点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达

作者丨小马
来源丨我爱计算机视觉
本篇分享 CVPR 2022 论文『Image Segmentation Using Text and Image Prompts』,哥廷根大学提出了一个使用文本和图像prompt,能同时作三个分割任务的模型CLIPSeg,榨干CLIP的能力!
详细信息如下:

01
摘要
图像分割通常是通过为一组固定的对象类训练模型来解决的。之后合并其他类或更复杂的查询是昂贵的,因为它需要在包含这些表达式的数据集上重新训练模型。
在本文中,作者提出了一个可以在测试时根据任意prompt生成图像分割的系统。prompt可以是文本或图像。这种方法使模型能够为三个常见的分割任务创建一个统一的模型(只训练一次),这些任务具有不同的挑战:引用表达式分割、zero-shot分割和one-shot分割。
本文以 CLIP 模型为骨干,使用基于Transformer的解码器进行扩展,以实现密集预测。在对 PhraseCut 数据集的扩展版本进行训练后,本文的系统会根据自由文本prompt或表达查询的附加图像为图像生成二进制分割图。这种新颖的混合输入不仅可以动态适应上述三个分割任务,还可以适应任何可以制定文本或图像查询的二进制分割任务。最后,作者发现本文的系统能够很好地适应通用查询。
02
Motivation
泛化到没见过的数据的能力是与人工智能中的广泛应用相关的一个基本问题。例如,家用机器人理解用户的提示至关重要,这可能涉及没见过的对象类型或对象的不常见表达。虽然人类擅长这项任务,但这种形式的推理对计算机视觉系统来说是具有挑战性的。

图像分割需要一个模型来输出每个像素的预测。与图像分类相比,分割不仅需要预测可以看到的内容,还需要预测可以找到的位置。经典语义分割模型仅限于分割训练集中的类别。目前,已经出现了不同的方法来扩展这种相当受限的设置(如上表所示):
在广义的zero-shot分割中,需要通过将未见类别与已见类别相关联来分割已见和未见类别。
在one-shot分割中,除了要分割的查询图像之外,还以图像的形式提供所需的类。
在引用表达式分割(RES)中,模型在复杂的文本查询上进行训练,但在训练期间可以看到所有类(即没有对未见过的类进行泛化)。
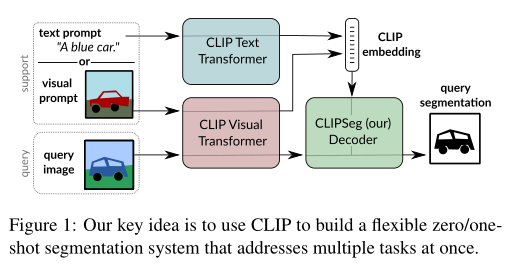
在这项工作中,作者引入了 CLIPSeg 模型(如上图),该模型能够基于任意文本查询或图像进行分割。CLIPSeg 可以解决上述所有三个任务。这种多模态输入格式超越了现有的多任务基准,例如 Visual Decathlon,其中输入始终以图像的形式提供。为了实现这个系统,作者使用预训练的 CLIP 模型作为主干,并在顶部训练一个轻量的条件分割层(解码器)。
