查找算法
有序表查找
二分法查找
package dataStructure;
import java.util.ArrayList;
import java.util.List;
public class BinarySearch {
public static void main(String[] args) {
int[] arr = {20,70,80,110,121,134};
int index = binarySearch1(arr,134);
System.out.println(index);
}
public static int binarySearch1(int[] arr,int val) {
int left = 0;
int right = arr.length-1;
while(true) {
int mid = (left + right) / 2;
if(arr[mid] == val) {
return mid;
}else if(arr[mid] > val) {
right = mid - 1;
}else {
left = mid + 1;
}
if(left > right) {
return -1;
}
}
}
public static int binarySearch2(int[] arr,int val,int left,int right) {
if(left > right) {
return -1;
}
int mid = (left + right) / 2;
int midVal = arr[mid];
if(midVal > val) {
return binarySearch2(arr,val,left,mid-1);
}else if(midVal < val) {
return binarySearch2(arr,val,mid+1,right);
}else {
return mid;
}
}
public static List<Integer> binarySearch(int[] arr,int val,int left,int right){
if(left > right) {
return new ArrayList();
}
int mid = (left+right) / 2;
int midVal = arr[mid];
if(midVal > val) {
return binarySearch(arr,val,left,mid-1);
}else if(midVal < val) {
return binarySearch(arr,val,mid+1,right);
}else {
ArrayList<Integer> list = new ArrayList<>();
int temp1 = mid-1;
while(true) {
if(temp1 < 0 || arr[temp1] != val) {
break;
}
list.add(temp1--);
}
list.add(mid);
int temp2 = mid + 1;
while(true) {
if(temp2 > right || arr[temp2] != val) {
break;
}
list.add(temp2++);
}
return list;
}
}
}
插值查找
当我们需要查找的数组中数组比较连续且有序的数据时,采用插值查找更能提高查找效率。可以做到自适应计算mid.例如:arr[] = {1,2,3,…1000};这样的数组
适合使用的场景:
1.对于数据量比较大,关键字分布比较均匀的查找表来说,插值查找的数比二分查找要快
2.关键字分布不均匀的情况下,不一定比二分法要好
在二分法中:
m
i
d
=
(
l
e
f
t
+
r
i
g
h
t
)
/
2
=
l
e
f
t
+
1
/
2
(
r
i
g
h
t
−
l
e
f
t
)
mid = (left+right)/2=left + 1/2(right-left)
mid=(left+right)/2=left+1/2(right−left)
将上面公式转换成:
m
i
d
=
l
e
f
t
+
[
(
f
i
n
d
V
a
l
u
e
−
a
r
r
[
l
e
f
t
]
)
/
(
a
r
r
[
r
i
g
h
t
]
−
a
r
r
[
l
e
f
t
]
)
]
∗
(
r
i
g
h
t
−
l
e
f
t
)
mid = left + [(findValue-arr[left])/(arr[right]-arr[left])]*(right-left)
mid=left+[(findValue−arr[left])/(arr[right]−arr[left])]∗(right−left)
例:
package dataStructure;
public class InsertValueSearch {
private static int count=0;
public static void main(String[] args) {
int[] arr = new int[100];
for(int i=0;i < 100;i++) {
arr[i] = i+1;
}
int index = insertSearch(arr,33,0,arr.length-1);
System.out.println("查找了"+count+"次");
System.out.println("index="+index);
}
public static int insertSearch(int[] arr,int findValue,int left,int right) {
count++;
if(left > right || findValue < arr[0] || findValue > arr[arr.length-1]) {
return -1;
}
int mid = left + (right - left)*(findValue - arr[left])/(arr[right] - arr[left]);
