安装NVIDIA驱动准备工作
下载NVIDIA地址:https://www.nvidia.cn/Download/index.aspx?lang=cn
查看是否安装好驱动命令:
nvidia-smi
查看NAVIDIA的型号:
lspci |grep -i nvidia
查看NVIDIA驱动版本:
sudo dpkg --list | grep nvidia-*
检查适合系统的NAVIDIA版本:
nvidia-detector
:/usr/bin/nvidia-smi: 没有那个文件或目录
完全卸载NAVIDIA驱动
如果想卸载NAVIDIA驱动,使用附加驱动的方式只能切换驱动,但卸载不了驱动,只能通过命令的方式卸载:
sudo apt-get --purge remove nvidia*
sudo apt-get --purge remove "*nvidia*"
sudo apt-get --purge remove "*cublas*"
sudo apt-get --purge remove "cuda*"
sudo apt-get purge nvidia*
sudo update-initramfs -u
安装依赖:
sudo apt-get install gcc g++ make
禁用自带的nouveau驱动:
sudo gedit /etc/modprobe.d/blacklist-nouveau.conf
在打开的文件末尾加入:
blacklist nouveau
options nouveau modeset=0
然后保存关闭文本
再更新一下:
sudo update-initramfs -u
如果更新失败 fault的话,在上一步打开的文本中写入并保存(一般都会成功的!):
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
重启(必须)
reboot
重启成功后打开终端输入:
lsmod | grep nouveau
没有输出任何东西,说明nouveau禁用成功
配置国内ubuntu源
编辑/etc/apt/sources.list文件, 在文件最前面添加以下条目(操作前做好相应备份)
cd /etc/apt
sudo cp sources.list sources.list.bak
sudo vim sources.list
#增加阿里云,在source.list文件开头增加如下内容
deb http:
deb-src http:
deb http:
deb-src http:
deb http:
deb-src http:
deb http:
deb-src http:
deb http:
deb-src http:
#保存并更新
sudo apt update
sudo apt upgrade
安装多版本gcc并配置默认版本
安装 gcc-9、gcc-10并在系统中并存:
1、安装gcc-8、gcc-9、gcc-10
sudo apt install gcc-8 g++-8 gcc-9 g++-9 gcc-10 g++-10
2、以下命令为每个版本配置替代版本,并将优先级与之关联。默认版本是优先级最高的版本,在本例中为gcc-10。
