(33条消息) BUUCTF SimpleRev(涉及大小端序存储的问题)_Ireb9z的博客-CSDN博客_buuctfsimplerev https://blog.csdn.net/afanzcf/article/details/118788007详细的wp这个大佬已经写了,但是对小头(端)位序的讲解可能还不够清楚,为什么wodah反向拼接?
https://blog.csdn.net/afanzcf/article/details/118788007详细的wp这个大佬已经写了,但是对小头(端)位序的讲解可能还不够清楚,为什么wodah反向拼接?
我代表师傅来从0开始解释一下这里的小端位序,鸣谢师傅@chneft
一、其实人和计算机都是从高往低读。
人都是从左往右读,因为高位在左侧。比如100,1在百位上,是最高的位,所以读成100.
计算机也是从高位往低位读,但是对于计算机来说,地址的高位在右侧,所以计算机从右往左读。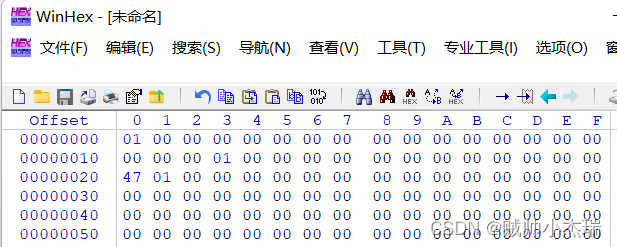
二、先定义一个变量,来看看大头和小头的区别。
int v9=512969957736=0x776F646168LL;
地址是:0000h,地址排列如下图所示,是小头位序。
可能不够清晰,所以我们拿1来作例子,展示小头位序的存储步骤:
int=1。
4个字节(32位系统)这种变量在写入地址的时候。
(1)先占据四个字节的位置
(2)把1写成16进制的形式 00 00 00 01。01是最低的字节。
(3)小头位序,低字节存放在低地址,高字节存放在高地址。
大头位序,低字节存放在高地址,高字节存放在低地址。
小头位序存放的1,存放在0000h的位置。
大头位序存放的1,存放在0010h的位置。看出来小头位序和大头位序的区别

三、定义一个数组。
知识点:数组的元素是按照数组元素序号从小到大在内存中排列的。
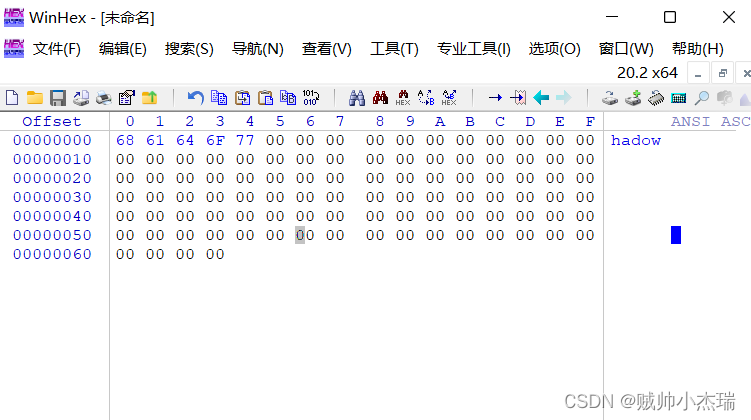
char c[4]={0x01,0x34,0x6f,0x20} 地址位置在0040h。

低地址存放在低字节对吧?小头位序,从高往低读取,01,34,6f,20
我们去查看它的地址

可以看到上图中,01反而成了低地址!说明我们写入的顺序错了。应该是下图0040h这样

可是这样不就变成从低地址往高地址读了吗?所以就要引出一个知识点:
数组的元素是按照数组元素序号从小到大在内存中排列的。
而读取时也是从低地址向高地址的方向读取。现在懂为什么是反着读取wodah了吧?
四、回到题目中
涉及到小头位序的一共分成四个部分,key3,v9,key,src。
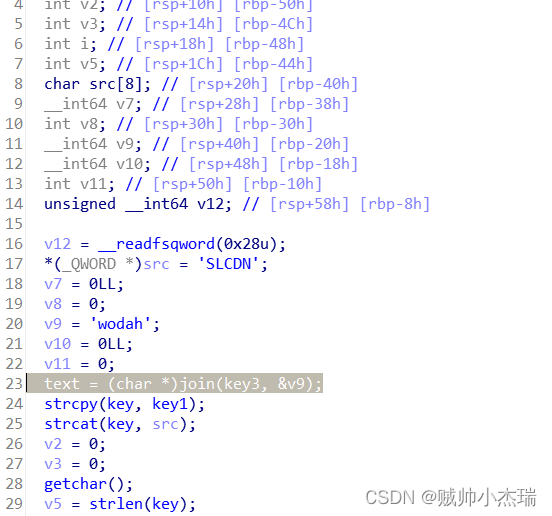

key3在读取的时候,由于是db,define byte在内存中也是从低到高,展示一下。
db是汇编语言,我们在汇编中看一下它。
assume cs:code , ds:data, ss:stack
data segment
db 'a','b'
db 'ab'
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,16
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
看到'a','b'和'ab'在内存中的排列相同,都是61,62,是从低到高。

join函数内的两个参数在调用时都必须是数组的形式,而数组在读取时也是从低到高。
所以读取key3时,是正常的kills。
之后我们再来看v9。
一开始是这个样子,v9 = 512969957736LL;
LL代表longlong,是强制类型转换。
鼠标放上去按R,变成v9 = 'wodah';
鼠标放上去按H变成十六进制 v9 = 0x776F646168LL;
开始时v9被ida识别为int64。在winhex中查看它,是小头位序没错。

join函数内的两个参数在调用时都必须是数组的形式,而数组在读取时是从低到高。
所以v9在读取时是按照0x6861646F77来读取,就变成了wodah,和key3结合后变成了
killshadow
下方strcat,key1同key3一样db。

而src则是字符数组,读取方式也知道了是"NDCLS",则key是"ADSFKNDCLS"

结束啦!撒花撒花✿✿ヽ(°▽°)ノ✿
md,逆向好难
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)