if(findValue > arr[mid]) {
return insertSearch(arr,findValue,mid+1,right);
}else if(findValue < arr[mid]) {
return insertSearch(arr,findValue,left,mid-1);
}else {
return mid;
}
}
}
斐波那契查找
因为斐波那契数列相邻两个数的比例,无限接近黄金分割比值0.618.所以又称为黄金分割法
理解mid = low + F(k-1) -1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PLGVQG5x-1652774515721)(D:\Desktop\Java\imag\斐波那契查找.png)]](https://img-blog.csdnimg.cn/81cbe62a53764cedaedff16e923c013d.png)
1)由斐波那契数列 F[k]=F[k-1]+F[k-2]的性质,可以得到(F[k]-1) =(F[k-1]-1) + (F[k-2]-1)+1.该式说明,只要顺序表的长度为F[k]-1,则可以将该表分成长度为F[k-1]-1和F[k-2]-1的两段,即如上图所示。从而中间位置为mid=low+F(k-1)-1
2)类似的, 每一子段也可以用相同的方式分割
3)但顺序表长度n不一 定刚好等于F[k]-1,所以需要将原来的顺序表长度n增加至F[k]-1。这里的k值只要能使得F[K]-1恰好大于或等于n即可,由以下代码得到顺序表长度增加后,新增的位置(从n+ 1到F[k]-1位置),都赋为n位置的值即可。
whle(n>fib(k)-1) k++;
代码:
package dataStructure;
import java.util.Arrays;
public class Test {
static int maxSize = 20;
public static void main(String[] args) {
int[] arr = {0,1,16,24,35,47,59,62,73,88,99};
System.out.println("index="+ fibonacciSearch(arr,99));
}
public static int[] fib(){
int[] f = new int[maxSize];
f[0] = 1;
f[1] = 1;
for (int i = 2; i < f.length; i++) {
f[i] = f[i - 1] + f[i - 2];
}
return f;
}
public static int fibonacciSearch(int[] arr,int key){
int left = 0;
int right = arr.length - 1;
int k = 0;
int mid = 0;
int[] f = fib();
while(right > f[k] - 1){
k++;
}
int[] temp = Arrays.copyOf(arr,f[k]);
for (int i = right + 1; i < temp.length; i++) {
temp[i] = arr[right];
}
while(left < right){
mid = left + f[k - 1] - 1;
if(key < temp[mid]){
right = mid - 1;
k--;
}else if(key > temp[mid]){
left = mid + 1;
k -= 2;
}else{
if( mid <= right){
return mid;
}else{
return right;
}
}
}
return -1;
}
}
哈希表
哈希表可以看成是以个缓存层,功能没有Redis强大。减少对数据库的操作。
散列技术:
散列技术既是一种存储方法,也是一种查找方法
散列技术最适合的求解问题:查找与给定值相等的记录
散列表内存结构图示:
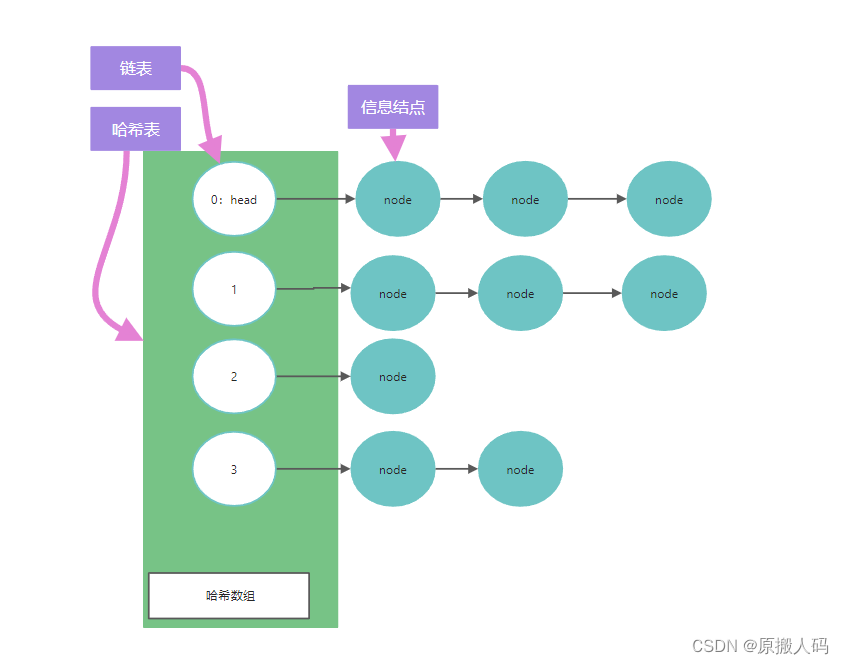
使用场景:一个上机题
有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,性别,年龄,住址.),当输入该员工的id时,要求查找到该员工的所有信息要求:不使用数据库,尽量节省内存,速度越快越好=>哈希表(散列)
package map;
import java.util.Scanner;
public class MyHashList {
public static void main(String[] args) {
HashTable hashTable = new HashTable(10);
Scanner scanner = new Scanner(System.in);
String in = "";
while(true){
System.out.println("put:添加员工信息!");
System.out.println("dis:遍历员工信息!");
System.out.println("fin:查找员工信息!");
System.out.println("del:删除员工信息!");
System.out.println("exit:退出系统!!");
in = scanner.next();
switch(in){
case "put":
System.out.println("员工id:");
int id = scanner.nextInt();
System.out.println("员工姓名:");
String name = scanner.next();
hashTable.put(new Node(id,name));
break;
case "dis":
System.out.println("哈希表的信息为:");
