目录
- 一、概述
- 1.1 表情分类
- 1.2 表情识别方法
-
- 1.3 本文实现
- 二、环境准备
- 2.1 安装PaddlePaddle
- 2.2 安装PaddleClas
- 三、人脸检测
- 3.1 概述
- 3.2 下载静态图模型
- 3.3 Python推理
- 3.4 数据集处理
- 四、表情识别
- 4.1数据格式说明
- 4.2 PP-HGNet分类算法原理简介
- 4.3 训练
- 4.4 静态图导出
- 4.5 测试
- 五、小结
一、概述
1.1 表情分类
表情识别是计算机理解人类情感的一个重要方向,也是人机交互的一个重要方面。表情识别是指从静态照片或视频序列中选择出表情状态,从而确定对人物的情绪与心理变化。20世纪70年代的美国心理学家Ekman和Friesen通过大量实验,定义了人类六种基本表情:开心,生气,惊讶,害怕,厌恶和悲伤,在本文的表情分类中还增添了一个中性表情,所以一共分为七种基本表情,具体如下图所示:

人脸表情识别(FER)在人机交互和情感计算中有着广泛的研究前景,包括人机交互、情绪分析、智能安全、娱乐、网络教育、智能医疗等。
1.2 表情识别方法
1.2.1 人工特征方法
传统方法在实现表情识别任务时大多使用各种人为设计的特征,例如Gabor、LBP、LGBP、HOG和SIFT等。这些人为设计的特征方法在特定的小样本集中往往更有效,但难以用于识别新的人脸图像,这给不受控环境中的人脸表情识别任务带来了挑战。
具体的,传统人工特征方法存在两个问题:
- 人为设计的特征太受制于特征算法的设计,耗时耗力;
- 特征提取与分类是两个分开的过程,不能将其融合到一个端到端的模型中;
1.2.2 神经网络方法
近几年来,前馈神经网络(FNN)和卷积神经网络(CNN)也被用来提取表情特征。基于卷积神经网络(CNN)的新的识别框架在表情识别任务中已经取得了显著的结果。CNN中的多个卷积和汇集层可以提取整个面部或局部区域的更高和多层次的特征,且具有良好的面部表情图像特征的分类性能。经验证明,CNN比其它类型的神经网络在图像识别方面更为优秀。
基于神经网络的方法也存在着两个问题:
- 简单的神经网络(如FNN)忽略了图像的二维空间信息;
- 浅层卷积网络所提取的特征鲁棒性较差;
1.3 本文实现
本教程完整记录基于深度学习的人脸表情识别项目开发过程,涵盖人脸检测和表情识别两部分,其中人脸检测部分采用现成的blazeface模型实现,推理速度快、精度高;表情识别部分将利用自己收集的数据集进行训练和推理,共完成前面所述7种表情的识别(读者也可以采用公开的表情识别数据集进行训练,例如FER2013或CK+)。
二、环境准备
本文所有训练和部署平台均为ubuntu18.04。
2.1 安装PaddlePaddle
参考官网进行安装。建议安装最新的动态图稳定版(即PaddlePaddle2系列版本)。本文使用PaddlePaddle2.3。
2.2 安装PaddleClas
PaddleClas是PaddlePaddle配套的开源图像分类算法库,涵盖了众多开箱即用的图像分类算法,只需要做简单的配置就可以上手训练和推理,使用非常方便,本文将使用PaddleClas来训练人脸表情识别算法。
为了加速下载,可以选择gitee镜像源:
git clone https://gitee.com/paddlepaddle/PaddleClas.git
然后进行安装:
cd PaddleClas
sudo python setup.py install
安装时可能会出现下面的错误:
error: importlib-metadata 4.8.3 is installed but importlib-metadata<4.3;
解决方法:
pip install flake8
三、人脸检测
3.1 概述
本文最终目标是实现人脸表情识别,为了能够排除背景干扰而聚焦人脸区域本身,在做表情识别之前我们有必要精确裁剪出人脸区域。这个步骤也是人脸识别项目中比较基础的预处理步骤,即人脸检测。
本文使用blazeface算法进行实现。这是一个支持在移动端GPU上实现亚毫秒级人脸检测的算法。这个算法的特点就是速度快、精度高、适合GPU推理,其主要思想来源于SSD和MobileNetV2。
在WIDER-FACE数据集上的mAP对比结果如下:
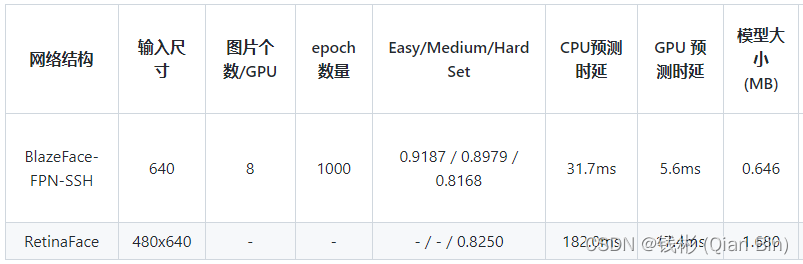
本文使用已经训练好的人脸检测器进行检测,如果需要自己训练,那么可以参考blazeface_paddle教程
3.2 下载静态图模型
