TinyKv Project2 PartB RaftKV
- 前言
- Project2 PartB RaftKV 文档翻译
- PartB 到底想让我们做什么?
- 分析要实现的函数到底要干什么事情
- proposeRaftCommand 将上层命令打包成日志发送给raft
- HandleRaftReady 处理已经Ready的数据
- SaveReadyState - 持久化
- Append - 持久化日志
- 结构体与一些流程介绍
- make project2b 看看~
前言
partB部分主要是做持久化相关的内容,Build a fault-tolerant KV server on top of Raft:在Raft基础之上构建一个容错KV服务器。
Project2 PartB RaftKV 文档翻译
在这一部分中,你将使用 Part A 中实现的 Raft 模块建立一个容错的KV存储服务。服务将是一个复制状态机,由几个使用 Raft 进行复制的KV服务器组成。KV服务应该继续处理客户的请求,只要大多数的服务器是活的并且可以通信,尽管有其他的故障或网络分区发生。
在 Project1 中,你已经实现了一个独立的kv服务器,所以你应该已经熟悉了kv服务器的 API 和 Storage 接口。
在介绍代码之前,你需要先了解三个术语:Store、Peer 和 Region,它们定义在proto/proto/metapb.proto 中。
- Store 代表 tinykv-server 的一个实例
- Peer 代表运行在 Store 上的 Raft 节点
- Region 是 Peer 的集合,也叫 Raft 组
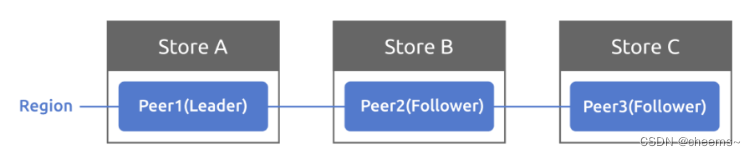
为了简单起见,在 Project2 的集群中,一个 Store 上只有一个 Peer,一个 Region。所以现在不需要考虑Region的范围。多个区域将在 Project3 中进一步引入。
代码
首先,你应该看看位于 kv/storage/raft_storage/raft_server.go 中的 RaftStorage 的代码,它也实现了存储接口。与 StandaloneStorage 直接从底层引擎写入或读取不同,它首先将每个写入或读取请求发送到 Raft,然后在 Raft 提交请求后对底层引擎进行实际写入和读取。通过这种方式,它可以保持多个 Stores 之间的一致性。
RaftStorage 主要创建一个 Raftstore 来驱动 Raft。当调用 Reader 或 Write 函数时,它实际上是通过 channel (该通道的接收者是 raftWorker 的 raftCh)向 raftstore 发送 proto/proto/raft_cmdpb.proto 中定义的 RaftCmdRequest,其中有四种基本的命令类型(Get/Put/Delete/Snap),在 Raft 提交并应用该命令后返回响应。而读写函数的 kvrpc.Context 参数现在很有用,它从客户端的角度携带了 Region 信息,并作为 RaftCmdRequest 的 Head 传递。也许这些信息是错误的或过时的,所以 raftstore 需要检查它们并决定是否提出请求。
然后,这里是TinyKV的核心 - raftstore。这个结构有点复杂,你可以阅读TiKV的参考资料,让你对这个设计有更好的了解。
https://pingcap.com/blog-cn/the-design-and-implementation-of-multi-raft/
https://pingcap.com/blog/2017-08-15-multi-raft/
raftstore 的入口是 Raftstore,见 kv/raftstore/raftstore.go。它启动了一些Worker 来异步处理特定的任务,现在大部分都没有用到,所以你可以直接忽略它们。你所需要关注的是 raftWorker。(kv/raftstore/raft_worker.go)
整个过程分为两部分:raft worker 轮询 raftCh 以获得消息,这些消息包括驱动 Raft 模块的基本 tick 和作为 Raft 日志项的 Raft 命令;它从 Raft 模块获得并处理 ready,包括发送raft消息、持久化状态、将提交的日志项应用到状态机。一旦应用,将响应返回给客户。