hashTable.getTable();
break;
case "fin":
System.out.println("请输入需要查找的员工id:");
int id1 = scanner.nextInt();
hashTable.search(id1);
break;
case "del":
System.out.println("请输入想要删除的员工id:");
int id2 = scanner.nextInt();
hashTable.remove(id2);
break;
case "exit":
scanner.close();
System.exit(0);
break;
default:
break;
}
}
}
}
class HashTable{
private NodeLinkList[] nodeLinkListArray;
private int size;
public HashTable(int size){
this.size = size;
nodeLinkListArray = new NodeLinkList[size];
for (int i = 0; i < size; i++) {
nodeLinkListArray[i] = new NodeLinkList();
}
}
public int hashFunction(int id){
return id % size;
}
public void put(Node node){
int no = hashFunction(node.getId());
nodeLinkListArray[no].add(node);
}
public void getTable(){
for (int i = 0; i < size; i++) {
nodeLinkListArray[i].list(i);
}
}
public void search(int id){
int no = hashFunction(id);
Node node = nodeLinkListArray[no].find(id);
if(node != null){
System.out.println("需要查找的对应id的员工信息为:");
System.out.println("id:"+node.getId());
System.out.println("name:"+node.getName());
}else{
System.out.printf("id输入有误,哈希表中没有%d对应的员工信息,请仔细检查核对id信息",id);
}
}
public void remove(int id){
int no = hashFunction(id);
nodeLinkListArray[no].delete(id);
}
}
class NodeLinkList{
private Node head;
public void add(Node node){
if(head == null){
head = node;
return;
}
Node cur = head;
while(true){
if(cur.getNext() == null){
break;
}
cur = cur.getNext();
}
cur.setNext(node);
}
public void list(int no){
System.out.print("第"+no+"条链表信息为:");
if(head == null){
System.out.print(".......\n");
return;
}
Node cur = head;
while(true){
System.out.printf("-->id=%d name=%s\t",cur.getId(),cur.getName());
if(cur.getNext() == null){
break;
}
cur = cur.getNext();
}
System.out.println();
}
public Node find(int id){
Node cur = head;
while(true) {
if (cur.getId() == id) {
break;
}
if(cur.getNext() == null){
cur = null;
break;
}
cur = cur.getNext();
}
return cur;
}
public void delete(int id){
if(head == null){
System.out.println("此链表没有数据");
return;
}
Node cur = head;
boolean flag = false;
while(true){
if(cur.getNext() == null){
break;
}
if(cur.getNext().getId() == id){
flag = true;
break;
}
cur = cur.getNext();
}
if(flag){
cur.setNext(cur.getNext().getNext());
}else {
return;
}
}
}
class Node{
private int id;
private String name;
private Node next;
public Node(){
}
public Node(int id,String name){
super();
this.id = id;
this.name = name;
}
public void setName(String name) {
this.name = name;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public int getId() {
return id;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)