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 100 --slave /usr/bin/g++ g++ /usr/bin/g++-10 --slave /usr/bin/gcov gcov /usr/bin/gcov-10
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 90 --slave /usr/bin/g++ g++ /usr/bin/g++-9 --slave /usr/bin/gcov gcov /usr/bin/gcov-9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 80 --slave /usr/bin/g++ g++ /usr/bin/g++-8 --slave /usr/bin/gcov gcov /usr/bin/gcov-8
3、切换gcc版本
sudo update-alternatives --config gcc
选中下面编号就可以跟换gcc版本
4、分别查看内核、gcc、glibc版本
uname -a
gcc --version
ldd --version
安装图形界面
首先需要安装lightdm,主要是用来关闭启动图形界面用,主要管理登录界面,ubuntu20.04需要自行安装,然后选择lightdm即可
sudo apt-get install lightdm
安装NVIDIA过程
同时按键Ctrl、Alt和F2 键,在这个界面进入root权限
如要回到图形化界面输入
sudo telinit 5
输入你的用户名和密码登录。
进入root权限
sudo -s #进入root权限
init 3 #进入了root权限后,进入3界面中进行安装
如不能进入root权限,就会出现报错:下面报错经历中第一个内容
找到NVIDIA-Linux-x86_64-295.53.run所在的文件夹
sudo chmod 777 NVIDIAxxxx.run
sudo ./NVIDIA-Linux.......run –no-opengl-files
–no-opengl-files: 只安装驱动文件,不安装OpenGL文件。这个参数最重要,不加很有可能出现循环登录,也就是loop login。
安装过程中,提示的问题该怎么选。
1:Would you like to register the kernel module souces with DKMS? This will allow DKMS to automatically build a new module, if you install a different kernel later? 选择 No 继续。

2:Install nvidia’s 32-bit compatibility libraries? No
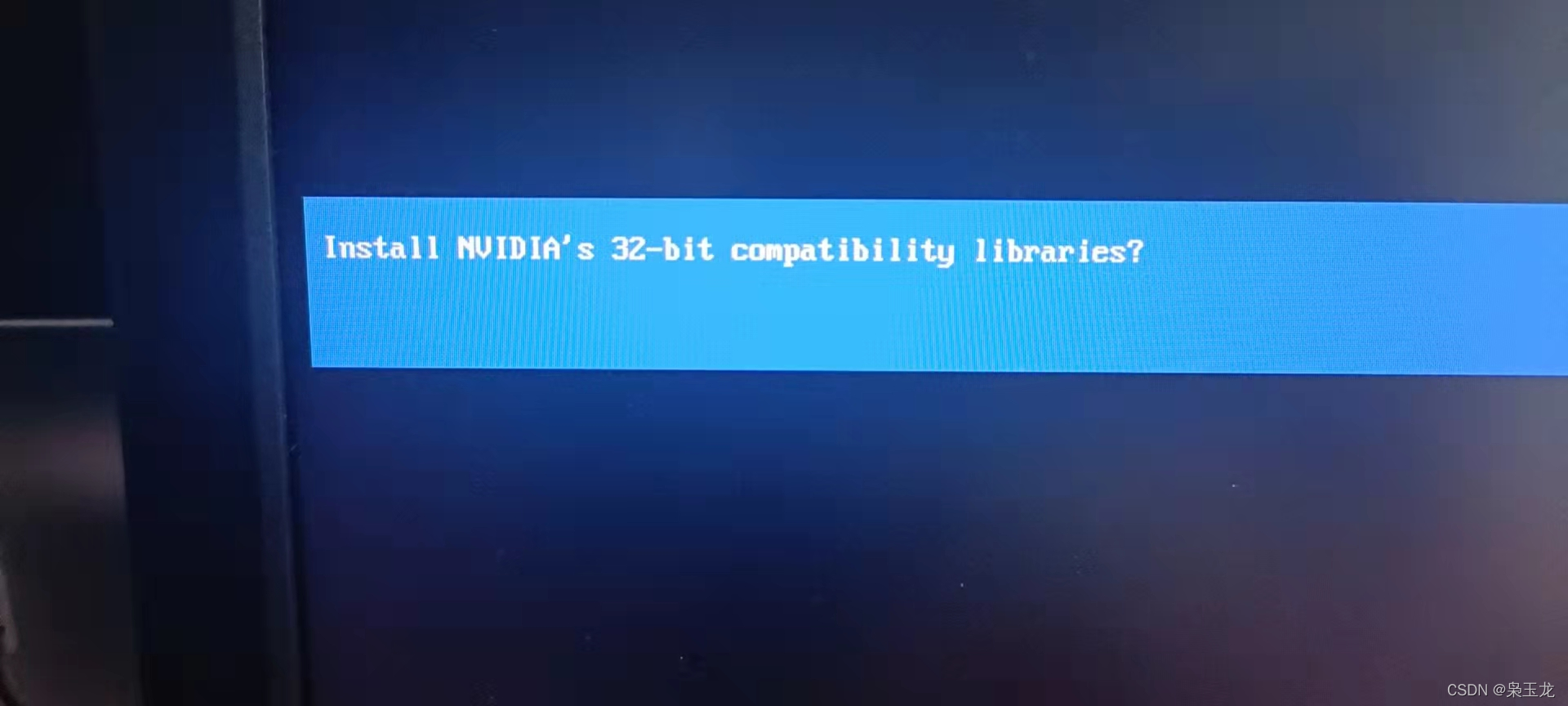 这个选择NO,如果选择yes会出现安装报错,下面报错经历第2个
这个选择NO,如果选择yes会出现安装报错,下面报错经历第2个