实现 peer storage
peer storage 是通过 Part A 中的存储接口进行交互,但是除了 raft 日志之外,peer storage 还管理着其他持久化的元数据,这对于重启后恢复到一致的状态机非常重要。此外,在 proto/proto/raft_serverpb.proto 中定义了三个重要状态。
- RaftLocalState:用于存储当前 Raft hard state 和 Last Log Index。
- RaftApplyState。用于存储 Raft applied 的 Last Log Index 和一些 truncated Log 信息。
- RegionLocalState。用于存储 Region 信息和该 Store 上的 Peer State。Normal表示该 peer 是正常的,Tombstone表示该 peer 已从 Region 中移除,不能加入Raft 组。
这些状态被存储在两个badger实例中:raftdb 和 kvdb。
- raftdb 存储 raft 日志和 RaftLocalState。
- kvdb 在不同的列族中存储键值数据,RegionLocalState 和 RaftApplyState。你可以把 kvdb 看作是Raft论文中提到的状态机。
你可能想知道为什么 TinyKV 需要两个 badger 实例。实际上,它只能使用一个badger 来存储 Raft 日志和状态机数据。分成两个实例只是为了与TiKV的设计保持一致。
这些元数据应该在 PeerStorage 中创建和更新。当创建 PeerStorage 时,见kv/raftstore/peer_storage.go 。它初始化这个 Peer 的 RaftLocalState、RaftApplyState,或者在重启的情况下从底层引擎获得之前的值。注意,RAFT_INIT_LOG_TERM 和 RAFT_INIT_LOG_INDEX 的值都是5(只要大于1),但不是0。之所以不设置为0,是为了区别于 peer 在更改 conf 后被动创建的情况。你现在可能还不太明白,所以只需记住它,细节将在 project3b 中描述,当你实现 conf change 时。
在这部分你需要实现的代码只有一个函数 PeerStorage.SaveReadyState,这个函数的作用是将 raft.Ready 中的数据保存到 badger 中,包括追加日志和保存 Raft 硬状态。
要追加日志,只需将 raft.Ready.Entries 处的所有日志保存到 raftdb,并删除之前追加的任何日志,这些日志永远不会被提交。同时,更新 peer storage 的RaftLocalState 并将其保存到 raftdb。
保存硬状态也很容易,只要更新peer storage 的 RaftLocalState.HardState 并保存到raftdb。
提示:
- 使用WriteBatch来一次性保存这些状态。
- 关于如何读写这些状态,请参见 peer_storage.go 的其他函数。
实现Raft ready 过程
在 Project2 的 PartA ,你已经建立了一个基于 tick 的 Raft 模块。现在你需要编写驱动它的外部流程。大部分代码已经在 kv/raftstore/peer_msg_handler.go 和kv/raftstore/peer.go 下实现。所以你需要学习这些代码,完成proposalRaftCommand 和 HandleRaftReady 的逻辑。下面是对该框架的一些解释。
Raft RawNode 已经用 PeerStorage 创建并存储在 peer 中。在 raft Worker 中,你可以看到它接收了 peer 并通过 peerMsgHandler 将其包装起来。peerMsgHandler主要有两个功能:一个是 HandleMsgs,另一个是 HandleRaftReady。
HandleMsgs 处理所有从 raftCh 收到的消息,包括调用 RawNode.Tick() 驱动Raft的MsgTypeTick、包装来自客户端请求的 MsgTypeRaftCmd 和 Raft peer 之间传送的MsgTypeRaftMessage。所有的消息类型都在 kv/raftstore/message/msg.go 中定义。你可以查看它的细节,其中一些将在下面的部分中使用。
