在之前的教程中,我们讨论过NumPy 数组 ,我们看到了它如何使读取、解析和对数字数据执行操作的过程变得轻而易举。在本教程中,我们将讨论 NumPy loadtxt 方法,该方法用于解析文本文件中的数据并将其存储在 n 维 NumPy 数组中。
然后我们可以对其执行 NumPy 数组上可能的各种操作。
np.loadtxt 通过指定选项(例如结果数组的数据类型、如何通过分隔符区分一个数据条目与其他数据条目、跳过/包含特定行等),为我们从文件读取数据的方式提供了很大的灵活性。我们将在下面的教程中介绍每种方法。
指定文件路径 让我们看看如何指定要从中读取数据的文件的路径。
我们将使用一个示例文本文件作为代码示例,其中列出了 100 个人的体重(以千克为单位)和身高(以厘米为单位),每个人排成一行。
我将使用此文件中的各种变体来解释 loadtxt 函数的不同功能。
让我们从文本文件中数据的最简单表示开始。我们的文本文件中有 100 行(或行)数据,每行数据包含两个以空格分隔的浮点数。
每行的第一个数字代表体重,第二个数字代表个人的身高。
从文件中我们可以看到以下几点:
110.90 146.03
该文件存储为`体重_身高_1.txt `.
import numpy as np
data = np.loadtxt("./weight_height_1.txt") 这里我们假设该文件存储在与我们的 Python 代码运行位置相同的位置(“./”代表当前目录)。如果不是这种情况,我们需要指定文件的完整路径(例如:“C://Users/John/Desktop/weight_height_1.txt”)
我们还需要确保文件中的每一行具有相同数量的值。
文件的扩展名可以是 .txt 以外的任何内容,只要文件包含文本,我们还可以传递生成器而不是文件路径(稍后会详细介绍)
该函数返回文本中找到的值的 n 维 NumPy 数组。
这里,我们的文本有 100 行,每行有两个浮点值,因此返回的对象数据将是形状为 (100, 2)、浮点数据类型的 NumPy 数组。
您可以通过检查返回数据的“shape”和“dtype”属性来验证这一点:
print("shape of data:",data.shape)
print("datatype of data:",data.dtype) Output:
指定分隔符 分隔符是分隔行上各个值的字符或字符串。
例如,在我们之前的文件中,我们用空格分隔值,因此在这种情况下,分隔符是空格字符(“”)。
但是,其他一些文件可能具有不同的分隔符;例如,CSV 文件 一般使用逗号(“,”)作为分隔符。另一个文件可能有分号作为分隔符。
因此,我们需要数据加载器足够灵活,能够识别每行中的此类分隔符并从中提取正确的值。
这可以通过将分隔符作为参数传递给 np.loadtxt 函数来实现。
让我们考虑另一个文件‘体重_身高_2.txt ’,它的数据内容与前一个相同,但这次每行中的值都用逗号分隔:
110.90, 146.03
我们将以与以前相同的方式调用 np.loadtxt 函数,只是现在我们传递一个附加参数 - “分隔符”:
import numpy as np
data = np.loadtxt("./weight_height_2.txt", delimiter = ",") 该函数将返回与之前相同的数组。
在上一节中,我们没有传递分隔符参数值,因为 np.loadtxt() 期望空格“”作为默认分隔符。
如果每行上的值由制表符分隔,在这种情况下,将使用转义字符“\t”指定分隔符。
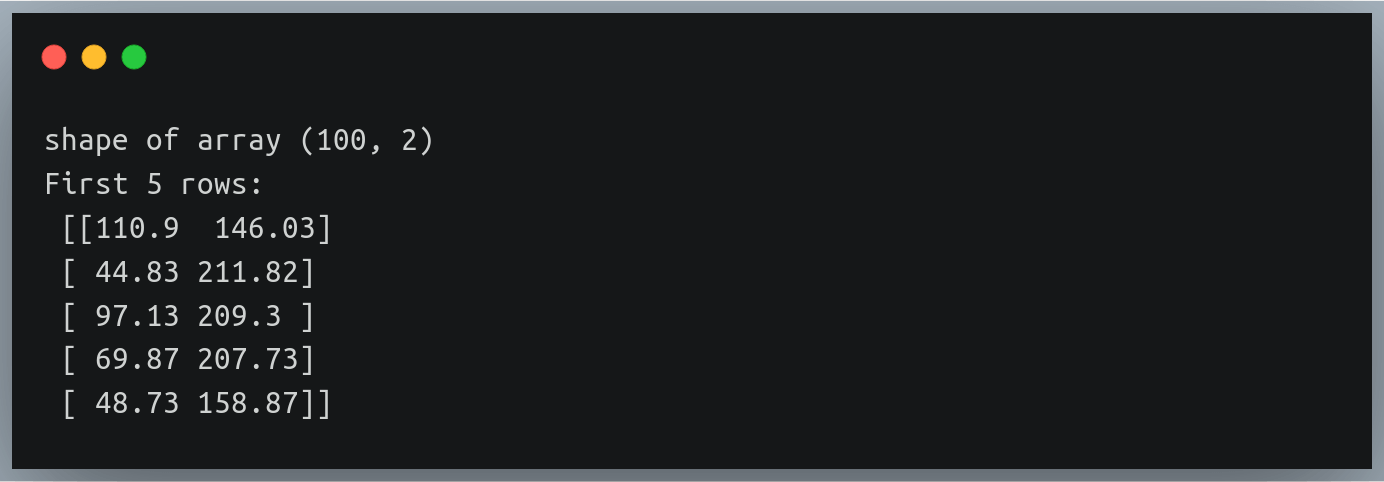
您可以通过检查数据数组的形状并打印前几行来再次验证结果:
print("shape of array", data.shape)
print("First 5 rows:\n", data[:5]) Output:
处理两个分隔符 现在可能存在一种情况,一个文件中有多个分隔符。
例如,假设每一行都包含第三个值,以 dd-mm-yyyy 格式表示个人的出生日期
110.90, 146.03, 1981 年 7 月 3 日
现在假设我们想要将日期、月份和年份作为三个不同的值提取到 NumPy 数组的三个不同列中。那么我们应该传递“,”作为分隔符还是应该传递“-”?