作者使用CLIP 的联合文本-视觉嵌入空间来调节本文的模型,这使模型能够处理文本形式的prompt以及图像。本文的想法是教解码器将 CLIP 内的激活与输出分割相关联,同时允许尽可能少的数据集偏差并保持 CLIP 的出色和广泛的预测能力。
本文采用通用的二进制预测设置,其中与prompt匹配的前景必须与背景区分开来。这种二进制设置可以适应Pascal zero-shot分割所需的多标签预测。虽然本文工作的重点是建设一个通用模型,作者发现 CLIPSeg 在三个low-shot分割任务中实现了竞争性能。此外,它能够泛化到它从未见过分割的类和表达式。
本文的主要技术贡献是 CLIPSeg 模型,它通过提出一种基于 Transformer 的轻量级解码器,扩展了著名的 CLIP Transformer 用于 zero-shot 和 one-shot 分割任务。该模型的一个关键新颖之处在于分割目标可以通过不同的方式指定:通过文本或图像。
这使模型能够为多个基准训练一个统一的模型。对于基于文本的查询,与在 PhraseCut 上训练的网络不同,本文的模型能够泛化到涉及看不见的单词的新查询。对于基于图像的查询,作者探索了各种形式的视觉prompt 工程——类似于语言建模中的文本prompt 工程。
03
方法
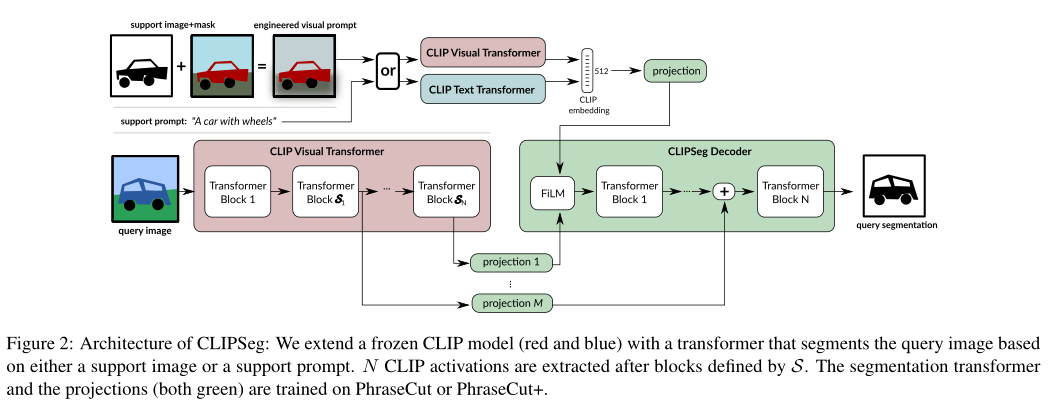
作者使用基于视觉Transformer的 (ViT-B/16) CLIP模型作为主干,并使用小型、参数高效的Transformer解码器对其进行扩展。解码器在自定义数据集上进行训练以执行分割,而 CLIP 编码器保持冻结状态。一个关键的挑战是避免在分割训练期间对预测施加强烈的bias并保持 CLIP 的多功能性。
考虑到这些需求,作者提出了 CLIPSeg:一个简单的、纯基于Transformer的解码器。当查询图像 () 通过 CLIP 视觉Transformer时,某些层 S 的激活被读取并投影到解码器的token嵌入大小 D。然后,这些提取的激活(包括 CLS token)在每个Transformer之前添加到解码器的内部激活中。
解码器具有与提取的 CLIP 激活一样多的Transformer块。解码器通过在其Transformer(最后一层) 的token上应用线性投影来生成二进制分割,其中 P 是 CLIP 的patch大小。为了告知解码器分割目标,作者使用 FiLM通过条件向量调制解码器的输入激活。
这个条件向量可以通过两种方式获得:(1) 使用文本查询的 CLIP 文本Transformer嵌入和 (2) 在特征工程prompt图像上使用 CLIP 视觉Transformer。CLIP 本身没有经过训练,仅用作冻结特征提取器。由于紧凑的解码器,对于 D = 64,CLIPSeg 只有 1,122,305 个可训练参数。
