态相乘则得到“混合态”状态,如模型0的混合状态估计
X
0
j
^
(
k
−
1
∣
k
−
1
)
\hat{X_{0j}}(k-1|k-1)
X0j^(k−1∣k−1)等于模型0的状态估计
X
0
^
(
k
−
1
∣
k
−
1
)
\hat{X_0}(k-1|k-1)
X0^(k−1∣k−1)乘以模型0到模型0的混合概率与模型1的状态估计
X
1
^
(
k
−
1
∣
k
−
1
)
\hat{X_1}(k-1|k-1)
X1^(k−1∣k−1)乘以模型1到模型0的混合概率之和。
模型
j
j
j的混合协方差估计与混合状态估计类似,但需要注意的是公式中加上了概率转移过程中产生的协方差。
模型概率更新公式中,
ν
j
(
k
)
ν_j(k)
νj(k)为观测值与先验估计之差,该值越大,意味着滤波器
j
j
j预测的值与实际值偏差比较大,即该滤波器的表现不好,进一步
Λ
j
(
k
)
Λ_j(k)
Λj(k)越小,模型
j
j
j的概率越小。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)