下载已经训练好的静态图inference模型,下下来后解压,包括四个文件,分别为infer_cfg.yml、model.pdiparams、model.pdiparams.info、model.pdmodel。其中infer_cfg.yml是配置参数文件,model.pdiparams是模型参数文件,model.pdmodel是模型结构文件, model.pdiparams.info是模型信息文件。如下图所示:
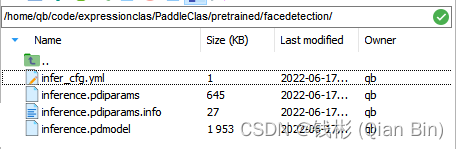
可以看到,整个模型文件很小,差不多在3M左右。
3.3 Python推理
下面我们尽可能用最简洁的代码完成单张图片的人脸检测推理,这样方便后面集成这个人脸检测模型。
首先编写测试脚本main.py,代码如下:
import cv2
from face_detect import FaceDetector
def main():
'''
主函数
'''
faceDetectPredictor = FaceDetector('pretrained/facedetection')
img_path = 'test/test.jpg'
img = cv2.imread(img_path,cv2.IMREAD_COLOR)
if img is None:
print('读取图像失败')
return
box_list = faceDetectPredictor.predict(img)
color = (255, 0, 0)
colortext = (0, 0, 255)
if box_list is not None:
for i, dt in enumerate(box_list):
bbox, score = dt[2:], dt[1]
xmin, ymin, xmax, ymax = bbox
text = "{:.4f}".format(score)
start_y = max(0, ymin)
font = cv2.FONT_HERSHEY_SIMPLEX
org = ((int)(xmin + 1), (int)(start_y))
fontScale = 1
thickness = 2
cv2.putText(img, text, org, font, fontScale, colortext, thickness, cv2.LINE_AA)
cv2.rectangle(img,(xmin, ymin), (xmax, ymax), color, 2)
cv2.imwrite('results/test.jpg',img)
if __name__ == "__main__":
'''
程序入口
'''
main()
这个测试脚本依赖当前目录下的face_detect.py文件,该文件内容对整个的人脸检测推理进行了封装,方便后续使用,其代码如下:
import os
import cv2
import numpy as np
from PIL import Image
from paddle.inference import Config
from paddle.inference import create_predictor
def check_model_file(model):
"""
检查模型路径
"""
if os.path.isdir(model):
model_file_path = os.path.join(model, "inference.pdmodel")
params_file_path = os.path.join(model, "inference.pdiparams")
if not os.path.exists(model_file_path) or not os.path.exists(
params_file_path):
raise Exception(
f"The specifed model directory error. The drectory must include 'inference.pdmodel' and 'inference.pdiparams'."
)
else:
raise Exception(
f"The specifed model name error. Support 'BlazeFace' for detection. And support local directory that include model files ('inference.pdmodel' and 'inference.pdiparams')."
