文章目录
- 时间复杂度为
O
(
N
l
o
g
N
)
O(Nlog_{}N)
O(NlogN)的三种排序法
- 一、归并排序法
- 1.代码实现思想
- 2.复杂度分析
- 3.代码实现
- 4.代码测试
- 二、快速排序法
- 1.代码实现思想
- 2.复杂度分析
- 3.代码实现
-
- 4.代码测试
- 三、堆排序法
- 1.代码实现思想
- 2.代码实现
-
- 3.复制度分析
- 4.代码测试
时间复杂度为
O
(
N
l
o
g
N
)
O(Nlog_{}N)
O(NlogN)的三种排序法
参考文章
慕课网数据结构与算法课程
一、归并排序法
1.代码实现思想
-
使用归并思想,也是分治思想,先走向递归深处,即分的过程,直到递归终止条件为止
-
对于递归终止条件,一般为只有一个叶子节点,为了优化性能,对于小数据采用插入排序法
- 小数据用插入原因是,深度已经不是主要影响因素,新建数组,两两比较复杂度会高于插入过程
- 注意,一定不要忘记return,否则递归永远无法终止
-
分的方案,是二分法,每次找区间的中间值,注意数据越界情况,然后将分化的两个区间继续二分
-
合的方案,是新建一个数组,将要合并的两个数组逐个比较,将较小元素依次放入新数组中,最后将新数组copy到原数组中进行数值覆盖,注意,数组索引的对应问题
- 要先定义好指针变量,分别指向要合并的两个区间起始位置,以及新数组的起始位置
- 如果两个区间其中一个已经遍历完了,要先进行判断处理,防止指针越界,偏离正确逻辑,产生错误结果
-
为了优化性能,在递归前,就将temp新数组容器准备好,依次传入即可,以免每次递归时新建开销
- 在合并前,也先判断要合并的两个区间是否左区间已经完全小于右区间,已经排好序的可以不用调用合并过程


2.复杂度分析
- 时间复杂度:
O
(
N
l
o
g
N
)
O(Nlog_{}N)
O(NlogN),即需要
O
(
l
o
g
N
)
O(log_{}N)
O(logN)层深度,每层
O
(
N
)
O(N)
O(N)的操作
- 若为有序数组,复杂度最好为
O
(
l
o
g
N
)
O(log_{}N)
O(logN),只需遍历
O
(
l
o
g
N
)
O(log_{}N)
O(logN)层,每层均无需合并操作,为
O
(
1
)
O(1)
O(1)
- 空间复杂度:
O
(
N
)
O(N)
O(N),即需要开辟新的长度为
O
(
N
)
O(N)
O(N)的新数组空间
- 稳定性:指的是相同元素保存相对位置不变的特性,在合并逻辑中,左右子数组相等时,优先排左数组元素,可以保证稳定性

3.代码实现
import java.util.Arrays;
import bubbleSort.ArrayGenerator;
import bubbleSort.SortingHelper;
import insertionSort.InsertionSort;
public class MergeSort {
private MergeSort() {}
private static final int MIN_MERGE = 32;
public static <E extends Comparable<E>> void sort(E[] arr) {
if(arr == null || arr.length <= 2) return;
E[] temp = Arrays.copyOf(arr, arr.length);
sort(arr, 0, arr.length - 1, temp);
}
private static <E extends Comparable<E>> void sort(
E[] arr, int left, int right, E[] temp) {
if((right - left) <= MIN_MERGE) {
InsertionSort.sort(arr, left, right);
return;