在消息被处理后,Raft 节点应该有一些状态更新。所以 HandleRaftReady 应该从Raft 模块获得Ready,并做相应的动作,如持久化日志,应用已提交的日志,并通过网络向其他 peer 发送 raft 消息。
在一个伪代码中,raftstore 使用 Raft:
for {
select {
case <-s.Ticker:
Node.Tick()
default:
if Node.HasReady() {
rd := Node.Ready()
saveToStorage(rd.State, rd.Entries, rd.Snapshot)
send(rd.Messages)
for _, entry := range rd.CommittedEntries {
process(entry)
}
s.Node.Advance(rd)
}
}
在这之后,整个读或写的过程将是这样的:
- 客户端调用 RPC RawGet/RawPut/RawDelete/RawScan
- RPC 处理程序调用 RaftStorage 的相关方法
- RaftStorage 向 raftstore 发送一个 Raft 命令请求,并等待响应
- RaftStore 将 Raft 命令请求作为 Raft Log 提出。
- Raft 模块添加该日志,并由 PeerStorage 持久化。
- Raft 模块提交该日志
- Raft Worker 在处理 Raft Ready 时执行 Raft 命令,并通过 callback 返回响应。
- RaftStorage 接收来自 callback 的响应,并返回给 RPC 处理程序。
- RPC 处理程序进行一些操作并将 RPC 响应返回给客户。
你应该运行 make project2b 来通过所有的测试。整个测试正在运行一个模拟集群,包括多个 TinyKV 实例和一个模拟网络。它执行一些读和写的操作,并检查返回值是否符合预期。
要注意的是,错误处理是通过测试的一个重要部分。你可能已经注意到,在proto/proto/errorpb.proto 中定义了一些错误,错误是 gRPC 响应的一个字段。同时,在 kv/raftstore/util/error.go 中定义了实现 error 接口的相应错误,所以你可以把它们作为函数的返回值。
这些错误主要与 Region 有关。所以它也是 RaftCmdResponse 的 RaftResponseHeader 的一个成员。当提出一个请求或应用一个命令时,可能会出现一些错误。如果是这样,你应该返回带有错误的 Raft 命令响应,然后错误将被进一步传递给 gRPC 响应。你可以使用 kv/raftstore/cmd_resp.go 中提供的 BindErrResp,在返回带有错误的响应时,将这些错误转换成 errorpb.proto 中定义的错误。
在这个阶段,你可以考虑这些错误,其他的将在 Project3 中处理。
- ErrNotLeader:raft 命令是在一个 Follower 上提出的。所以用它来让客户端尝试其他 peer。
- ErrStaleCommand:可能由于领导者的变化,一些日志没有被提交,就被新的领导者的日志所覆盖。但是客户端并不知道,仍然在等待响应。所以你应该返回这个命令,让客户端知道并再次重试该命令。
提示:
- PeerStorage 实现了 Raft 模块的存储接口,你应该使用提供的SaveRaftReady() 方法来持久化Raft的相关状态。
- 使用 engine_util 中的 WriteBatch 来进行原子化的多次写入,例如,你需要确保在一个写入批次中应用提交的日志并更新应用的索引。
- 使用 Transport 向其他 peer 发送 raft 消息,它在 GlobalContext 中。
- 服务器不应该完成 RPC,如果它不是多数节点的一部分,并且没有最新的数据。你可以直接把获取操作放到 Raft 日志中,或者实现 Raft 论文第8节中描述的对只读操作的优化。
- 在应用日志时,不要忘记更新和持久化应用状态机。
- 你可以像TiKV那样以异步的方式应用已提交的Raft日志条目。这不是必须的,虽然对提高性能是一个很大的提升。
- 提出命令时记录命令的 callback,应用后返回 callback。
- 对于 snap 命令的响应,应该明确设置 badger Txn 为 callback。
PartB 到底想让我们做什么?