)
return model_file_path, params_file_path
def normalize_image(img, scale=None, mean=None, std=None, order='chw'):
if isinstance(scale, str):
scale = eval(scale)
scale = np.float32(scale if scale is not None else 1.0 / 255.0)
mean = mean if mean is not None else [0.485, 0.456, 0.406]
std = std if std is not None else [0.229, 0.224, 0.225]
shape = (3, 1, 1) if order == 'chw' else (1, 1, 3)
mean = np.array(mean).reshape(shape).astype('float32')
std = np.array(std).reshape(shape).astype('float32')
if isinstance(img, Image.Image):
img = np.array(img)
assert isinstance(img, np.ndarray), "invalid input 'img' in NormalizeImage"
return (img.astype('float32') * scale - mean) / std
def to_CHW_image(img):
if isinstance(img, Image.Image):
img = np.array(img)
return img.transpose((2, 0, 1))
class BasePredictor(object):
def __init__(self, predictor_config):
super().__init__()
self.predictor_config = predictor_config
self.predictor, self.input_names, self.output_names = self.load_predictor(
predictor_config["model_file"], predictor_config["params_file"])
def load_predictor(self, model_file, params_file):
config = Config(model_file, params_file)
if self.predictor_config["use_gpu"]:
config.enable_use_gpu(200, 0)
config.switch_ir_optim(True)
else:
config.disable_gpu()
config.set_cpu_math_library_num_threads(self.predictor_config[
"cpu_threads"])
if self.predictor_config["enable_mkldnn"]:
try:
config.set_mkldnn_cache_capacity(10)
config.enable_mkldnn()
except Exception as e:
print("The current environment does not support `mkldnn`, so disable mkldnn.")
config.disable_glog_info()
config.enable_memory_optim()
config.switch_use_feed_fetch_ops(False)
predictor = create_predictor(config)
input_names = predictor.get_input_names()
output_names = predictor.get_output_names()
return predictor, input_names, output_names
def preprocess(self):
raise NotImplementedError
def postprocess(self):
raise NotImplementedError
def predict(self, img):
raise NotImplementedError
class Detector(BasePredictor):
def __init__(self, det_config, predictor_config):
super().__init__(predictor_config)
self.det_config = det_config
self.target_size = self.det_config["target_size"]
self.thresh = self.det_config["thresh"]
def preprocess(self, img):
resize_h, resize_w = self.target_size
img_shape = img.shape
img_scale_x = resize_w / img_shape[1]
img_scale_y = resize_h / img_shape[0]
img = cv2.resize(
img, None, None, fx=img_scale_x, fy=img_scale_y, interpolation=1)
img = normalize_image(
img,
scale=1. / 255.,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
order='hwc')
img_info = {}
