iret
实现过程
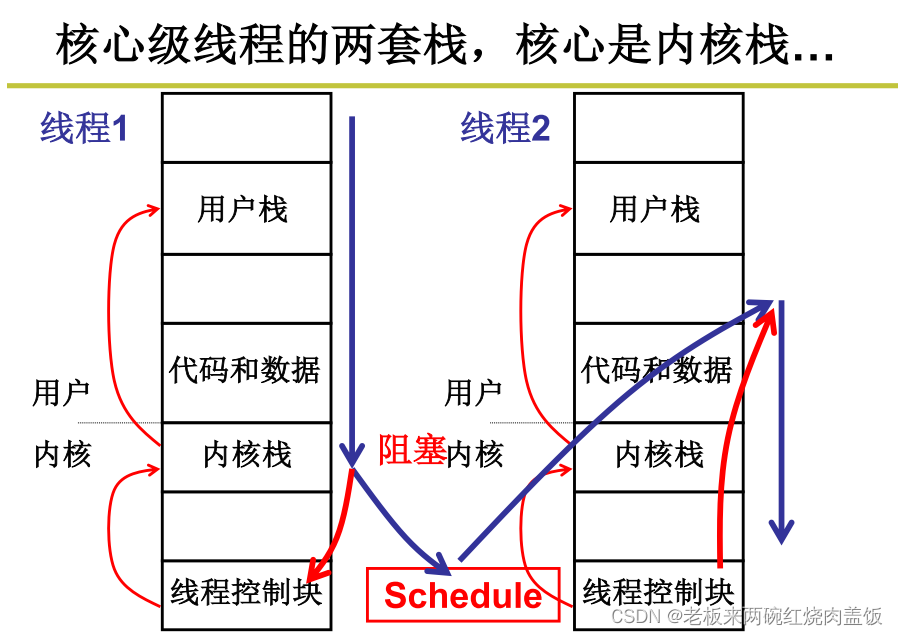
前面的东西都是用户态的,所以需要把用户态的东西在内核态中保存起来
将来返回的时候还需要用到
按照老师的意思,这里严格来说仍然处于用户态,在做进入内核态的准备工
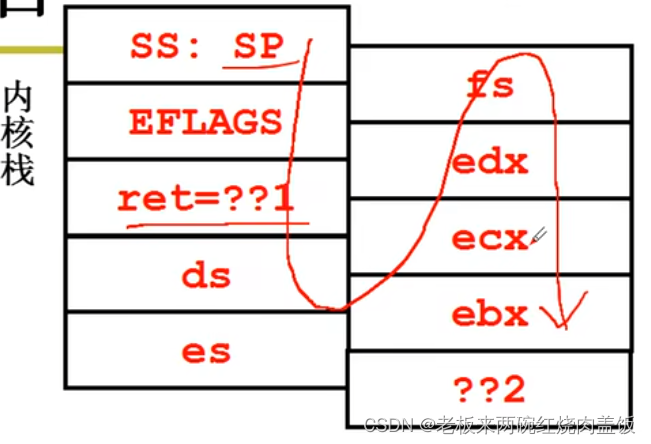
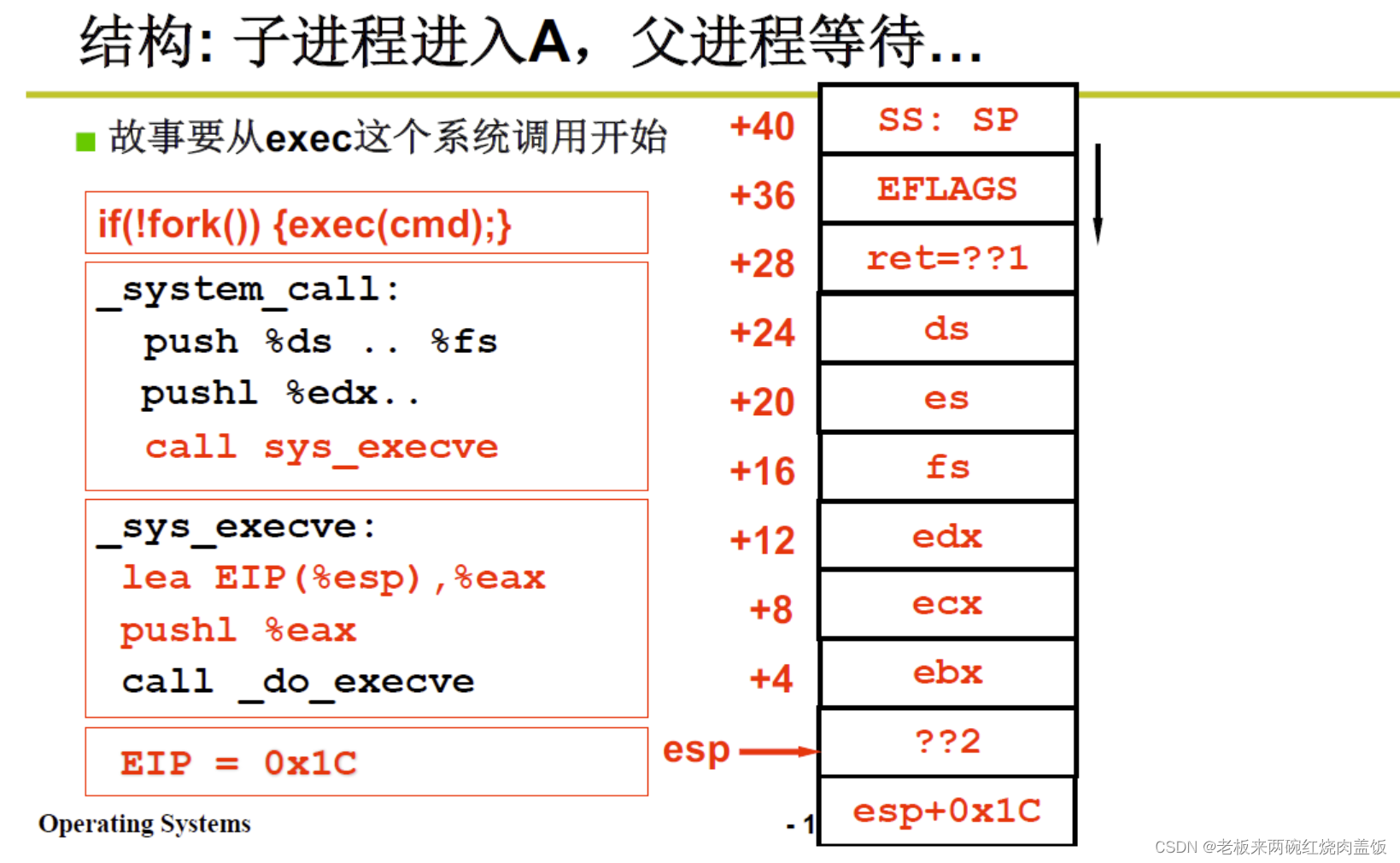