3:Would you like to run the nvidia-xconfigutility to automatically update your x configuration so that the NVIDIA x driver will be used when you restart x? Any pre-existing x confile will be backed up. 选择 Yes 继续

然后,进入图形环境。
打开终端输入
sudo init 5
sudo reroot #进行重启
nvidia-smi #查看是否安装成功
切换首选显卡,附加配置
编辑 AMD 显卡的配置文件
编辑 amdgpu 的X11配置文件. 文件路径 /usr/share/X11/sorg.conf.d/
sudo gediti /usr/share/X11/xorg.conf.d/10-amdgpu.conf
修改内容如下:
Section "OutputClass"
Identifier "AMDgpu"
MatchDriver "amdgpu"
Driver "amdgpu"
Option "PrimaryGPU" "no"
EndSection
编辑 Nvidia 的配置文件
修改Nvidia显卡配置
sudo gedit /usr/share/X11/xorg.conf.d/10-nvidia.conf
内容如下:
Section "OutputClass"
Identifier "nvidia"
MatchDriver "nvidia-drm"
Driver "nvidia"
Option "AllowEmptyInitialConfiguration"
Option "PrimaryGPU" "yes"
ModulePath "/usr/lib/x86_64-linux-gnu/nvidia/xorg"
EndSection
安装cuda
下载cuda:https://developer.nvidia.com/cuda-toolkit-archive
安装11.40命令:
wget https:
如果程序没有创建文件夹在请在:sudo mkdir /usr/local/cuda
sudo sh cuda_11.4.0_470.42.01_linux.run
--tmpdir=
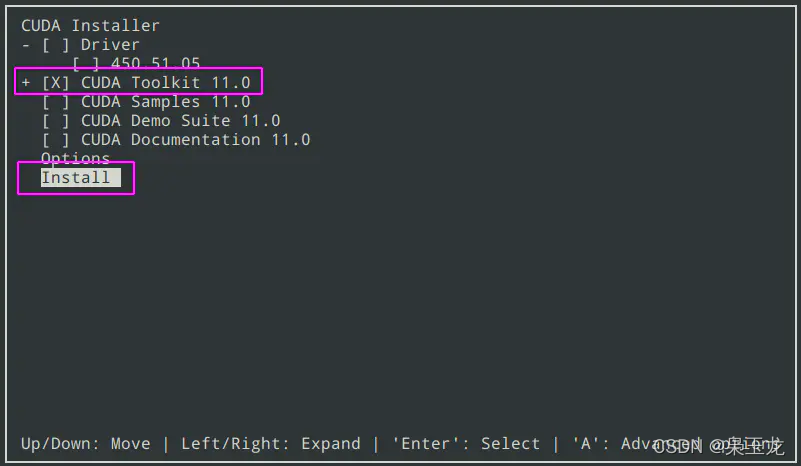
打x的是选中,没有x的是没有选中,要把没用的程序用回车键去掉
 如下已经完成安装
如下已经完成安装
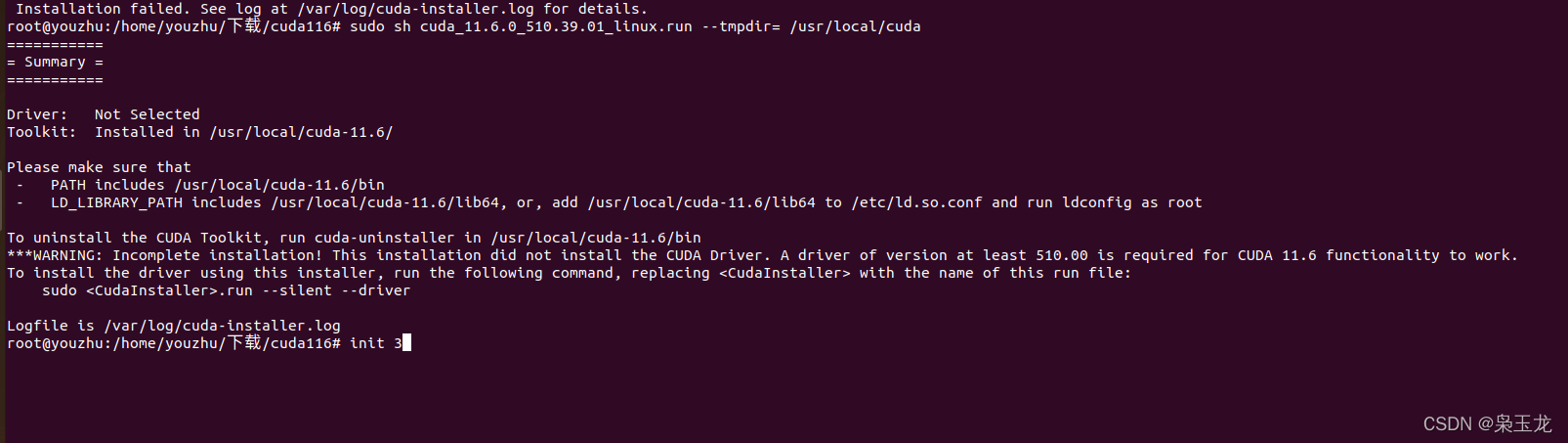
然后配置环境:
sudo gedit ~/.bashrc 或 sudo gedit ~/.bashrc
打开后在最后面添加如下代码(关于这里环境添加的路径写法问题,并不止这一种,网上可以搜得多种,此处我也只是照搬其中一种写法):
# <<< conda initialize <<<
export CUDA_HOME=/usr/local/cuda-11.6
export PATH=$PATH:/usr/local/cuda-11.6/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.6/lib64
然后更新环境:
source ~/.bashrc
这里的cuda链接cuda10.1,方法均是参考其它博客,我目前没有发现什么错误之处,再可查看cuda:
nvcc --version或者nvcc -V
然后测试cuda:
cd /usr/local/cuda-10.1/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
安装cudnn
安装cudnn:https://developer.nvidia.cn/rdp/cudnn-archive
下载完成后按照以下顺序安装
安装:
sudo dpkg -i libcudnn8_8.2.2.26-1+cuda11.4_amd64.deb
sudo dpkg -i libcudnn8-dev_8.2.2.26-1+cuda11.4_amd64.deb
sudo dpkg -i libcudnn8-samples_8.2.2.26-1+cuda11.4_amd64.deb
测试安装效果:
#复制cuDNN samples到home目录下
cp -r /usr/src/cudnn_samples_v8 /$HOME
#进入home目录
cd $HOME/cudnn_samples_v8/mnistCUDNN/
#编译mnistCUDNN
sudo make clean
sudo make
#运行mnistCUDNN
sudo ./mnistCUDNN
显示test passed说明安装成功。
如果测试遇到问题参考下面方法
编译mnistCUDNN时出错:fatal error: FreeImage.h: No such file or directory
- 执行“sudo make”时候可能会报以下编译错误 fatal error: FreeImage.h
mnistCUDNN sudo make
CUDA_VERSION is 11010
Linking agains cublasLt = true
CUDA VERSION: 11010
TARGET ARCH: x86_64
HOST_ARCH: x86_64
TARGET OS: linux
SMS: 35 50 53 60 61 62 70 72 75 80 86
test.c:1:10: fatal error: FreeImage.h: No such file or directory
1 | #include "FreeImage.h"
| ^~~~~~~~~~~~~
compilation terminated.
- 执行
sudo apt-get install libfreeimage3 libfreeimage-dev
- 重新编译后,运行
./mnistCUDNN
错误历程:
1:没有进入root权限会报下面错误,解决就是sudo -s进入root权限

2:Install nvidia’s 32-bit compatibility libraries? 选择yes会出现下面报错,解决选择NO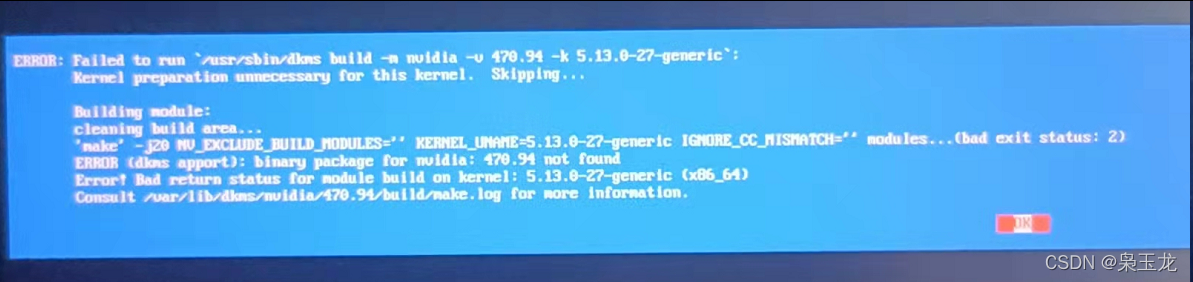
查看进程:用这个命令查看一下apt-get的相关进程:
ps -e | grep apt
sudo kill 95573 #后面数字可以更改想要杀死的进程
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)