}
int mid = left + (right - left) / 2;
sort(arr, left, mid, temp);
sort(arr, mid + 1, right, temp);
if(arr[mid].compareTo(arr[mid + 1]) > 0)
merge(arr, left, mid, right, temp);
}
private static <E extends Comparable<E>> void merge(E[] arr, int left, int mid, int right, E[] temp) {
int i = left;
int j = mid + 1;
int t = left;
while(t <= right) {
if(i > mid) {
temp[t ++] = arr[j ++];
} else if(j > right) {
temp[t ++] = arr[i ++];
} else if(arr[i].compareTo(arr[j]) <= 0) {
temp[t ++] = arr[i ++];
} else if(arr[i].compareTo(arr[j]) > 0) {
temp[t ++] = arr[j ++];
}
}
System.arraycopy(temp, left, arr, left, right - left + 1);
}
}
4.代码测试
public static void main(String[] args) {
int n = 1000000;
Integer[] arr = ArrayGenerator.generateRandomArray(n, n);
SortingHelper.sortTime("MergeSort", arr);
}
MergeSort, n = 1000000 : 0.490878 s
二、快速排序法
1.代码实现思想
-
同样也是分治递归思想,先以分界点将区间分为两个区域,即小于分界点元素的值域和大于分界点的值域,分别在分界点左右两边
-
对于区分左右区间并找到分界点的partition过程,主要是双指针法,分别定义两个指针变量指向小于分界点和大于分界点的数,并依次移动遍历,并返回分界点位置,以供下一层递归调用
-
递归终止条件是区间元素只有一个,即上一个分界点的左右区间只有一个元素,由于分别小于和大于分界点,故一定可以与分界点构成有序数列
-
性能优化:
- 分的结果类似二分法,能左右均分,避免一边倒的现象,分界点的数值选取处理为目标区域的随机数,不能固定
- 如果有大量相同元素,单路排序,使用快慢指针,均从左边开始遍历,还是很容易退化成一边倒的现象,故使用双路快速排序法,即partition过程,改为左右指针从两边向中间遍历,遇到相等元素也交换,使得相等元素均分在左右两侧
- 对于大量相同元素性能可以优化为
O
(
N
)
O(N)
O(N),使用三路排序法,因为,三路排序的逻辑是将区间分为三个区域,等于分界点的元素单独划分一个区域,若大量相同元素,另外两个区域的元素会很少甚至为空,这样就减少递归层次,只需完成partition过程即可
-
单路快速排序法图解:



2.复杂度分析
- 时间复杂度:
O
(
N
l
o
g
N
)
O(Nlog_{}N)
O(NlogN),即需要
O
(
l
o
g
N
)
O(log_{}N)
O(logN)层深度,每层
O
(
N
)
O(N)
O(N)的操作
- 若为相同数组,三路快速排序法复杂度最好为
O
(
N
)
O(N)
O(N),只需遍历partition过程,左右区域为空无需递归
- 空间复杂度:
O
(
l
o
g
N
)
O(log_{}N)
O(logN),即每次partition过程需要额外的栈空间
- 稳定性:指的是相同元素保存相对位置不变的特性,由于数值会跳跃,难以保证稳定性
3.代码实现
单路快速排序法:
import java.util.Random;
import bubbleSort.ArrayGenerator;
import bubbleSort.SortingHelper;
public class QuickSort {
private QuickSort() {}
public static <E extends Comparable<E>> void sort1Way(E[] arr) {
if(arr == null || arr.length <= 2) return;
Random rad = new Random();
sort1Way(arr, 0, arr.length - 1, rad);
}
private static <E extends Comparable<E>> void sort1Way(
E[] arr, int left, int right, Random rad) {
if(left >= right) return;
int p = partition(arr, left, right, rad);
sort1Way(arr, left, p - 1, rad);
sort1Way(arr, p + 1, right, rad);
}
private static <E extends Comparable<E>> int partition(
E[] arr, int left, int right, Random rad) {
int radIndex = left + rad.nextInt(right - left + 1);
swap(arr, left, radIndex);
E v = arr[left];
int i = left + 1;
int j = left;
for(; i <= right; i ++) {
if(arr[i].compareTo(v) < 0) {
j ++;
swap(arr, i, j);
}
}
swap(arr, j, left);
return j;
}
private static <E> void swap(E[] arr, int i, int j) {
E t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
public static void main(String[] args) {
int[] nums = {100000, 1000000};
for(int n : nums) {
Integer[] arr = ArrayGenerator.generateRandomArray(n, n);
SortingHelper.sortTime("QuickSort1Way", arr);
}
}
}
QuickSort1Way, n = 100000 : 0.039567 s
QuickSort1Way, n = 1000000 : 0.359868 s // 大致相差10倍
双路快速排序法:
import java.util.Random;
import bubbleSort.ArrayGenerator;
import bubbleSort.SortingHelper;
public class QuickSort {
private QuickSort() {}
public static <E extends Comparable<E>> void sort2Way(E[] arr) {
if(arr == null || arr.length <= 2) return;
Random rad = new Random();
sort2Way(arr, 0, arr.length - 1, rad);
}
private static <E extends Comparable<E>> void sort2Way(