首先会将当前用户态的寄存器等数据放入内核栈中(保存现场),push%ds…%fs,pushl%edx等等,要把用户态的信息保存,因为以后还要返回
push%ds…%fs,pushl%edx
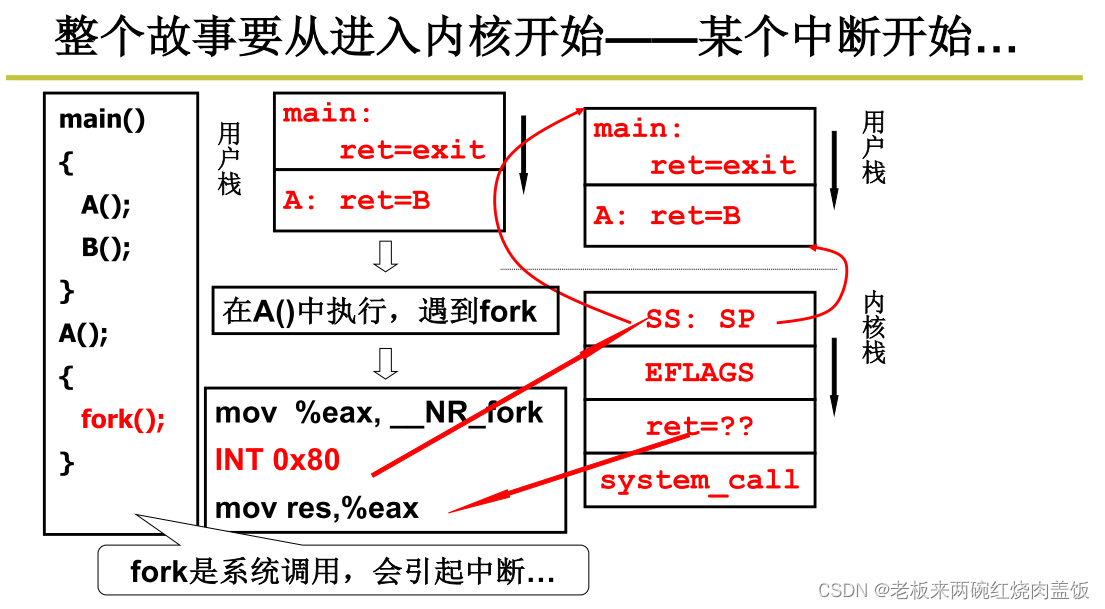
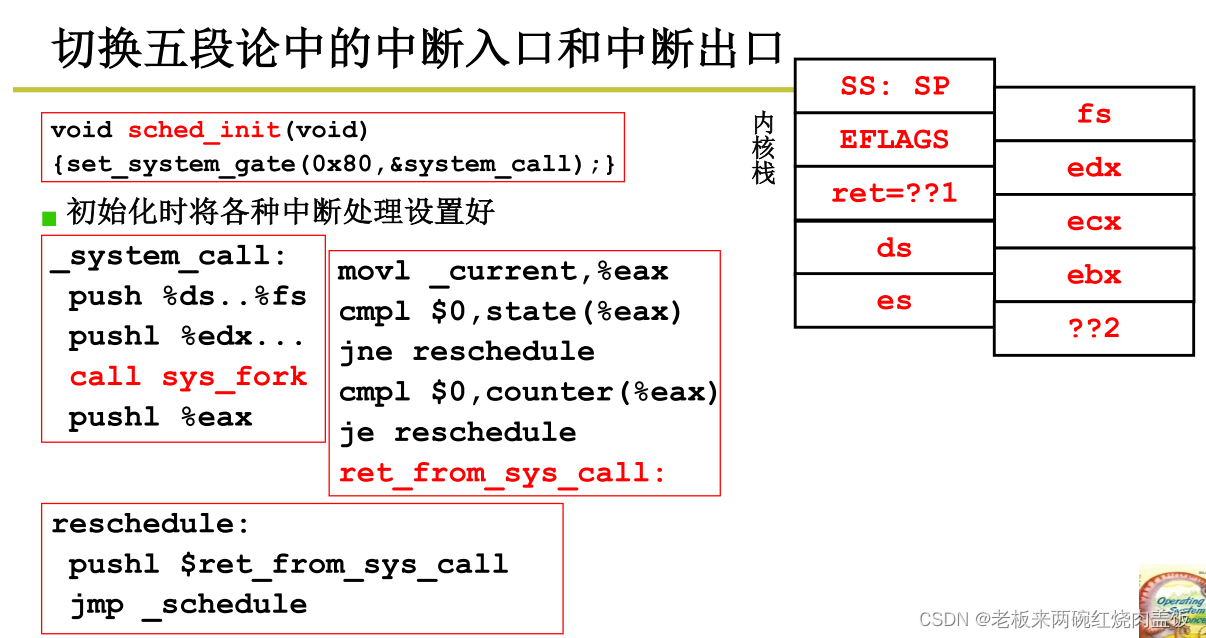