由于学习到的位置嵌入,原始 CLIP 被限制为固定的图像大小。本文通过插入位置嵌入来启用不同的图像大小(包括更大的图像)。为了验证这种方法的可行性,作者比较了不同图像尺寸的预测质量,发现对于大于 350 像素的图像,ViT-B/16 的性能只会降低。
在本文的实验中,作者使用 CLIP ViT-B/16,patch大小 P 为 16,如果没有另外说明,则使用 D = 64 的投影尺寸。作者在 S = [3 , 7 , 9] 层提取 CLIP 激活,因此本文的解码器只有三层。
模型通过条件向量接收有关分割目标的信息(“要分割什么?”),这可以通过文本或图像(通过视觉prompt工程)提供。由于 CLIP 为图像和文本标题使用共享嵌入空间,可以在嵌入空间和插值向量上的条件之间进行插值。形式上,设是支持图像的嵌入,是样本 i 的文本嵌入,作者通过线性插值获得条件向量 ,其中 a 是从[0 , 1]均匀采样 。作者在训练期间使用这种随机插值作为数据增强策略。
3.1 PhraseCut + Visual prompts (PC+)
本文使用 PhraseCut 数据集,其中包含超过 340,000 个具有相应图像分割的短语。最初,该数据集不包含视觉支持,而仅包含短语,并且每个短语都存在相应的对象。作者以两种方式扩展这个数据集:视觉支持样本和负样本。为了为prompt p 添加视觉支持图像,作者从共享prompt p 的所有样本的集合中随机抽取。
此外,作者将负样本引入数据集,即没有对象与prompt匹配的样本。为此,样本的短语被替换为概率为的不同短语。短语使用一组固定前缀随机扩充。在考虑到对象位置的情况下,作者在图像上应用随机裁剪,确保对象至少部分可见。在本文的其余部分,将此扩展数据集称为 PhraseCut+(缩写为 PC+)。与仅使用文本来指定目标的原始 PhraseCut 数据集相比,PC+ 支持使用图像-文本插值进行训练。这样,本文可以训练一个对文本和视觉输入进行操作的联合模型。
3.2 Visual Prompt Engineering
在传统的基于 CNN 的one-shot语义分割中,masked pooling 已成为计算用于条件的原型向量的标准技术。提供的支持mask被下采样并与来自 CNN 沿空间维度的后期特征图相乘,然后沿空间维度汇集。这样,只有与支持对象有关的特征才被考虑在原型向量中。
这种方法不能直接应用于基于Transformer的架构,因为语义信息也在整个层次结构中的 CLS token中积累,而不仅仅是在特征图中。绕过 CLS token并直接从特征图的masked pooling中导出条件向量也是不可能的,因为它会破坏文本嵌入和 CLIP 视觉嵌入之间的兼容性。
为了更多地了解如何将目标信息整合到 CLIP 中,作者在一个没有分割的简单实验中比较了几个变体及其混杂效应。作者考虑视觉和基于文本的嵌入之间的余弦距离(对齐),并使用原始 CLIP 权重而无需任何额外的训练。