E[] arr, int left, int right, Random rad) {
if(left >= right) return;
int p = partition2(arr, left, right, rad);
sort2Way(arr, left, p - 1, rad);
sort2Way(arr, p + 1, right, rad);
}
private static <E extends Comparable<E>> int partition2(E[] arr, int left, int right, Random rad) {
int radIndex = left + rad.nextInt(right - left + 1);
swap(arr, left, radIndex);
E v = arr[left];
int i = left + 1;
int j = right;
while(true) {
while(i <= j && arr[i].compareTo(v) < 0) {
i ++;
}
while(i <= j && arr[j].compareTo(v) > 0) {
j --;
}
if(i >= j) break;
if(arr[i].compareTo(arr[j]) != 0) {
swap(arr, i , j);
}
i ++;
j --;
}
swap(arr, j, left);
return j;
}
public static void main(String[] args) {
int[] nums = {100000, 1000000};
for(int n : nums) {
Integer[] arr = ArrayGenerator.generateRandomArray(n, n);
Integer[] arr2 = Arrays.copyOf(arr, arr.length);
SortingHelper.sortTime("QuickSort1Way", arr);
SortingHelper.sortTime("QuickSort2Way", arr2);
}
}
}
QuickSort1Way, n = 100000 : 0.040037 s
QuickSort2Way, n = 100000 : 0.035355 s
QuickSort1Way, n = 1000000 : 0.352041 s
QuickSort2Way, n = 1000000 : 0.235757 s // 双路快排性能更优
三路快速排序法:
public static <E extends Comparable<E>> void sort3Way(E[] arr) {
Random rad = new Random();
sort3Way(arr, 0, arr.length - 1, rad);
}
private static <E extends Comparable<E>> void sort3Way(
E[] arr, int left, int right, Random rad) {
if (left >= right)
return;
int radIndex = left + rad.nextInt(right - left + 1);
swap(arr, left, radIndex);
int lt = left;
int i = left + 1;
int gt = right + 1;
while (i < gt) {
if (arr[i].compareTo(arr[left]) < 0) {
lt++;
swap(arr, i, lt);
i++;
} else if (arr[i].compareTo(arr[left]) > 0) {
gt--;
swap(arr, i, gt);
} else {
i++;
}
}
swap(arr, left, lt);