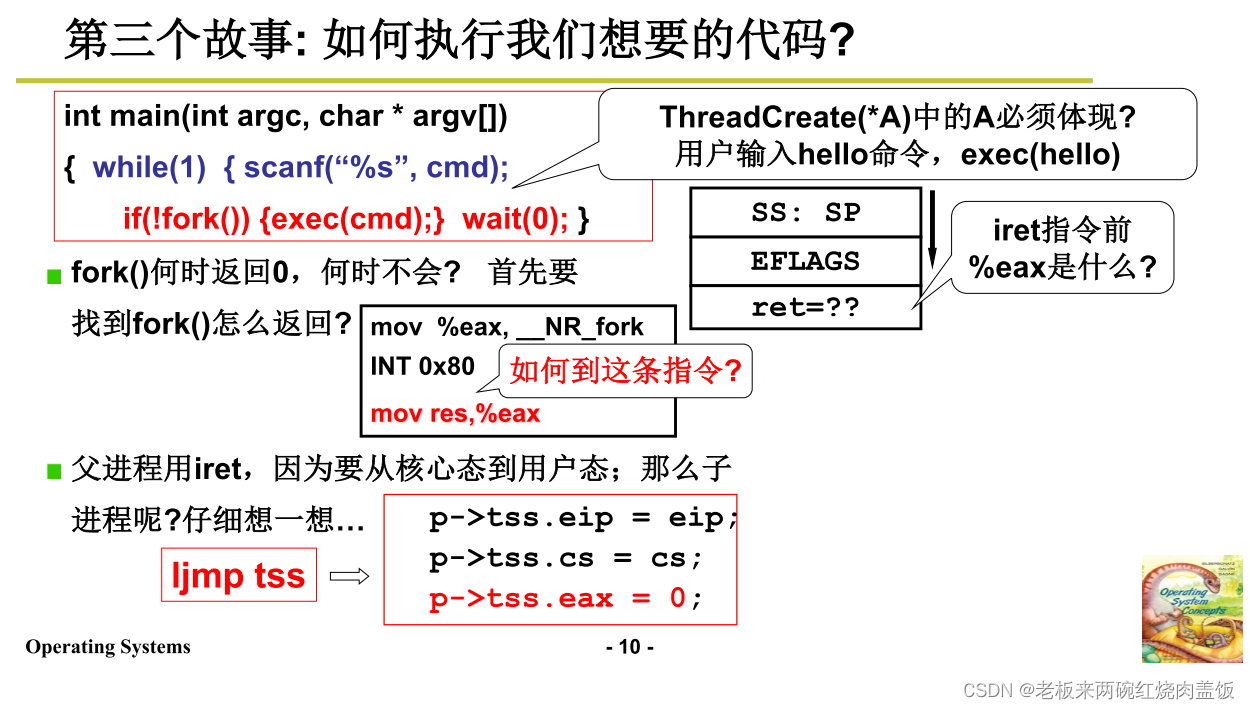
切换有五段论,第一段是中断入口,实际上就是建立内核栈与用户栈之间的关联 之后进入内核,在内核中会执行,在执行的时候会发现,某些进程/线程可以不执行,比如说在内核当中发现某进程是启动磁盘读,那可以不让你读,这个时候就会引发切换,所以说在内核中的时候会判断一个事件来引发切换,判断这个事件来引发切换,这就是内核级线程五段论之间的中