img_info["im_shape"] = np.array(
img.shape[:2], dtype=np.float32)[np.newaxis, :]
img_info["scale_factor"] = np.array(
[img_scale_y, img_scale_x], dtype=np.float32)[np.newaxis, :]
img = img.transpose((2, 0, 1)).copy()
img_info["image"] = img[np.newaxis, :, :, :]
return img_info
def postprocess(self, np_boxes):
expect_boxes = (np_boxes[:, 1] > self.thresh) & (np_boxes[:, 0] > -1)
return np_boxes[expect_boxes, :]
def predict(self, img):
inputs = self.preprocess(img)
for input_name in self.input_names:
input_tensor = self.predictor.get_input_handle(input_name)
input_tensor.copy_from_cpu(inputs[input_name])
self.predictor.run()
output_tensor = self.predictor.get_output_handle(self.output_names[0])
np_boxes = output_tensor.copy_to_cpu()
box_list = self.postprocess(np_boxes)
return box_list
class FaceDetector(object):
'''
人脸检测器
'''
def __init__(self, model_path):
super().__init__()
model_file_path, params_file_path = check_model_file(model_path)
det_config = {"thresh": 0.8, "target_size": [640, 640]}
predictor_config = {
"use_gpu": True,
"enable_mkldnn": True,
"cpu_threads": 1
}
predictor_config["model_file"] = model_file_path
predictor_config["params_file"] = params_file_path
self.det_predictor = Detector(det_config, predictor_config)
def preprocess(self, img):
img = img.astype(np.float32, copy=False)
return img
def draw(self, img, box_list, labels):
'''
保存检测结果到图像上
'''
color = (255, 0, 0)
colortext = (0, 0, 255)
for i, dt in enumerate(box_list):
bbox, score = dt[2:], dt[1]
label = labels[i]
xmin, ymin, xmax, ymax = bbox
text = "{} {:.4f}".format(label, score)
start_y = max(0, ymin)
font = cv2.FONT_HERSHEY_SIMPLEX
org = ((int)(xmin + 1), (int)(start_y))
fontScale = 1
thickness = 2
cv2.putText(img, text, org, font,
fontScale, colortext, thickness, cv2.LINE_AA)
cv2.rectangle(img,(xmin, ymin), (xmax, ymax), color, 2)
return img
def predict_np_img(self, img):
input_img = self.preprocess(img)
box_list = None
np_feature = None
if hasattr(self, "det_predictor"):
box_list = self.det_predictor.predict(input_img)
return box_list, np_feature
def predict(self, img):
"""
执行预测
"""
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
box_list, _ = self.predict_np_img(img)
return box_list
测试结果如下图所示:

可以看到,整个检测结果精度是非常高的。
3.4 数据集处理
我们的数据集是从网上提取的,很多照片涵盖了大面积的背景并且可能存在多个人脸,因此,我们需要对数据集进行加工处理,进一步裁剪出准确的人脸区域并按照类别放置在每个文件夹中方便后面进行表情识别算法的训练。
另外需要说明的是,前面我们使用的人脸检测算法对于小目标人脸是比较有效的,但是如果人脸占整个图像面积较大,那么这时候该人脸检测算法无法检测出人脸。为了能够规避这个问题,我们在实现的时候对我们收集的图像进行上下左右补齐(四周填充空白)操作,人为的将人脸变成“小脸”。
import os
import cv2
from face_detect import FaceDetector
def getFileList(dir,Filelist, ext=None):