sort3Way(arr, left, lt - 1, rad);
sort3Way(arr, gt, right, rad);
}
4.代码测试
public static void main(String[] args) {
int[] nums = {100000, 1000000};
for(int n : nums) {
System.out.println("Random Array:");
Integer[] arr = ArrayGenerator.generateRandomArray(n, n);
Integer[] arr2 = Arrays.copyOf(arr, arr.length);
Integer[] arr3 = Arrays.copyOf(arr, arr.length);
SortingHelper.sortTime("QuickSort1Way", arr);
SortingHelper.sortTime("QuickSort2Way", arr2);
SortingHelper.sortTime("QuickSort3Way", arr3);
System.out.println();
System.out.println("Order Array:");
arr = ArrayGenerator.generateOrderedArray(n);
arr2 = Arrays.copyOf(arr, arr.length);
arr3 = Arrays.copyOf(arr, arr.length);
SortingHelper.sortTime("QuickSort1Way", arr);
SortingHelper.sortTime("QuickSort2Way", arr2);
SortingHelper.sortTime("QuickSort3Way", arr3);
System.out.println();
System.out.println("Same Value Array:");
arr = ArrayGenerator.generateRandomArray(n, 1);
arr2 = Arrays.copyOf(arr, arr.length);
arr3 = Arrays.copyOf(arr, arr.length);
SortingHelper.sortTime("QuickSort2Way", arr2);
SortingHelper.sortTime("QuickSort3Way", arr3);
System.out.println();
}
}
Random Array:
QuickSort1Way, n = 100000 : 0.039846 s
QuickSort2Way, n = 100000 : 0.036051 s
QuickSort3Way, n = 100000 : 0.059368 s
Order Array:
QuickSort1Way, n = 100000 : 0.009889 s
QuickSort2Way, n = 100000 : 0.005750 s
QuickSort3Way, n = 100000 : 0.049616 s
Same Value Array:
QuickSort2Way, n = 100000 : 0.005404 s
QuickSort3Way, n = 100000 : 0.000580 s
Random Array:
QuickSort1Way, n = 1000000 : 0.377061 s
QuickSort2Way, n = 1000000 : 0.243519 s // 双路快速排序法综合性能有优势
QuickSort3Way, n = 1000000 : 0.520272 s
Order Array:
QuickSort1Way, n = 1000000 : 0.217499 s