间三段,在sys_fork执行过程当中,会发现不要执行,但是sys_read之类发现磁盘已经读写了,必须等待。
sys_fork
cmp $0, state(%eax)
ret_from_sys_call
c
schedule
schedulel
reschedule
pop
ret_from_sys_cal
next
switch_to
ljmp %0\n\t
ljmp %0
ljmp
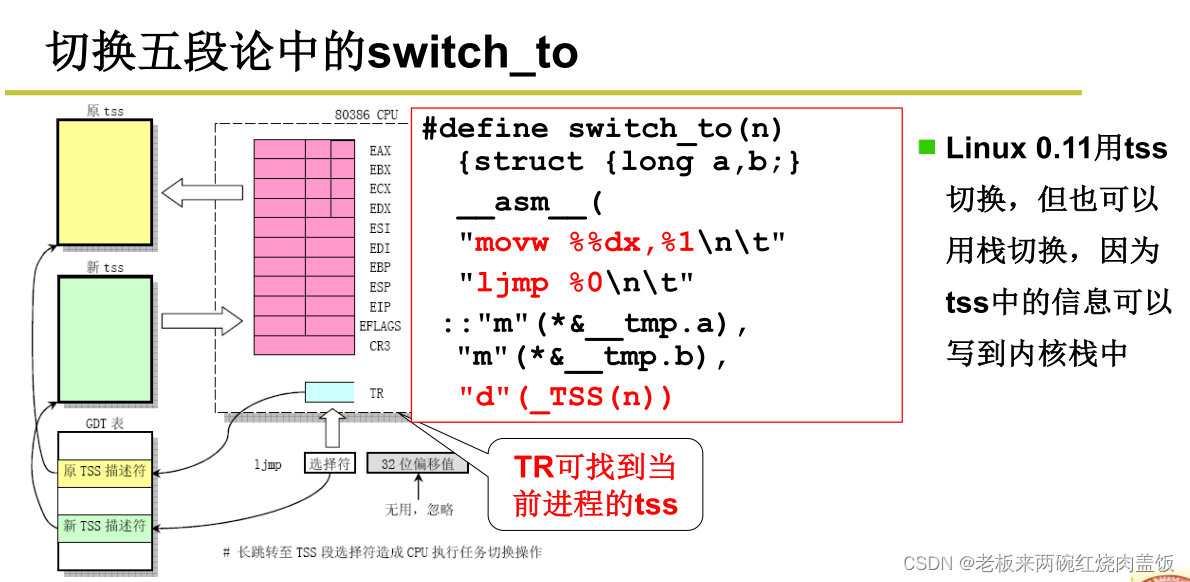
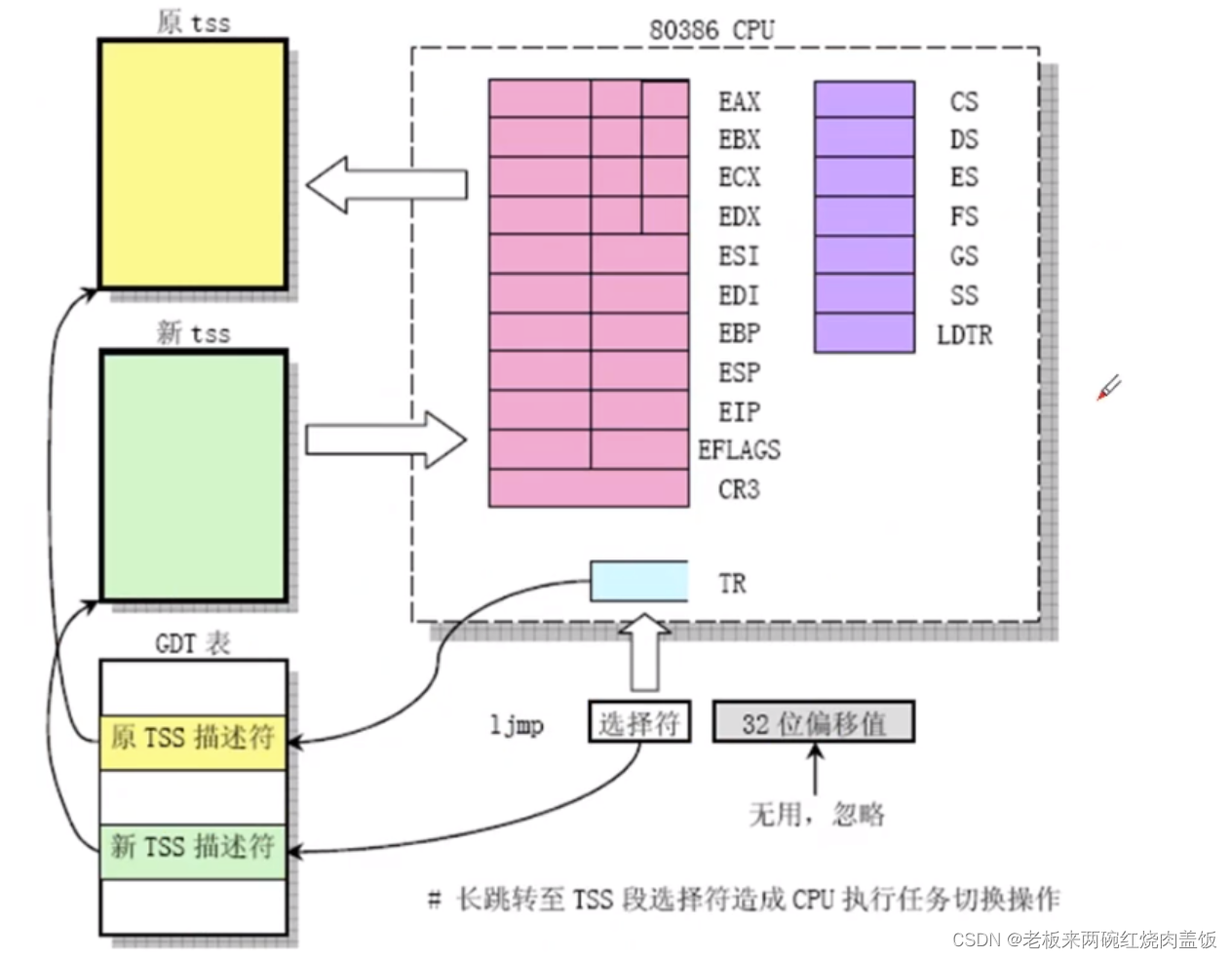
下图中,ljmp指令是长跳转指令,即TSS段的跳转切换,使用TR寄存器+GDT表,在上一张图中画了,TR是TSS段的选择符,拿这个选择符去查GDT表,找到对应的TSS描述符,这个TSS描述符指向了TSS的内容。