"""
获取文件夹及其子文件夹中文件列表
输入 dir:文件夹根目录
输入 ext: 扩展名
返回: 文件路径列表
"""
newDir = dir
if os.path.isfile(dir):
if ext is None:
Filelist.append(dir)
else:
if ext in dir[-3:]:
Filelist.append(dir)
elif os.path.isdir(dir):
for s in os.listdir(dir):
newDir=os.path.join(dir,s)
getFileList(newDir, Filelist, ext)
return Filelist
def main():
'''
主函数
'''
faceDetectPredictor = FaceDetector('pretrained/facedetection')
org_img_folder='../chinese'
imglist = getFileList(org_img_folder, [], 'jpg')
print('本次执行检索到 '+str(len(imglist))+' 张图像\n')
pic_index = 0
for imgpath in imglist:
img = cv2.imread(imgpath,cv2.IMREAD_COLOR)
if img is None:
print('读取图像失败')
continue
h,w,_=img.shape
if w>800:
new_w=800
new_h=int(h*1.0/w*800)
img = cv2.resize(img, (new_w,new_h), interpolation = cv2.INTER_AREA)
h,w,_=img.shape
img = cv2.copyMakeBorder(img,h,h,w,w, cv2.BORDER_CONSTANT,value=[255,255,255])
box_list = faceDetectPredictor.predict(img)
if box_list is not None:
if box_list.size==0:
print('当前检测不到人脸 '+ imgpath)
continue
area = 0
xmin, ymin, xmax, ymax = 0,0,0,0
for i, dt in enumerate(box_list):
bbox, score = dt[2:], dt[1]
x1, y1, x2, y2 = bbox
if abs(x2-x1)*abs(y2-y1)>area:
area = abs(x2-x1)*abs(y2-y1)
xmin, ymin, xmax, ymax = int(x1), int(y1), int(x2), int(y2)
img = img[ymin:ymax,xmin:xmax,:]
imgname= os.path.splitext(os.path.basename(imgpath))[0]
if os.path.exists(imgname) is False:
os.makedirs(imgname)
cv2.imwrite(imgname+'/%d.jpg' % pic_index,img)
pic_index += 1
print(pic_index)
else:
print('当前检测不到人脸'+ imgpath)
continue
print('全部完成')
if __name__ == "__main__":
'''
程序入口
'''
main()
到这里我们就将所有表情识别需要的精确图像数据提取了出来,并且分成了7个类别,分别放在了7个不同的文件夹中。下面正式开始表情识别算法相关训练和推理。
四、表情识别
4.1数据格式说明
PaddleClas使用txt格式文件指定训练集和测试集,以 ImageNet1k 数据集为例,基本组织形式如下:

其中 train_list.txt 和 val_list.txt 每一行采用"空格"分隔图像路径与标注,下面是 train_list.txt 中的格式样例
train/n01440764/n01440764_10026.JPEG 0
下面是 val_list.txt 中的格式样例
val/ILSVRC2012_val_00000001.JPEG 65
因此,如果要训练我们自己的数据集,那么就需要将我们的数据集按照上面的形式进行组织。
完整处理代码如下所示:
import os
import random
import cv2
img_folder = 'data'
trainlst = 'train_list.txt'
vallst = 'val_list.txt'
ratio = 0.9
labellst='label.txt'
def writeLst(lstpath,namelst):
'''
保存文件列表
'''
print('正在写入 '+lstpath)
random.shuffle (namelst)
f=open(lstpath, 'a', encoding='utf-8')
for i in range(len(namelst)):
text = namelst[i]+'\n'
f.write(text)
f.close()
print(lstpath+ '已完成写入')
def main():
'''
主函数
'''
folderlst = os.listdir(img_folder)
print('共找到 %d 个文件夹' % len(folderlst))
trainnamelst = list()
valnamelst = list()
labelnamelst = list()
for i in range(len(folderlst)):
class_name = folderlst[i]
class_label = i
print('开始处理 '+class_name+' 文件夹')