Build a fault-tolerant KV server on top of Raft(在Raft基础之上构建一个容错KV服务器。)
在partA中,我们实现了raft协议,并封装了一层与上层交互的接口。那么在partB中,我们就需要去实现真正的存储,将日志持久化,将apply的日志放入状态机去执行并返回结果。
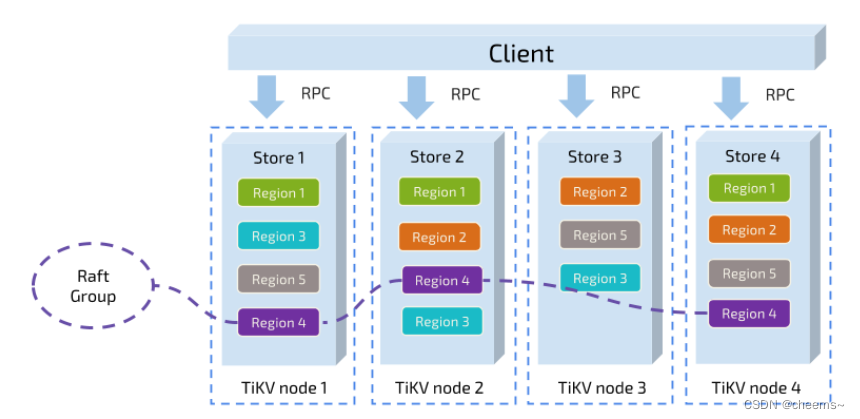
在此介绍三个名词,在后面的project中会用到
-
Store:每一个节点服务器叫做一个 store,也就是一个节点上面只有一个 Store。代码里面叫 RaftStore,后面统一使用 RaftStore 代称。
-
Peer:一个 RaftStore 里面会包含多个 peer,一个 RaftStore 里面的所有 peer 公用同一个底层存储,也就是多个 peer 公用同一个 badger 实例,一个peer对应一个raft节点。
-
Region:一个 Region 叫做一个 Raft group,即同属一个 raft 集群,一个 region 包含多个 peer,这些 peer 散落在不同的 RaftStore 上。
在partB中,就三个函数需要我们去实现,分别在peer_msg_handler.go 和 peer_storage.go 中。
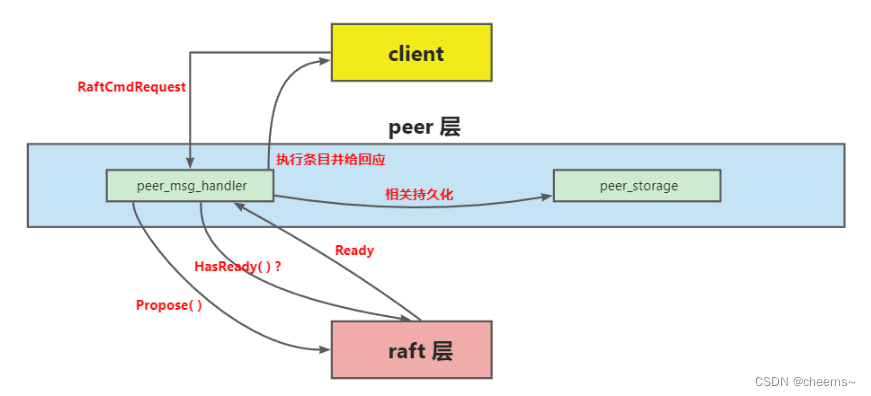
这里将 Rawnode-Raft-RaftLog 统称为 raft 层,把要实现的部分称为 peer 层。peer 层首先接收来自 client 的 RaftCmdRequest,其中包含着不同的命令请求,接着它会把这些请求逐一以 entry 的形式传递给 raft 层,当然,这个 peer 应该是 Leader,不然 client 会找下一个 peer 继续试。raft 层收到条目后,会在集群内部进行同步,这就是 project2a 的内容。同步的过程中,peer 层会不时询问 raft 层有哪些已经同步好的 entry 可以拿来应用(执行)?哪些 entry 需要持久化?有没有快照需要应用?等等。 如果有ready返回回来,那就根据其中的内容去做持久化,应用快照,执行apply到状态机等等。
func (d *peerMsgHandler) proposeRaftCommand(msg *raft_cmdpb.RaftCmdRequest, cb *message.Callback) {
err := d.preProposeRaftCommand(msg)
if err != nil {
cb.Done(ErrResp(err))
return
}
}
func (d *peerMsgHandler) HandleRaftReady() {
if d.stopped {
return
}
}
func (ps *PeerStorage) SaveReadyState(ready *raft.Ready) (*ApplySnapResult, error) {
}
func (ps *PeerStorage) Append(entries []eraftpb.Entry, raftWB *engine_util.WriteBatch) error {
}
分析要实现的函数到底要干什么事情
proposeRaftCommand 将上层命令打包成日志发送给raft
该方法会将 client 的请求包装成 entry 传递给 raft 层。client 会传来一个 msg(类型为 *raft_cmdpb.RaftCmdRequest)。其中,该结构中包含了 Requests 字段和 AdminRequest 字段,即两种命令请求。在 project2B 中,暂时只用到 Requests 字段。核心分为两步:
- 在请求发过来的时候,同时会附带一个回调函数,我们需要记录这个回调函数与本条日志的索引,等待apply这条记录到状态机执行完后,就回调它,并将返回值返回。简单来说,就是封装回调
- 将这个Msg序列化,通过昨天的partA的rawnode封装的Propse接口将消息传递进去
proposals 是 封装的回调结构体,是一个切片。当上层想要让 peer 执行一些命令时,会发送一个 RaftCmdRequest 给该 peer,而这个 RaftCmdRequest 里有很多个 Request,需要底层执行的命令就在这些 Requset 中。这些 Request 会被封装成一个 entry 交给 peer 去在集群中同步。当 entry 被 apply 时,对应的命令就会被执行。
上层怎么知道底层的这些命令真的被执行并且得到命令的执行结果呢?这就是 callback 的作用。每当 peer 接收到 RaftCmdRequest 时,就会给里面的每一个 Request 一个 callback,然后封装成 proposal,其中 term 就为该 Request 对应 entry 生成时的 term 以及 index。
当 rawNode 返回一个 Ready 回去时,说明上述那些 entries 已经完成了同步,因此上层就可以通过 HandleRaftReady 对这些 entries 进行 apply(即执行底层读写命令)。每执行完一次 apply,都需要对 proposals 中的相应 Index 的 proposal 进行 callback 回应(调用 cb.Done()),表示这条命令已经完成了(如果是 Get 命令还会返回取到的 value),然后从中删除这个 proposal。
func (d *peerMsgHandler) proposeRaftCommand(msg *raft_cmdpb.RaftCmdRequest, cb *message.Callback) {
err := d.preProposeRaftCommand(msg)
if err != nil {
cb.Done(ErrResp(err))
return
}
if msg.Requests != nil {
d.proposeRequest(msg, cb)
} else {
}
}
func (d *peerMsgHandler) proposeRequest(msg *raft_cmdpb.RaftCmdRequest, cb *message.Callback) {
d.proposals = append(d.proposals, &proposal{