下图中,n表示调度选择的下一个进程编号,那么TSS(n)就是下一个进程对应的cs,指向下一个进程的TSS后,就把其中的数据赋给寄存器等,恢复现场
int
(1)ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。 (2)EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
??4
call _copy_process
addl $20, %esp
??2
call _sys_fork
pushl %eax
int 0x80
_sys_fork
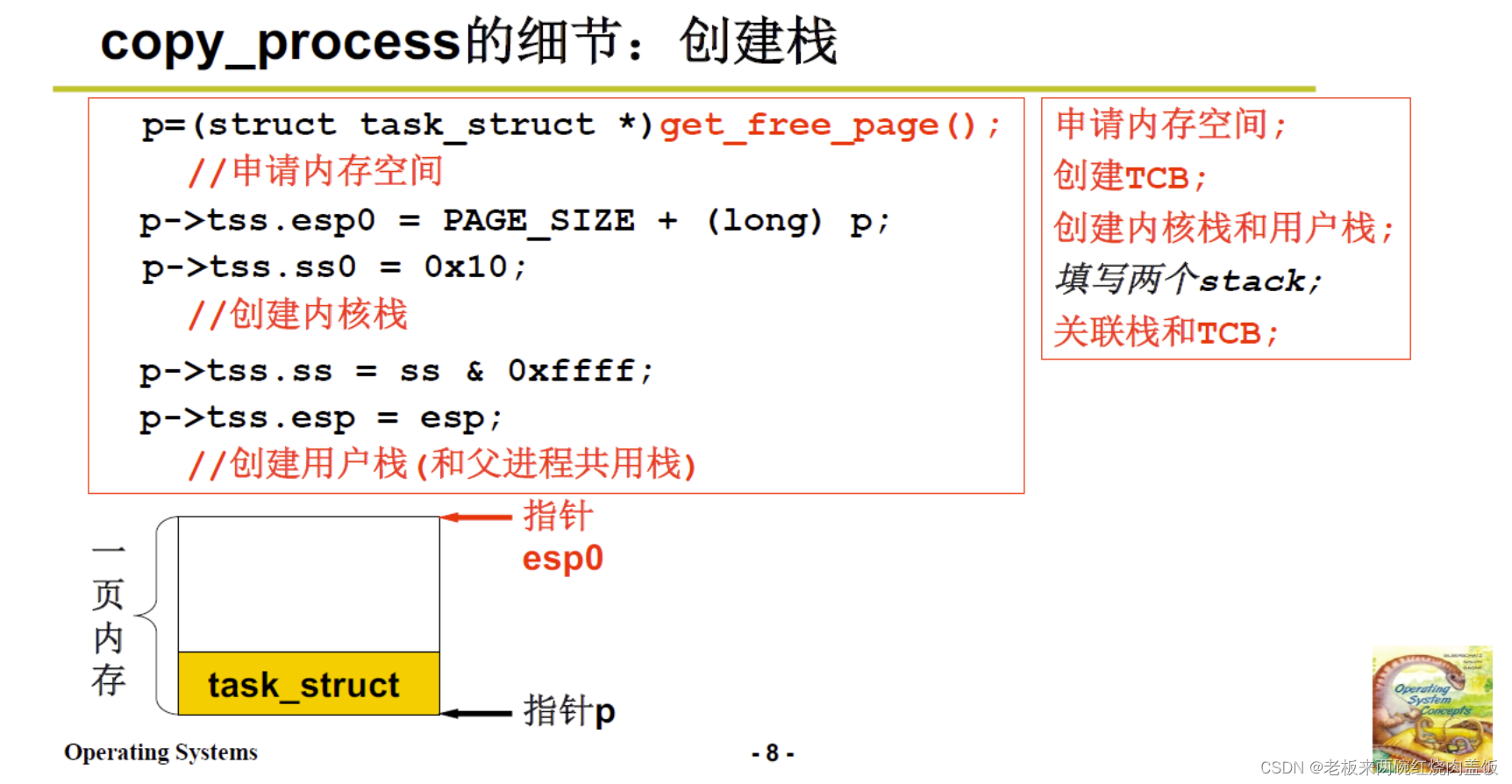
copy_process的细节:创建子进程的栈
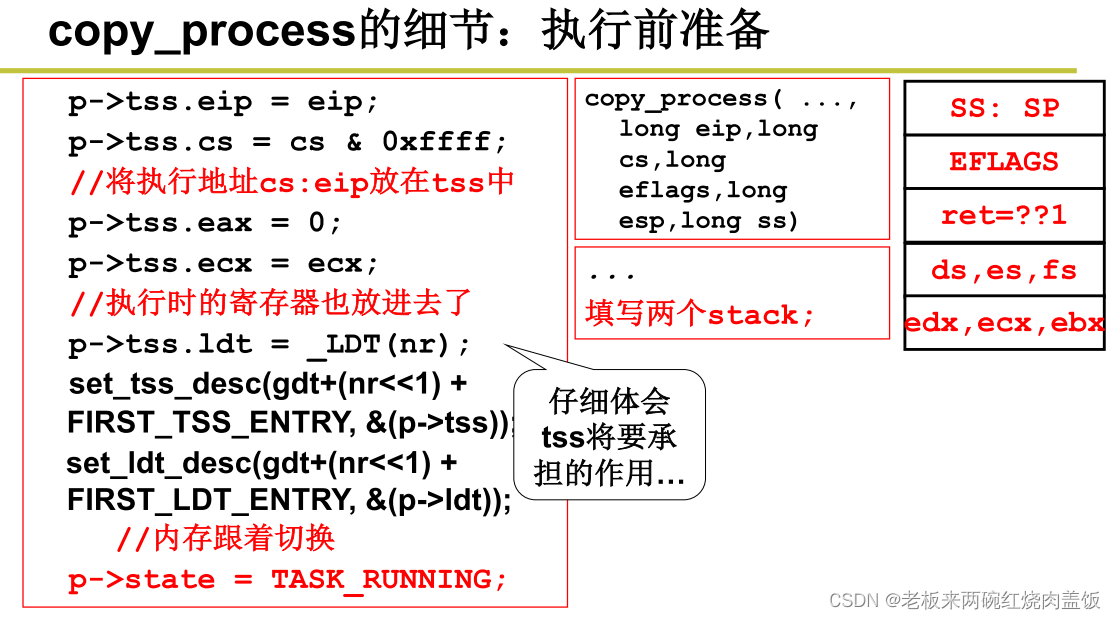
copy_process的细节:执行前准备
加油