filenamelst = os.listdir(os.path.join(img_folder,class_name))
totalNum = len(filenamelst)
print('当前文件夹图片数量为: ' + str(totalNum))
trainNum = int(ratio*totalNum)
text = str(class_label)+ ' ' + class_name
labelnamelst.append(text)
for j in range(totalNum):
imgpath = os.path.join(img_folder,class_name,filenamelst[j])
img = cv2.imread(imgpath, cv2.IMREAD_COLOR)
if img is None:
continue
text = imgpath + ' ' + str(class_label)
if j <= trainNum:
trainnamelst.append(text)
else:
valnamelst.append(text)
writeLst(trainlst,trainnamelst)
writeLst(vallst,valnamelst)
writeLst(labellst,labelnamelst)
print('全部完成')
if __name__ == '__main__':
'''
程序入口
'''
main()
到这里训练表情识别算法需要的数据就处理完了。在当前数据集目录下会生成train_lst.txt和val_lst.txt以及label.txt。
4.2 PP-HGNet分类算法原理简介
本文使用PP-HGNet算法来实现图像分类应用。
PP-HGNet(High Performance GPU Net) 是百度飞桨视觉团队自研的更适用于 GPU 平台的高性能骨干网络,该网络在 VOVNet 的基础上使用了可学习的下采样层(LDS Layer),融合了 ResNet_vd、PPHGNet 等模型的优点,该模型在 GPU 平台上与其他 SOTA 模型在相同的速度下有着更高的精度。在同等速度下,该模型高于 ResNet34-D 模型 3.8 个百分点,高于 ResNet50-D 模型 2.4 个百分点,在使用百度自研 SSLD 蒸馏策略后,超越 ResNet50-D 模型 4.7 个百分点。与此同时,在相同精度下,其推理速度也远超主流 VisionTransformer 的推理速度。
PP-HGNet 作者针对 GPU 设备,尽可能多的使用 3x3 标准卷积(计算密度最高)。在此将 VOVNet 作为基准模型,将主要的有利于 GPU 推理的改进点进行融合。从而得到一个有利于 GPU 推理的骨干网络。同样速度下,精度更高,非常适合工业界场景使用。
PP-HGNet 骨干网络的整体结构如下:
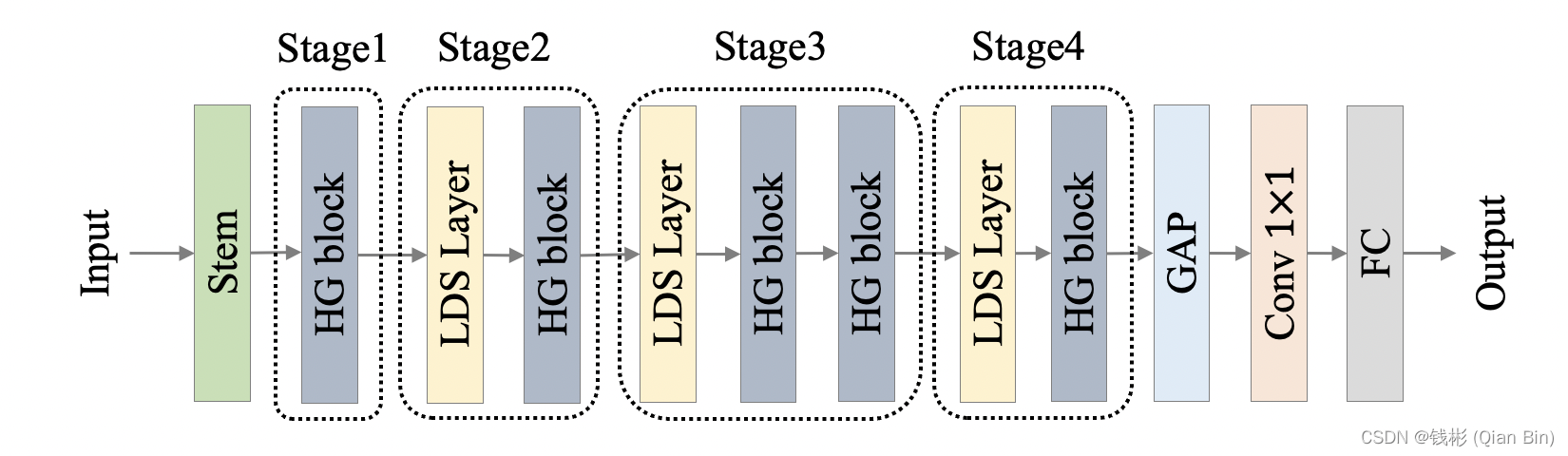
其中HG-Block的细节如下:
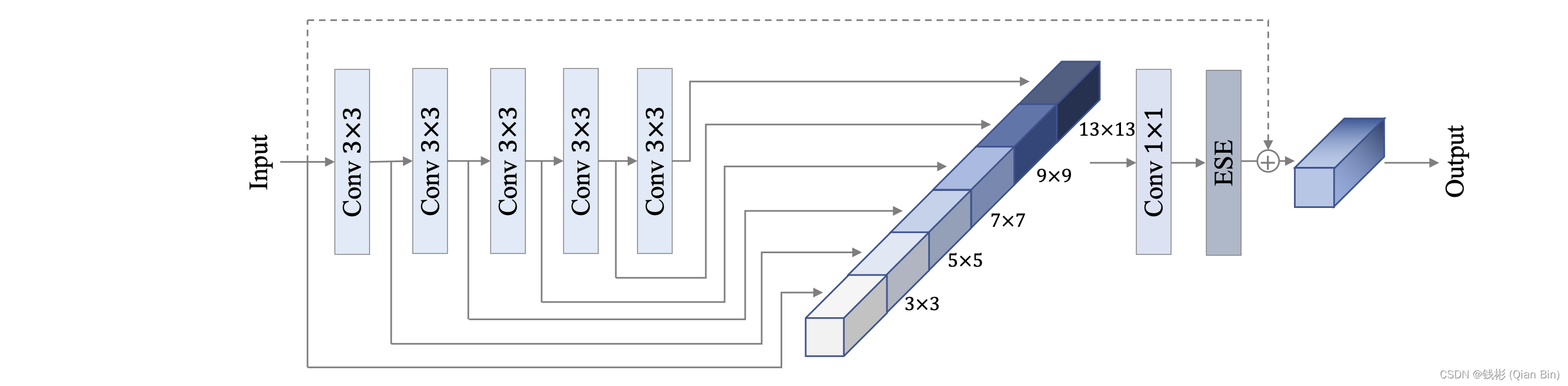
详细模型原理可以通过阅读官方源码仔细剖析,本文不再深入阐述。
4.3 训练
PaddleClas提供了非常方便的算法调用接口,只需要做好基本的配置参数文件设置就好了。首先通过cd进入到PaddleClas根目录下,然后创建一个名为expression.yaml的配置文件,内容如下所示:
Global:
checkpoints: null
pretrained_model: null
output_dir: ./results/
device: gpu
save_interval: 100
eval_during_train: True
eval_interval: 1
epochs: 600
print_batch_step: 10
use_visualdl: True
image_shape: [3, 224, 224]
save_inference_dir: ./results/inference
to_static: False
use_dali: False
AMP:
scale_loss: 128.0
use_dynamic_loss_scaling: True
level: O1
Arch:
name: PPHGNet_small
class_num: 7
Loss:
Train:
- CELoss:
weight: 1.0
epsilon: 0.1
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Cosine
learning_rate: 0.5
warmup_epoch: 5
regularizer:
name: 'L2'
coeff: 0.00004
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: ../../dataset/expression/
cls_label_path: ../../dataset/expression/train_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
interpolation: bicubic
backend: pil
- RandFlipImage:
flip_code: 1
- TimmAutoAugment:
config_str: rand-m7-mstd0.5-inc1
interpolation: bicubic
img_size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- RandomErasing:
EPSILON: 0.25
sl: 0.02
sh: 1.0/3.0
r1: 0.3
attempt: 10
use_log_aspect: True
mode: pixel