index: d.RaftGroup.Raft.RaftLog.LastIndex() + 1,
term: d.RaftGroup.Raft.Term,
cb: cb,
})
data, err := msg.Marshal()
if err != nil {
log.Panic(err)
}
err = d.RaftGroup.Propose(data)
if err != nil {
log.Panic(err)
}
}
HandleRaftReady 处理已经Ready的数据
该方法用来处理 rawNode 传递来的 Ready。主要分为 5 步:
- 判断是否有新的 Ready,没有就什么都不处理;
- 调用 SaveReadyState 将 Ready 中需要持久化的内容保存到 badger。如果 Ready 中存在 snapshot,则应用它;
- 然后调用 d.Send() 方法将 Ready 中的 Msg 发送出去;
- 应用 Ready 中的 CommittedEntries;
- 调用 d.RaftGroup.Advance() 推进 RawNode;
func (d *peerMsgHandler) HandleRaftReady() {
if d.stopped {
return
}
if !d.RaftGroup.HasReady() {
return
}
ready := d.RaftGroup.Ready()
_, err := d.peerStorage.SaveReadyState(&ready)
if err != nil {
log.Panic(err)
}
d.Send(d.ctx.trans, ready.Messages)
if len(ready.CommittedEntries) > 0 {
kvWB := &engine_util.WriteBatch{}
for _, ent := range ready.CommittedEntries {
kvWB = d.processCommittedEntry(&ent, kvWB)
if d.stopped {
return
}
}
lastEntry := ready.CommittedEntries[len(ready.CommittedEntries)-1]
d.peerStorage.applyState.AppliedIndex = lastEntry.Index
if err := kvWB.SetMeta(meta.ApplyStateKey(d.regionId), d.peerStorage.applyState); err != nil {
log.Panic(err)
}
kvWB.MustWriteToDB(d.peerStorage.Engines.Kv)
}
d.RaftGroup.Advance(ready)
}
SaveReadyState - 持久化
PeerStorage.go顾名思义需要负责该 peer 的存储。TinyKV 这里提供了两个 badger 实例,分别是 raftDB 和 kvDB,每个实例负责存储不同的内容:
raftDB 存储:
- Ready 中需要 stable 的 entries。
- RaftLocalState
kvDB 存储:
- RaftApplyState
- RegionLocalState
SaveReadyState方法用来持久化 Ready 中的数据。
- 通过 raft.isEmptySnap() 方法判断是否存在 Snapshot,如果有,则调用 ApplySnapshot() 方法应用;
- 调用 Append() 将需要持久化的 entries 保存到 raftDB;
- 保存 ready 中的 HardState 到 ps.raftState.HardState,注意先使用 raft.isEmptyHardState() 进行判空;
- 持久化 RaftLocalState 到 raftDB;
- 通过 raftWB.WriteToDB 和 kvWB.WriteToDB 进行底层写入。
func (ps *PeerStorage) SaveReadyState(ready *raft.Ready) (*ApplySnapResult, error) {
raftWB := &engine_util.WriteBatch{}
var result *ApplySnapResult
var err error
if err = ps.Append(ready.Entries, raftWB); err != nil {
log.Panic(err)
}
if !raft.IsEmptyHardState(ready.HardState) {
*ps.raftState.HardState = ready.HardState
}
if err = raftWB.SetMeta(meta.RaftStateKey(ps.region.Id), ps.raftState); err != nil {
log.Panic(err)
}
raftWB.MustWriteToDB(ps.Engines.Raft)
return result, nil
}
Append - 持久化日志
该方法供 SaveReadyState() 调用,负责将 Ready 中的 entries 持久化到 raftDB 中去,然后更新 RaftLoaclState 的状态。同时,如果底层存储有冲突条目,则将其删除。
func (ps *PeerStorage) Append(entries []eraftpb.Entry, raftWB *engine_util.WriteBatch) error {
if len(entries) == 0 {
return nil
}
for _, ent := range entries {
if err := raftWB.SetMeta(meta.RaftLogKey(ps.region.Id, ent.Index), &ent); err != nil {
log.Panic(err)
}
}
currLastTerm, currLastIndex := entries[len(entries)-1].Term, entries[len(entries)-1].Index
prevLastIndex, _ := ps.LastIndex()
