图像检索(Content-based Image Retrieval,简称CBIR)即以图搜图,基于图片语义信息,诸如颜色、纹理、布局、CNN-based高层语义等特征检索技术。该技术可分为实例和类别检索任务。前者,即给定一张物体/场景/建筑类型的待查询图片,查询出包含拍摄自不同角度、光照或有遮挡的,含有相同物体/场景/建筑的图片;后者是检索出同类别的图片。当前需求更贴合实例图像检索。
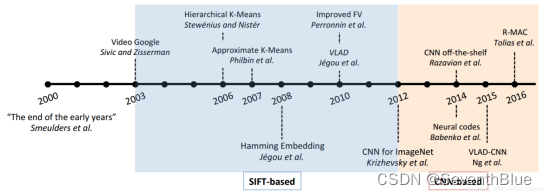
CBIR研究在20世纪90年代早期正式开始,研究人员根据诸如纹理、颜色这样的视觉特征对图像建立索引,在这一时期大量优秀算法和图像检索系统被提出。不一一表述。时间拉到2000年后,如图2.1中所示,展示了多年来实例检索任务中的里程碑时刻,并且在图中着重标出了基于SIFT特征和CNN特征算法的提出的时间。2000年可以认为是大部分传统方法结束的时间,当时Smeulders等撰写了“早期的终结”这篇综述。三年后(2003),词袋模型(BoW)进入图像检索社区的视野,并在2004年结合了SIFT方法符被应用于图像分类任务。这后来的近10年时间里,社区见证了BoW模型的优越性,它给图像检索任务带来了各种提升。在2012年,Krizhevsky等人使用AlexNet在ILSRVC 2012上取得了当时世界上最高的识别准确率。至此之后,研究的重心开始向基于深度学习特别是卷积神经网络(CNN)的方法转移。
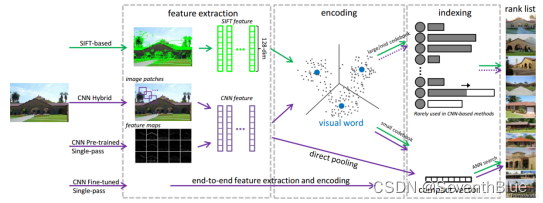
下面是一个简易的图像检索代码:
cbir.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time :2022/7/6 11:26
# @Author :weiz
# @ProjectName :CBIR-master
# @File :cbir.py
# @Description :content-based image retrieval
# Copyright (C) 2021-2025 Jiangxi Institute Of Intelligent Industry Technology Innovation
import os
import cv2
from six.moves import cPickle
from scipy import spatial
from feature_extraction import *
from vgg import *
class CBIR(object):
database_feature_path = "./database_feature"
def read_images(self, image_folder_path):
self.image_info_list = []
for root, _, image_name_list in os.walk(image_folder_path, topdown=False):
label_name = root.split('/')[-1].split('\\')[-1]
for image_name in image_name_list:
if image_name.split('.')[-1] in ["png", "jpg", "jpeg"]:
image_path = os.path.join(root, image_name)
self.image_info_list.append([image_path, label_name])
else:
print("{} is not a picture".format(os.path.join(root, image_name)))
def load_database(self, image_folder_path=None, is_save=False):
self.database = []
database_feature_path = CBIR.database_feature_path + '_' + self.feature_extraction_object.get_name()
if os.path.exists(database_feature_path) and not image_folder_path:
self.database = cPickle.load(open(database_feature_path, "rb", True))
else:
if image_folder_path:
self.read_images(image_folder_path)
for image_info in self.image_info_list: # [[图片路径, 类别]...]
image = cv2.imread(image_info[0])
feature = self.feature_extraction_object(image)
self.database.append({
'image_path': image_info[0],
'label': image_info[1],
'feature': feature
})
if is_save:
cPickle.dump(self.database, open(database_feature_path, "wb", True))
return self.database
def __init__(self, feature_extraction_object, image_folder_path):
self.feature_extraction_object = feature_extraction_object
self.read_images(image_folder_path)
# print(self.image_info_list)
self.load_database(is_save=True)
# print(self.database)
def query(self, image, query_depth=3, is_show=False):
feature_1 = self.feature_extraction_object(image)
query = []
for idx, value_2 in enumerate(self.database):
image_path_2, label_2, feature_2 = value_2["image_path"], value_2["label"], value_2["feature"]
query.append({
"distance": self.distance(feature_1, feature_2, "d3"),
"label": label_2,
"image_path": image_path_2
})
# 如果候选深度足够,取前query_depth个
query = sorted(query, key=lambda x: x["distance"])
if query_depth and query_depth <= len(query):
query = query[:query_depth]
if is_show:
cv2.imshow("src", image)
for idx, q in enumerate(query):
img = cv2.imread(q["image_path"])
cv2.imshow("top {}".format(idx + 1), img)
cv2.waitKey(0)
cv2.destroyAllWindows()
return query
def evaluate(self, database=None, query_depth=3):
if not database:
database = self.database
label_list = []
for tmp in database:
label_list.append(tmp["label"])
label_list = list(set(label_list))
results = {c: [] for c in label_list}
for value_1 in database:
image_path_1, label_1, feature_1 = value_1["image_path"], value_1["label"], value_1["feature"]
query = []
for idx, value_2 in enumerate(database):
image_path_2, label_2, feature_2 = value_2["image_path"], value_2["label"], value_2["feature"]
if image_path_1 == image_path_2: # 同一图片不参与评估
continue
query.append({
"distance": self.distance(feature_1, feature_2, "d3"),
"label": label_2
})
# 如果候选深度足够,取前query_depth个
query = sorted(query, key=lambda x: x["distance"])
# print(query)
if query_depth and query_depth <= len(query):
query = query[:query_depth]
# 计算有多少被hit
hit = 0
precision = []
for idx, q in enumerate(query):
if q["label"] == label_1:
hit += 1
precision.append((hit / (idx + 1.)))
