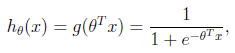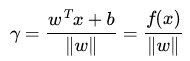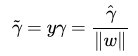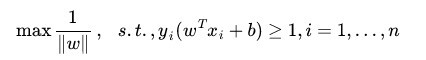#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml/ml.hpp>
using namespace cv;
int main()
{
// Data for visual representation
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);
// Set up training data
float labels[4] = {1.0, -1.0, -1.0, -1.0};
Mat labelsMat(3, 1, CV_32FC1, labels);
float trainingData[4][2] = { {501, 10}, {255, 10}, {501, 255}, {10, 501} };
Mat trainingDataMat(3, 2, CV_32FC1, trainingData);
// Set up SVM's parameters
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::LINEAR;
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);
// Train the SVM
CvSVM SVM;
SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
Vec3b green(0,255,0), blue (255,0,0);
// Show the decision regions given by the SVM
for (int i = 0; i < image.rows; ++i)
for (int j = 0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_<float>(1,2) << i,j);
float response = SVM.predict(sampleMat);
if (response == 1)
image.at<Vec3b>(j, i) = green;
else if (response == -1)
image.at<Vec3b>(j, i) = blue;
}
// Show the training data
int thickness = -1;
int lineType = 8;
circle( image, Point(501, 10), 5, Scalar( 0, 0, 0), thickness, lineType);
circle( image, Point(255, 10), 5, Scalar(255, 255, 255), thickness, lineType);
circle( image, Point(501, 255), 5, Scalar(255, 255, 255), thickness, lineType);
circle( image, Point( 10, 501), 5, Scalar(255, 255, 255), thickness, lineType);
// Show support vectors
thickness = 2;
lineType = 8;
int c = SVM.get_support_vector_count();
for (int i = 0; i < c; ++i)
{
const float* v = SVM.get_support_vector(i);
circle( image, Point( (int) v[0], (int) v[1]), 6, Scalar(128, 128, 128), thickness, lineType);
}
imwrite("result.png", image); // save the image
imshow("SVM Simple Example", image); // show it to the user
waitKey(0);
}
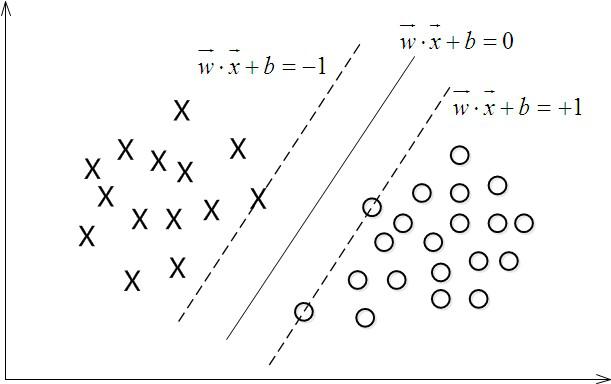
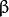 叫做 权重向量 ,
叫做 权重向量 , 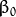 叫做 偏置(bias) 。
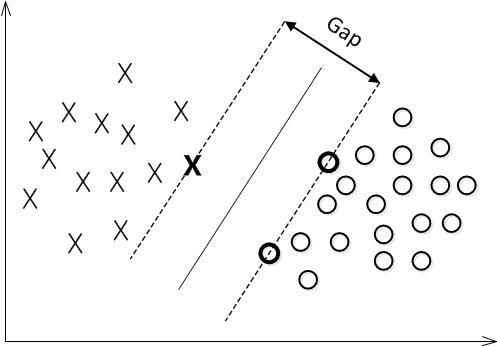
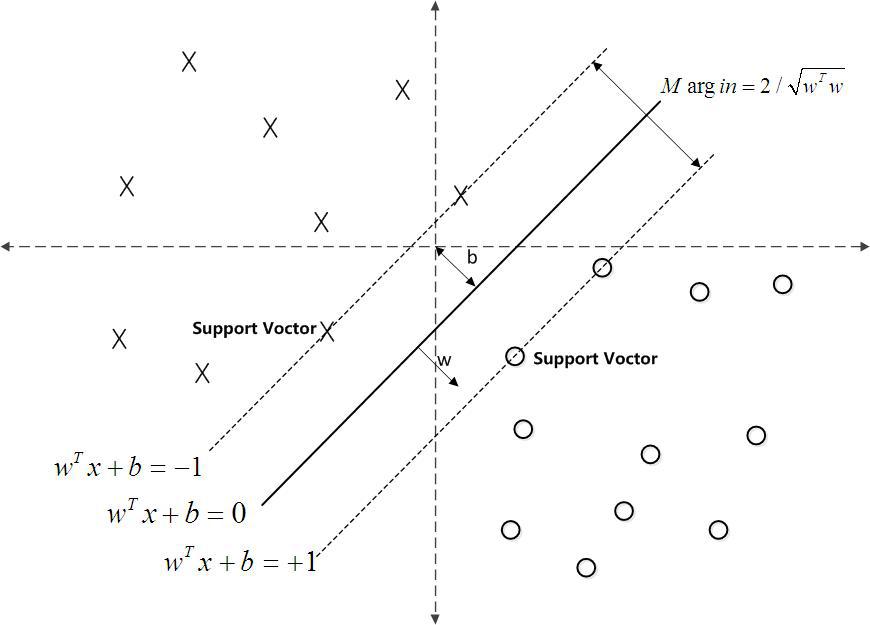
叫做 偏置(bias) 。 表示离超平面最近的那些点。 这些点被称为 支持向量**。 该超平面也称为 **canonical 超平面.
表示离超平面最近的那些点。 这些点被称为 支持向量**。 该超平面也称为 **canonical 超平面.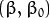 的距离为:
的距离为: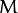 , 它的取值是最近距离的2倍:
, 它的取值是最近距离的2倍: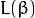 。 限制条件隐含超平面将所有训练样本
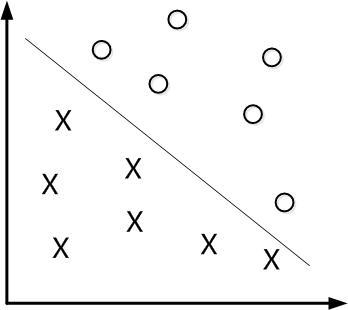
。 限制条件隐含超平面将所有训练样本 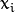 正确分类的条件,
正确分类的条件,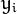 表示样本的类别标记。
表示样本的类别标记。 2)。 这个参数定义在 CvSVMParams.svm_type 属性中.
2)。 这个参数定义在 CvSVMParams.svm_type 属性中.