网页的组成
网页需要通过 HTML、CSS、JavaScript 和各种媒体资源的组合,实现多种功能和呈现效果的页面
一个网页通常由以下几个组成部分构成:
- HTML标记语言:定义网页的结构、内容和格式,用于显示文本、图像、链接等信息。
- CSS样式表:定义网页的样式和布局,可以控制字体、颜色、大小、排版等方面。
- JavaScript脚本语言:用于增强网页的交互性和动态性,可以实现网页上的动画效果、表单验证、事件处理等功能。
- 图像和多媒体:包括各种格式的图像、音频和视频文件,用于丰富网页的内容和呈现方式。
- 超链接和导航:用于连接不同的网页或者同一网页内的不同部分,让用户能够快速地浏览和导航。
- 表单和控件:用于接收用户的输入,包括文本框、复选框、单选框、下拉框等。
- 脚注和注释:提供对网页内容的解释和补充,方便用户了解更多信息。
网页的结构
网页结构通常分为三个部分:文档类型声明、头部和主体。
- 文档类型声明:位于 HTML 文档的最开始,用于告诉浏览器这是一个 HTML 文档,并且应该使用哪个 HTML 版本的标准来解析。
- 头部:位于文档类型声明之后,主要包括了一些网页的元信息,如 title、meta、link、script 等标签,这些标签用于告诉浏览器一些关于网页的基本信息,例如标题、关键词、网页描述等等。
- 主体:网页的主要内容,包括文本、图片、视频、音频等等,主体部分的标签包括 div、p、h1~h6、img、video、audio、ul、ol 等等,通过这些标签可以将网页内容进行适当的分组和排版,呈现出更好的阅读体验。
选择器
网页选择器是指在开发者工具中,通过选择器来获取网页中特定元素的工具。开发者可以通过使用网页选择器来定位网页上的元素,例如文本、图片、链接等。常见的网页选择器有CSS选择器、XPath选择器等。
CSS选择器
CSS选择器是一种使用CSS语法来定位元素的选择器,通常通过元素的类名、ID等属性来选择特定的元素。
以下是一些常见的CSS选择器及其用法和示例:
- 标签选择器:根据元素的标签名称进行选择。
例如,选择所有段落元素(p):
p {
color: red;
}
- 类选择器:根据元素的类名进行选择。
例如,选择所有class为“highlight”的元素
.highlight {
background-color: yellow;
}
- ID选择器:根据元素的ID进行选择。
例如,选择ID为“header”的元素:
#header {
font-size: 24px;
}
- 属性选择器:根据元素的属性进行选择。
例如,选择所有包含title属性的元素:
[title] {
border: 1px solid black;
}
- 组合选择器:将多个选择器组合在一起,以选择指定的元素。
例如,选择所有类为“highlight”且标签为“p”的元素:
p.highlight {
font-weight: bold;
}
- 后代选择器:选择指定元素的后代元素。
例如,选择所有div元素内的段落元素(p):
div p {
color: blue;
}
- 子元素选择器:选择指定元素的直接子元素。
例如,选择所有列表(ul)元素的直接子元素(li):
ul > li {
list-style: none;
}
以上仅是CSS选择器的一部分,还有其他更高级的选择器,如伪类选择器和伪元素选择器等。熟练掌握CSS选择器可以帮助开发者更轻松地样式化和操作HTML元素。
在爬虫中,我们可以通过选择器来定位元素,解析页面,获取想要的信息。对于我个人的爬虫开发来说,我习惯于使用xpath来定位元素。
Xpath
可以通过路径表达式在文档中进行导航,并选择所需的节点或节点集合。
XPath中最基本的路径表达式是节点选择器,可以通过节点的名称、属性和其他属性进行选择。以下是一些常用的XPath选择器:
- 选择所有节点://*
- 根据节点名称选择节点://div 选择所有div节点
- 根据节点属性选择节点://div[@class=“example”] 选择所有class属性值为example的div节点
- 根据节点文本内容选择节点://a[text()=“click here”] 选择所有文本内容为click here的a节点
- 根据节点位置选择节点://ul/li[2] 选择所有ul节点下的第二个li节点
Xpath helper浏览器拓展插件使用
我使用的是chrome浏览器,其他浏览器安装插件可自行搜索安装方法。
安装方法如下
- 打开设置,点击拓展程序

- 打开开发者模式
- 进入chrome应用商店,搜索xpath helper拓展程序,并添加
- 【测试】:打开任意一个网页,按快捷键ctrl+shift+x打开选择器,左侧query为xpath语法,右侧为选择结果

Xpath 定位示例
示例HTML代码如下:
假设有以下的HTML文档:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<div class="container">
<h1>Example Page</h1>
<p>This is an example page.</p>
<ul>
<li><a href="#">Link 1</a></li>
<li><a href="#">Link 2</a></li>
<li><a href="#">Link 3</a></li>
</ul>
</div>
</body>
</html>
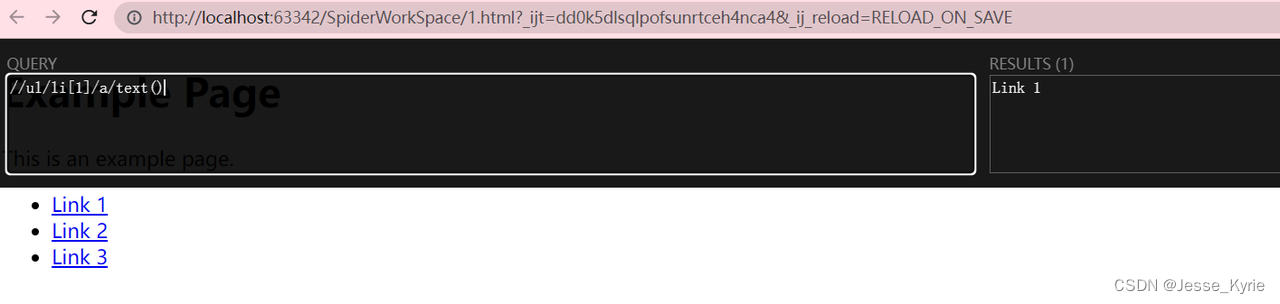
如果我需要获取以上的网页内【Link 1】这个字符串,我需要先观察包含该数据的标签结构
该数据被包在a标签内,a标签为ul下的第一个li内,所以该数据对应的a标签的路径为//ul/li[1]/a
如果要取到a标签内的数据,我们可以调用text()方法。以上数据的完整路径则为//ul/li[1]/a/text()
结果展示,获取到了字符串 Link 1
XPath还有许多其他的语法和功能,例如通配符、运算符、函数等。它是一种强大的工具,可用于从文档中提取所需的数据。
更多的xpath使用方法可以参考https://www.w3school.com.cn/xpath/index.asp
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)