# else:
# print("原始目标, path:{} label:{}".format(value_1["image_path"], value_1["label"]))
# print("预测目标, distance:{} label:{}".format(q["distance"], q["label"]))
if hit == 0:
results[label_1].append(0.)
else:
results[label_1].append(np.mean(precision))
mAPs = []
for label, Ps in results.items():
AP = np.mean(Ps)
print("Class {}, AP {}".format(label, AP))
mAPs.append(AP)
print("MAP", np.mean(mAPs))
return results
def distance(self, value_1, value_2, d_type="d1"):
assert value_1.shape == value_2.shape
if d_type == 'd1': # 曼哈顿距离
return np.sum(np.absolute(value_1 - value_2))
elif d_type == 'd2': # 欧几里得距离
return np.sqrt(np.sum((value_1 - value_2) ** 2))
elif d_type == 'd3': # 余弦相似度
return spatial.distance.cosine(value_1, value_2)
test_image_path = "./database/cup2" # ./test_image ./database/glasses
if __name__ == "__main__":
vgg_model = VGGNet(requires_grad=False, net_type="vgg16", show_params=False)
vgg_model.eval()
if torch.cuda.is_available():
vgg_model = vgg_model.cuda()
cbir = CBIR(vgg_model, "./database")
# cbir.evaluate(query_depth=3)
test_image_list = os.listdir(test_image_path)
for image_name in test_image_list[:3]:
print(image_name)
image_path = os.path.join(test_image_path, image_name)
test_image = cv2.imread(image_path)
print(cbir.query(test_image, is_show=True, query_depth=2))
feature_extraction.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time :2022/7/11 11:20
# @Author :weiz
# @ProjectName :CBIR-master
# @File :feature_extraction.py
# @Description :
# Copyright (C) 2021-2025 Jiangxi Institute Of Intelligent Industry Technology Innovation
import torch
import torch.nn as nn
from torchvision import models
from torchvision.models.vgg import VGG
import numpy as np
class VGGNet(VGG):
cfg = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512,'M'],
}
ranges = {
'vgg11': ((0, 3), (3, 6), (6, 11), (11, 16), (16, 21)),
'vgg13': ((0, 5), (5, 10), (10, 15), (15, 20), (20, 25)),
'vgg16': ((0, 5), (5, 10), (10, 17), (17, 24), (24, 31)),
'vgg19': ((0, 5), (5, 10), (10, 19), (19, 28), (28, 37))
}
means = np.array([103.939, 116.779, 123.68]) / 255. # mean of three channels in the order of BGR
def net_layers(self, net_type, batch_norm=False):
"""
构建网络层
"""
layers = []
in_channels = 3
for value in VGGNet.cfg[net_type]:
if 'M' == value:
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, value, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(value), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = value
return nn.Sequential(*layers)
def __init__(self, pretrained=True, net_type='vgg16', requires_grad=False, remove_fc=False, show_params=False):
"""
初始化
"""
super().__init__(self.net_layers(net_type))
self.ranges = VGGNet.ranges[net_type]
self.fc_ranges = ((0, 2), (2, 5), (5, 7))
self.net_type = net_type
# print(self.features.state_dict())
if pretrained:
exec("self.load_state_dict(models.%s(pretrained=True).state_dict())" % net_type)
if not requires_grad:
for param in super().parameters():
param.requires_grad = False
if remove_fc: # 不需要全连接层,删除
self.classifier = None
self.avgpool = None
if show_params:
for name, param in self.named_parameters():
print(name, param.size())
def forward(self, image):
"""
image格式需要BGR格式
"""
# image = image[:, :, ::-1]
image = np.transpose(image, (2, 0, 1)) / 255.
image[0] -= VGGNet.means[0] # reduce B's mean
image[1] -= VGGNet.means[1] # reduce G's mean
image[2] -= VGGNet.means[2] # reduce R's mean
image = np.expand_dims(image, axis=0)
if torch.cuda.is_available():
inputs = torch.autograd.Variable(torch.from_numpy(image).cuda().float())
else:
inputs = torch.autograd.Variable(torch.from_numpy(image).float())
# print(inputs.shape)
# print(self.features)
x = self.features(inputs)
avg_pool = torch.nn.AvgPool2d((x.size(-2), x.size(-1)), stride=(x.size(-2), x.size(-1)),
padding=0, ceil_mode=False, count_include_pad=True)
feature = avg_pool(x) # avg.size = N * 512 * 1 * 1
feature = feature.view(feature.size(0), -1) # avg.size = N * 512
feature = np.sum(feature.data.cpu().numpy(), axis=0)
feature /= np.sum(feature) # normalize
return feature
def get_name(self):
return self.net_type
def __coll__(self, x):
return self.forward(x)
数据库如下格式即可。

数据
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)