具体来说,作者使用 CLIP 来计算对应于图像中对象名称的文本嵌入。然后,将它们与原始图像的视觉嵌入和使用修改后的 RGB 图像或注意力mask突出显示目标对象的视觉嵌入进行比较。通过对对齐向量进行softmax,获得了如上图所示的分布。
对于定量分数,作者只考虑目标对象名称嵌入,希望它与突出显示的图像嵌入比与原始图像嵌入具有更强的对齐。这意味着,如果突出显示技术改进了对齐方式,则对象概率的增加应该很大。作者基于LVIS 数据集进行分析,因为它的图像包含多个对象和一组丰富的类别。
CLIP-Based Masking
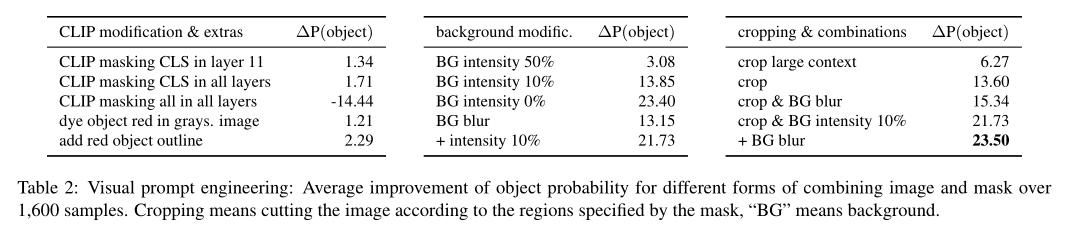
直接等效于视觉Transformer中的masked pooling是将mask应用于token。通常,视觉Transformer由一组固定的token组成,这些token可以通过多头注意力在每一层进行交互:用于读取的 CLS token和最初从图像patch中获得的与图像区域相关的token。
现在,可以通过将一个或多个Transformer层的交互约束到mask内patch token以及仅 CLS token来合并mask。上表(左)表明这种引入mask的形式效果不佳。通过限制与 CLS token的交互(上表 左,顶部两行),仅实现了小的改进,而限制所有交互会显着降低性能。由此得出结论,在内部结合图像和mask需要更复杂的策略。
Visual Prompt Engineering
除了在模型中应用mask,还可以将mask和图像组合成一个新图像,然后由视觉Transformer处理。类似于 NLP 中的prompt工程(例如在 GPT-3 中),作者将此过程称为视觉prompt工程。由于这种形式的prompt设计是新颖的,并且在这种情况下表现最好的策略是未知的,作者对设计视觉prompt的不同变体进行了广泛的评估。
发现mask和图像如何组合的确切形式非常重要。作者确定了三种图像操作来改善对象文本prompt和图像之间的对齐:降低背景亮度、模糊背景(使用高斯滤波器)和裁剪到对象。所有三者的组合表现最好。因此在其余部分,将使用这个变体。
04
实验

上表展示了在原始 PhraseCut 数据集上评估referring expression segmentation(RES)的性能对比。
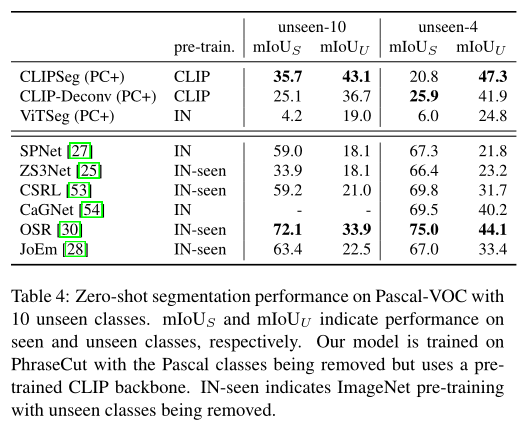
在广义zero-shot分割中,测试图像除了包含已知类别外,还包含以前从未见过的类别。作者使用 Pascal-VOC 基准评估模型的zero-shot分割性能,性能如上表。
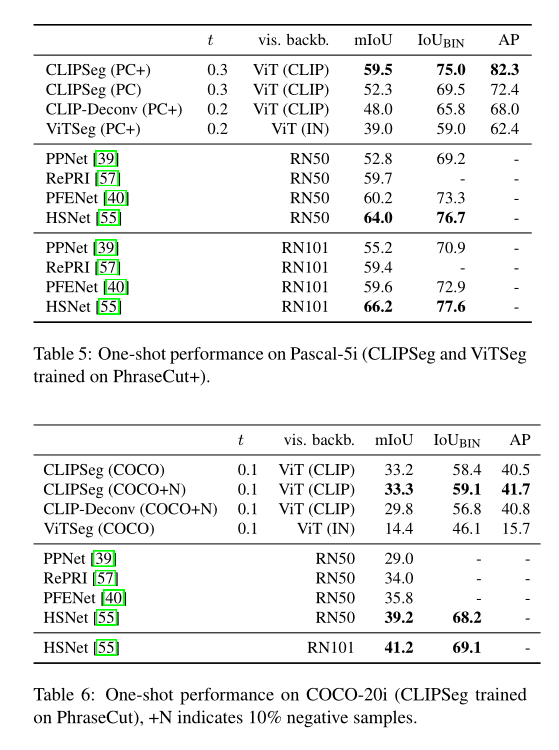