for index := currLastIndex + 1; index <= prevLastIndex; index++ {
raftWB.DeleteMeta(meta.RaftLogKey(ps.region.Id, index))
}
ps.raftState.LastTerm, ps.raftState.LastIndex = currLastTerm, currLastIndex
return nil
}
结构体与一些流程介绍
相信在上面的介绍中,partB想让我们做什么读者已经清楚了。下面介绍一些结构体
RaftStore 会在节点启动的时候被创建,它负责维护在该节点上所有的 region 和对应的 peer。RaftStore 使用 storeMeta 维护该节点所有的元数据。
type storeMeta struct {
sync.RWMutex
regionRanges *btree.BTree
regions map[uint64]*metapb.Region
pendingVotes []*rspb.RaftMessage
}
- sync.RWMutex ,因为一个 RaftStore 上面的多个 region 可以同时接收请求,所以为了防止它们同时修改 storeMeta 元数据,这里会提供一个锁。
- regionRanges,用于快速定位某一个 key 在哪个 region 中。
- regions,region id 映射 region 结构体。
- pendingVotes,自己不用管,已经写好了。
RaftStore 被启动后,其首先会加载 peers,然后将 peers 注册进 router。加载 peer 的时候如果底层存储着之前 peer 信息,那么根据存储的信息加载,否则就新建。之后会启动一系列的 worker。RaftStore 的主要工作你可以认为就是接收来自其他节点的 msg,然后根据 msg 里面的 region id 将其路由到指定 region 的 peer 上。同时 RaftStore 也会将 peer 获取需要发送给其他节点的信息,发到其他的 RaftStore 上。
可以看到run函数显示将Msg读出来然后调用HandleMsg,如果是raftcmd,最终会调用到我们写的proposeRaftCommand中。将Msg全部转发下去之后,就调用HandleRaftReady去处理Ready的数据了。
func (rw *raftWorker) run(closeCh <-chan struct{}, wg *sync.WaitGroup) {
defer wg.Done()
var msgs []message.Msg
for {
msgs = msgs[:0]
select {
case <-closeCh:
return
case msg := <-rw.raftCh:
msgs = append(msgs, msg)
}
pending := len(rw.raftCh)
for i := 0; i < pending; i++ {
msgs = append(msgs, <-rw.raftCh)
}
peerStateMap := make(map[uint64]*peerState)
for _, msg := range msgs {
peerState := rw.getPeerState(peerStateMap, msg.RegionID)
if peerState == nil {
continue
}
newPeerMsgHandler(peerState.peer, rw.ctx).HandleMsg(msg)
}
for _, peerState := range peerStateMap {
newPeerMsgHandler(peerState.peer, rw.ctx).HandleRaftReady()
}
}
}
HandleMsg(msg message.Msg) 负责分类处理各种 msg。
- MsgTypeRaftMessage,来自外部接收的 msg,在接收 msg 前会进行一系列的检查,最后通过 RawNode 的 Step() 方法直接输入,不需要回复 proposal。
- MsgTypeRaftCmd,通常都是从 client 或自身发起的请求,比如 Admin 管理命令,read/write 等请求,需要回复 proposal。
- MsgTypeTick,驱动 RawNode 的 tick 用。
- MsgTypeSplitRegion,触发 region split,在 project 3B split 中会用到。
- MsgTypeRegionApproximateSize,修改自己的 ApproximateSize 属性,不用管。
- MsgTypeGcSnap,清理已经安装完的 snapshot。
- MsgTypeStart,启动 peer,新建的 peer 的时候需要发送这个请求启动 peer,在 Project3B split 中会遇到。
func (d *peerMsgHandler) HandleMsg(msg message.Msg) {
switch msg.Type {
case message.MsgTypeRaftMessage:
raftMsg := msg.Data.(*rspb.RaftMessage)
if err := d.onRaftMsg(raftMsg); err != nil {
log.Errorf("%s handle raft message error %v", d.Tag, err)
}
case message.MsgTypeRaftCmd:
raftCMD := msg.Data.(*message.MsgRaftCmd)
d.proposeRaftCommand(raftCMD.Request, raftCMD.Callback)
case message.MsgTypeTick:
d.onTick()
case message.MsgTypeSplitRegion:
split := msg.Data.(*message.MsgSplitRegion)
log.Infof("%s on split with %v", d.Tag, split.SplitKey)
d.onPrepareSplitRegion(split.RegionEpoch, split.SplitKey, split.Callback)