QuickSort2Way, n = 1000000 : 0.060744 s // 双路快速排序法综合性能有优势
QuickSort3Way, n = 1000000 : 0.379908 s
Same Value Array:
QuickSort2Way, n = 1000000 : 0.068403 s
QuickSort3Way, n = 1000000 : 0.001912 s // 三路快速排序法性能有优势
- 结果显示,时间复杂度一般为
O
(
l
o
g
N
)
O(log_{}N)
O(logN)
- 当数组元素不相同时,双路快速排序法综合性能有优势
- 当数组元素相同或大量相同时,三路快速排序法性能有优势
三、堆排序法
参考文章1,参考文章2
1.代码实现思想
-
1.首先将无序的序列进行堆化,构建成一个最大堆或最小堆,本文以最大堆为例
- 可以借助额外空间逐个添加,然后自下而上堆化
- 也可以使用原地堆化,即自上而下逐个对所有非叶子节点进行循环堆化
-
2.进行排序,因为堆顶元素是最大,将堆顶元素与堆中最后一个元素交换,将最大元素"沉"到数组末端,堆中元素总数减一
- 流程是;我们把下标为 n 的元素放到堆顶,然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是 n−1 的位置,一直重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了。
-
3.新的数据结构堆化调整,同样采用自上而下堆化处理,因为涉及到堆中元素总数变化,函数设计中要传入size大小的参数,并注意新的堆的大小的维护
-
扩展:堆的结构,是一颗完全二叉树,完全二叉树比较适合用数组来存储。用数组来存储完全二叉树是非常节省存储空间的。因为我们不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。

2.代码实现
准备工作:两种堆化操作
-
向最大堆中新添加元素图解:
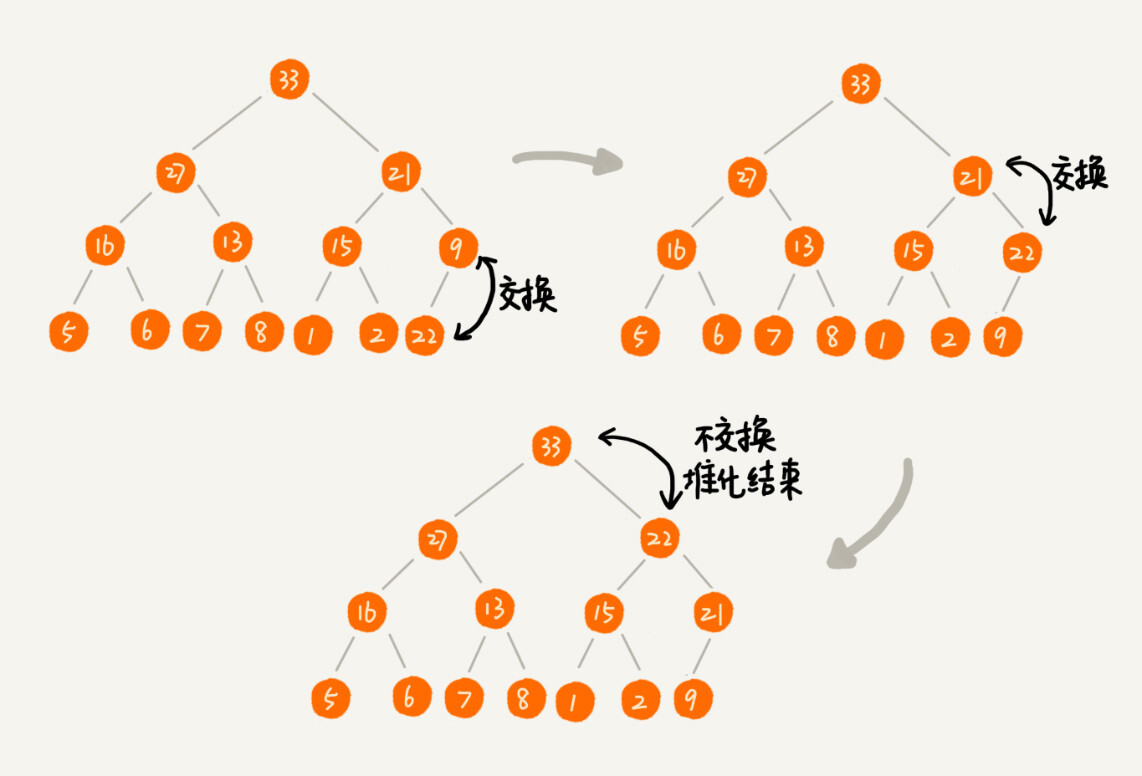
-
核心代码实现:
...
private Array<E> data;
public void add(E e) {
data.addLast(e);
siftUp(data.getSize() - 1);
}
private void siftUp(int k) {
while(k > 0 && data[k].compareTo(data[(k - 1) / 2]) > 0) {
data.swap(k, (k - 1) / 2);
k = (k - 1) / 2;
}
}
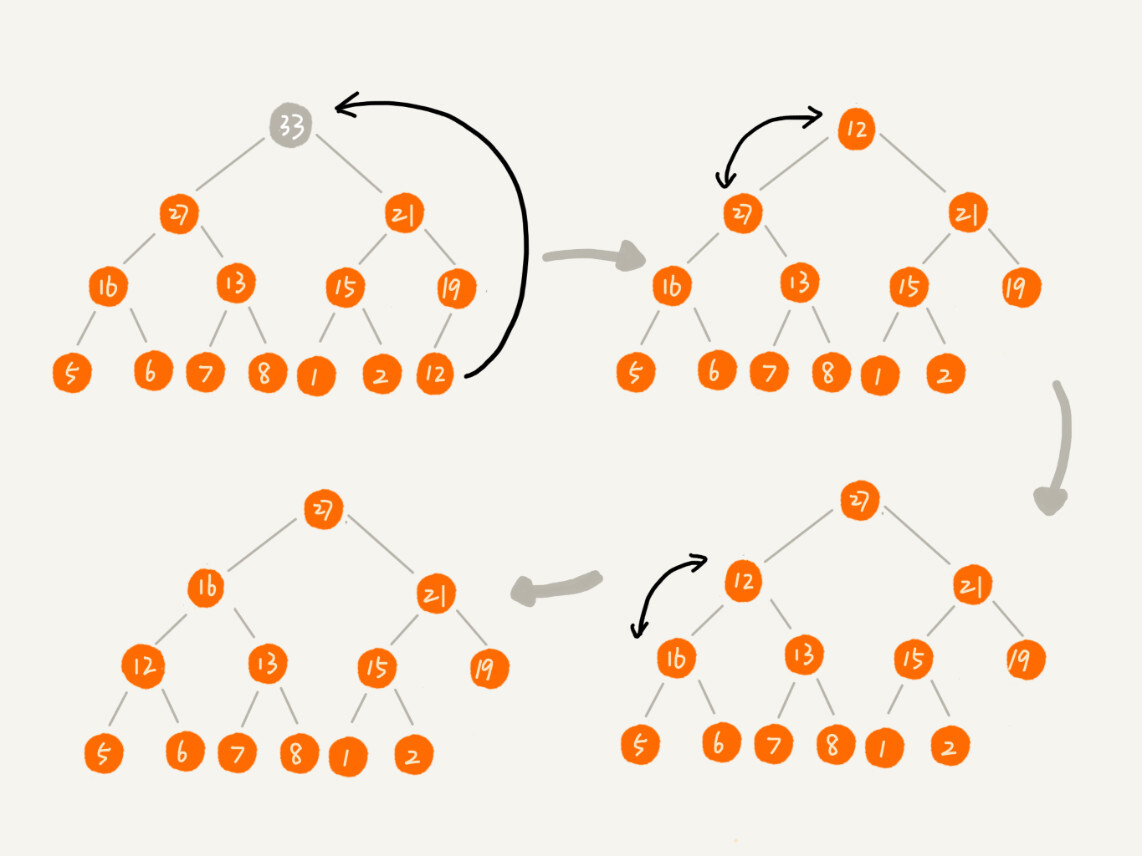
...
private static <E extends Comparable <E>>void siftDown(E[] data, int k, int n) {
while(2 * k + 1 < n) {
int j = 2 * k + 1;
if(j + 1 < n && data[j + 1].compareTo(data[j]) > 0) {
j ++;
}
if(data[k].compareTo(data[j]) < 0) {
data.swap(k, j);
}
k = j;
}
}
排序算法实现
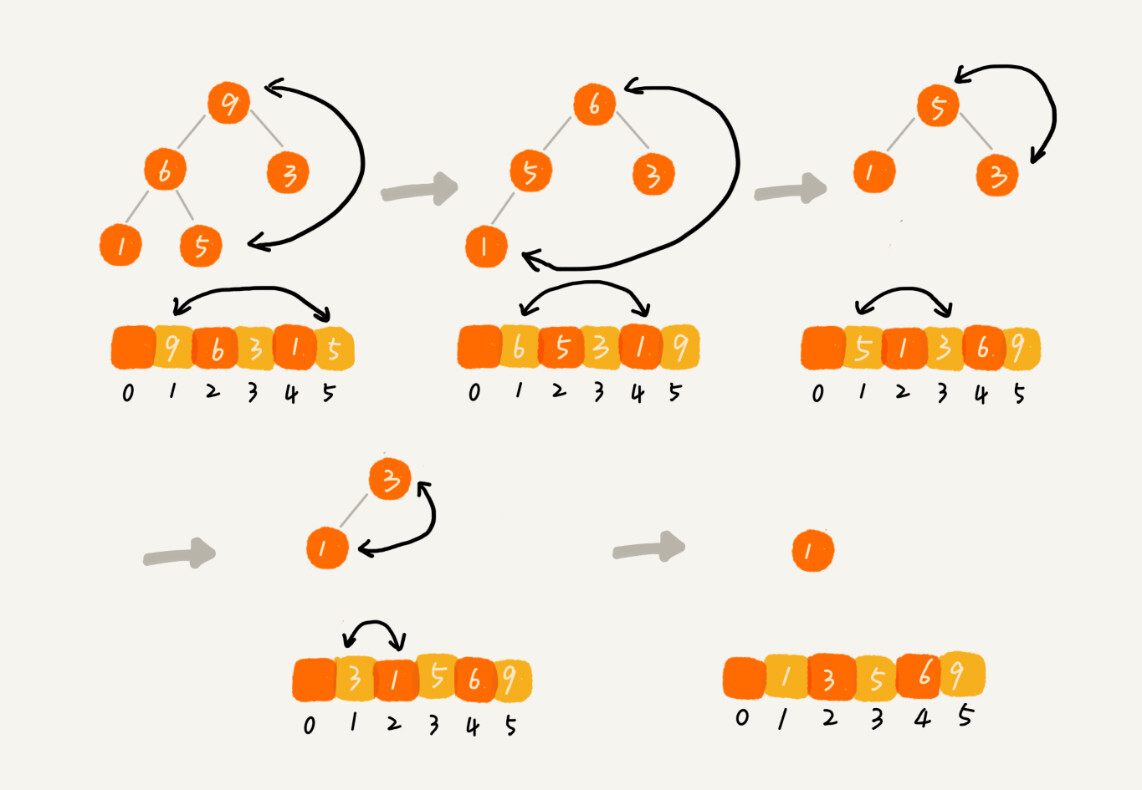
public class HeapSort {
private HeapSort() {};
public static <E extends Comparable<E>> void sort(E[] arr) {
if(arr == null || arr.length <= 2) return;
for(int i = (arr.length - 2) / 2; i >= 0; i --) {