在 Pascal-5i 上,本文的通用模型 CLIPSeg (PC+) 在最先进的方法中实现了具有竞争力的性能,只有最近的 HSNet 表现更好。COCO-20i 上的结果表明 CLIPSeg 在除 PhraseCut(+) 之外的其他数据集上训练时也能很好地工作。
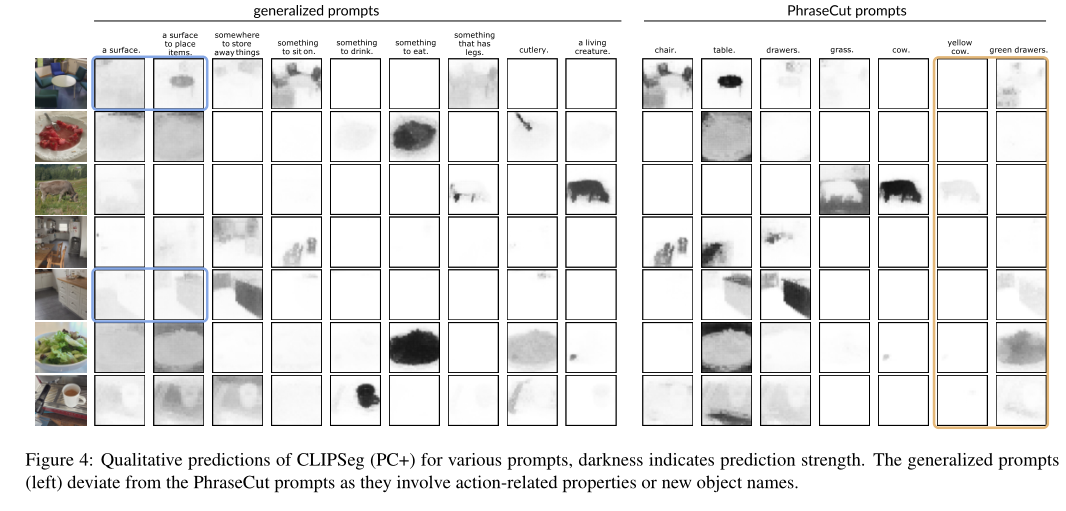
上图展示了CLIPSeg(PC+)对各种prompt的定性预测,深色表示预测强度。
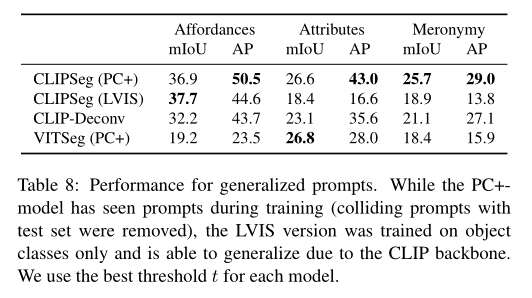
从上表中,可以发现在 PC+ 上训练的 CLIPSeg 版本的性能优于 CLIP-Deconv baseline和在 L VIS 上训练的版本,后者仅包含对象标签而不是复杂的短语。这一结果表明,数据集的可变性和模型的复杂性都是泛化所必需的。
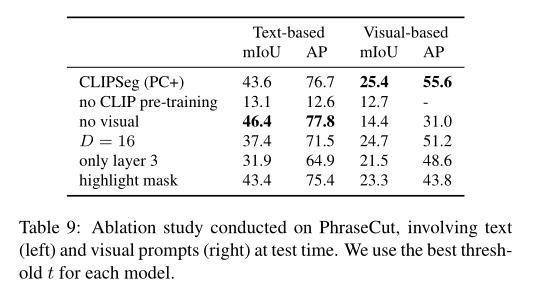
为了确定 CLIPSeg 性能的关键因素,作者对 PhraseCut 进行了消融研究。,如上表所示,作者分别评估基于文本和基于视觉prompt的性能以获得完整的图片。当使用随机权重而不是 CLIP 权重时(“无 CLIP 预训练”),基于文本的性能和视觉性能都会下降。当参数数量减少到 16 个(“D = 16”)时,性能大幅下降,这表明解码器中信息处理的重要性。使用不利的视觉prompt技术会降低视觉输入的性能。
05
总结
本文提出了 CLIPSeg 图像分割方法,该方法可以在推理时通过文本或图像提示适应新任务,而不是对新数据进行昂贵的训练。具体来说,作者详细研究了新颖的视觉prompt工程,并展示了在表达式分割、zero-shot分割和one-shot分割任务上的竞争性能。除此之外,作者在定性和定量上都证明了本文的模型可以推广到新prompt。
作者认为本文的方法是有用的,特别是对于没有经验的用户,通过指定提示和需要与人类交互的机器人设置来构建分割模型。处理多项任务是未来研究更通用和与现实世界兼容的视觉系统的一个有希望的方向。本文的实验,特别是与基于ImageNet 的 ViTSeg baseline的比较,突出了像 CLIP 这样的基础模型在一次解决多个任务方面的能力。
参考资料
[1]https://arxiv.org/abs/2112.10003
[2]https://github.com/timojl/clipseg
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
计算机视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
16.基于Open3D的点云处理入门与实战教程
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~