case message.MsgTypeRegionApproximateSize:
d.onApproximateRegionSize(msg.Data.(uint64))
case message.MsgTypeGcSnap:
gcSnap := msg.Data.(*message.MsgGCSnap)
d.onGCSnap(gcSnap.Snaps)
case message.MsgTypeStart:
d.startTicker()
}
}
make project2b 看看~
pass
rm -rf /tmp/*test-raftstore*
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestBasic2B|| true
=== RUN TestBasic2B
--- PASS: TestBasic2B (25.71s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 25.765s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestConcurrent2B|| true
=== RUN TestConcurrent2B
--- PASS: TestConcurrent2B (35.32s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 35.354s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestUnreliable2B|| true
=== RUN TestUnreliable2B
--- PASS: TestUnreliable2B (33.55s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 33.616s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestOnePartition2B|| true
=== RUN TestOnePartition2B
--- PASS: TestOnePartition2B (3.59s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 3.639s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestManyPartitionsOneClient2B|| true
=== RUN TestManyPartitionsOneClient2B
--- PASS: TestManyPartitionsOneClient2B (24.82s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 24.897s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestManyPartitionsManyClients2B|| true
=== RUN TestManyPartitionsManyClients2B
--- PASS: TestManyPartitionsManyClients2B (25.36s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 25.431s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestPersistOneClient2B|| true
=== RUN TestPersistOneClient2B
--- PASS: TestPersistOneClient2B (29.36s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 29.405s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestPersistConcurrent2B|| true
=== RUN TestPersistConcurrent2B
--- PASS: TestPersistConcurrent2B (44.34s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 44.423s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestPersistConcurrentUnreliable2B|| true
=== RUN TestPersistConcurrentUnreliable2B
--- PASS: TestPersistConcurrentUnreliable2B (44.30s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 44.363s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestPersistPartition2B|| true
=== RUN TestPersistPartition2B
--- PASS: TestPersistPartition2B (35.76s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 35.828s
GO111MODULE=on go test -v --count=1 --parallel=1 -p=1 ./kv/test_raftstore -run ^TestPersistPartitionUnreliable2B|| true
=== RUN TestPersistPartitionUnreliable2B
--- PASS: TestPersistPartitionUnreliable2B (34.59s)
PASS
ok github.com/pingcap-incubator/tinykv/kv/test_raftstore 34.673s
rm -rf /tmp/*test-raftstore*
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)