siftDown(arr, i, arr.length);
}
for(int i = arr.length - 1; i > 0; i --) {
swap(arr, 0, i);
siftDown(arr, 0, i);
}
}
private static <E extends Comparable <E>>void siftDown(E[] arr, int k, int n) {
while(2 * k + 1 < n) {
int j = 2 * k + 1;
if(j + 1 < n && arr[j + 1].compareTo(arr[j]) > 0) {
j ++;
}
if(arr[k].compareTo(arr[j]) < 0) {
swap(arr, k, j);
}
k = j;
}
}
private static <E>void swap(E[] data, int k, int j) {
E t = data[k];
data[k] = data[j];
data[j] = t;
}
}
3.复制度分析
- 时间复杂度:
O
(
N
l
o
g
N
)
O(Nlog_{}N)
O(NlogN),堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是
O
(
n
)
O(n)
O(n),排序过程的时间复杂度是
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn),所以,堆排序整体的时间复杂度是
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)
- 空间复杂度:
O
(
1
)
O(1)
O(1),即每次都只需要极个别临时存储空间,原地排序算法
- 稳定性:指的是相同元素保存相对位置不变的特性,因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。故是不稳定的
4.代码测试
public static void main(String[] args) {
int n = 1000000;
Integer[] arr = ArrayGenerator.generateRandomArray(n, n);
Integer[] arr1 = Arrays.copyOf(arr, arr.length);
Integer[] arr2 = Arrays.copyOf(arr, arr.length);
SortingHelper.sortTime("MergeSort", arr);
SortingHelper.sortTime("QuickSort2Way", arr1);
SortingHelper.sortTime("HeapSort", arr2);
}
MergeSort, n = 1000000 : 0.424197 s
QuickSort2Way, n = 1000000 : 0.331031 s
HeapSort, n = 1000000 : 0.689467 s
-
小结:为什么快速排序要比堆排序性能好?
- 原因1:堆排序数据访问的方式没有快速排序友好。对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。这样对 CPU 缓存是不友好的。
- 原因2:对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。快速排序数据交换的次数不会比逆序度多。但是堆排序的第一步是建堆,建堆的过程会打乱数据原有的相对先后顺序,导致原数据的有序度降低。比如,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了。
-
堆排序优势主要应用于topK问题
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)