batch_transform_ops:
- OpSampler:
MixupOperator:
alpha: 0.2
prob: 0.5
CutmixOperator:
alpha: 1.0
prob: 0.5
sampler:
name: DistributedBatchSampler
batch_size: 128
drop_last: False
shuffle: True
loader:
num_workers: 16
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: ../../dataset/expression/
cls_label_path: ../../dataset/expression/val_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 236
interpolation: bicubic
backend: pil
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 128
drop_last: False
shuffle: False
loader:
num_workers: 16
use_shared_memory: True
Metric:
Train:
- TopkAcc:
topk: [1, 5]
Eval:
- TopkAcc:
topk: [1, 5]
然后使用下面的命令进行训练(使用4个GPU):
export CUDA_VISIBLE_DEVICES=0,1,2,3
python3 -m paddle.distributed.launch \
--gpus="0,1,2,3" \
tools/train.py \
-c expression.yaml
在训练过程中开启了visualdl,因此可以显式的看下具体的训练情况:
visualdl --logdir vdl
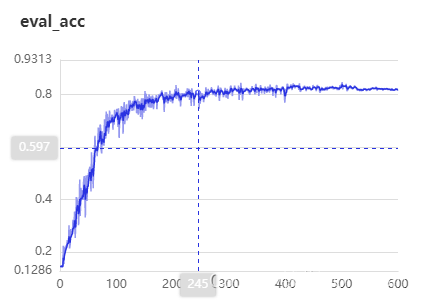
本次一共训练了600个epoch,在epoch=400时基本已达到收敛。在验证集上最佳best metric: 0.8466。
4.4 静态图导出
为了方便后面进行模型部署,我们将训练好的最佳模型进行静态图导出。具体命令如下:
python3 tools/export_model.py \
-c expression.yaml \
-o Global.pretrained_model=results/PPHGNet_small/best_model \
-o Global.save_inference_dir=results/models/PPHGNet_small_infer
结束后导出的静态图模型存放在results/models/PPHGNet_small_infer文件夹下面。
4.5 测试
下面我们从网上找一张实际的图片进行测试。这里注意,由于我们的模型使用的是紧凑人脸进行训练的,因此,我们进行测试的图片也需要先把紧凑的人脸区域裁剪出来再进行识别(按照第三节的方式自动裁剪人脸区域),如下图所示:


PaddleClas给我们提供好了可以使用静态图模型进行预测部署的脚本,通过cd命令进入到deploy文件夹中,然后在该文件中添加一个预测配置文件expression.yaml,内容如下:
Global:
infer_imgs: "../../../dataset/expression/test/test1.png"
inference_model_dir: "../results/models/PPHGNet_small_infer"
batch_size: 1
use_gpu: True
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: True
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
PreProcess:
transform_ops:
- ResizeImage:
size: [224, 224]
- NormalizeImage:
scale: 0.00392157
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
channel_num: 3
- ToCHWImage:
PostProcess:
main_indicator: Topk
Topk:
topk: 5
class_id_map_file: "../../../dataset/expression/label.txt"
SavePreLabel:
save_dir: ./pre_label/
可以使用下面的命令进行单张图像预测
python3 python/predict_cls.py -c expression.yaml
输出结果如下所示:
test7.png: class id(s): [5, 0, 6, 4, 1], score(s): [0.86, 0.02, 0.02, 0.02, 0.02], label_name(s): ['happy', 'normal', 'sad', 'angry', 'scared']
可以看到对于这张图片,top1对应的score值为0.86,对应类别是happy,预测还是比较准确的。
五、小结
本文从头开始实现了一个表情识别项目,包括人脸检测和表情识别两部分。依赖强大的PaddleClas套件,很快完成了一个工业级可用的表情识别功能。由于使用了算法套件,整体开发难度不大,实现都很顺畅。其它基于视觉的分类任务都可以参照这种方式进行开发。
下一步将继续开发一套完整的人脸识别项目,除了基本的训练和测试以外,还会讲解如何使用PaddleServing完成生产级部署,感兴趣的读者后面可以继续关注。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)