我们只能将一个值传递给 np.loadtxt 方法中的分隔符参数!
无需担心,总有解决方法。让我们使用第三个文件‘./体重_身高_3.txt ’对于这个例子
我们将首先使用一种简单的方法,该方法具有以下步骤:
读取文件
删除每一行中的一个分隔符并将其替换为一个通用分隔符(此处为逗号)
将行追加到运行列表中
将此字符串列表传递给 np.loadtxt 函数,而不是传递文件路径。
我们来写一下代码:
#reading each line from file and replacing "-" by ","
with open("./weight_height_3.txt") as f_input:
text = [l.replace("-", ",") for l in f_input]
#calling the loadtxt method with “,“ as delimiter
data = np.loadtxt(text, delimiter=",")
请注意,我们传递的是字符串列表作为输入,而不是文件路径。
调用该函数时,我们仍然传递带有值“,”的分隔符参数,因为我们已经用逗号替换了第二个分隔符“-”的所有实例。
返回的 NumPy 数组现在应该有五列。
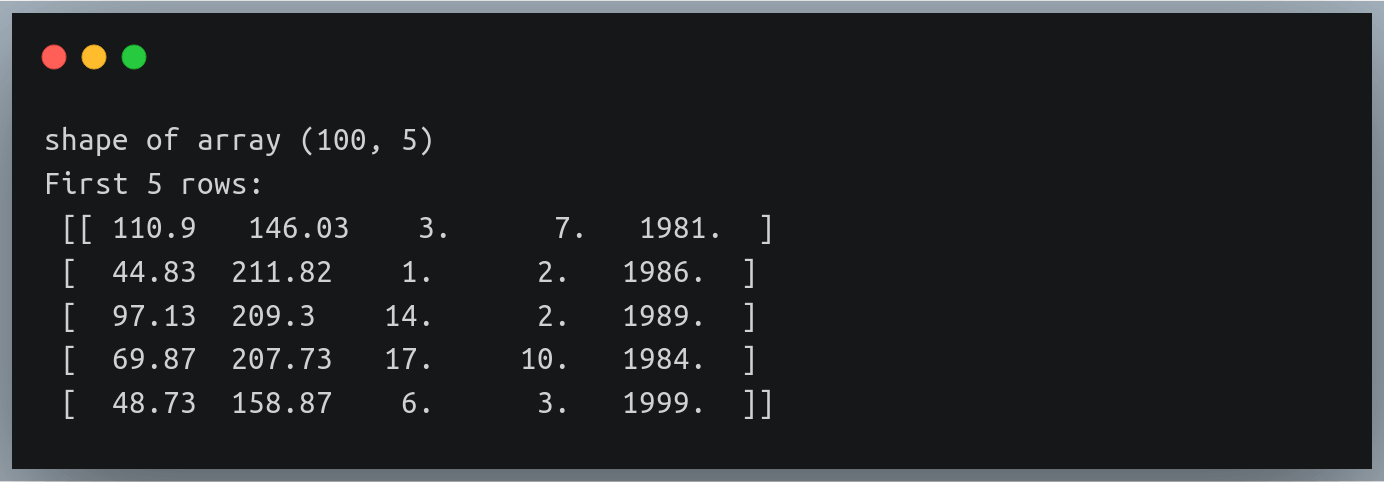
您可以通过打印形状和前五行再次验证结果:
print("Shape of data:", data.shape)
print("First five rows:\n",data[:5]) Output:
请注意我们如何在每行中添加三列,指示出生日期、月份和年份
另外,请注意新值都是浮点值;然而,日期、月份或年份作为整数更有意义!
多个分隔符的通用方法 在本节中,我们将了解使用多个分隔符的一般方法。
此外,我们还将学习如何使用生成器代替文件路径——这是比上一节中讨论的更有效的多个分隔符解决方案。
一次读取整个文件并将它们存储为字符串列表的问题是它不能很好地扩展。例如,如果有一个包含一百万行的文件,将它们一次性存储在列表中将消耗不必要的额外内存。
因此,我们将使用生成器来消除任何额外的分隔符。
因此,我们首先定义一个生成器函数,它将文件路径和分隔符列表作为参数。
def generate_lines(filePath, delimiters=[]):
with open(filePath) as f:
for line in f:
line = line.strip() #removes newline character from end
for d in delimiters:
line =line.replace(d, " ")
yield line 在这里,我们将逐行检查每行中的每个分隔符,并将它们替换为空格“”,这是 np.loadtxt 函数中的默认分隔符。
现在,我们将调用此生成器函数,并将返回的生成器对象传递给 np.loadtxt 方法来代替文件路径。
gen = generate_lines("./weight_height_3.txt", ["-",","])
data = np.loadtxt(gen) 请注意,我们不需要传递任何额外的分隔符参数,因为我们的生成器函数用空格替换了传递列表中分隔符的所有实例,这是默认分隔符。
我们可以扩展这个想法并根据需要指定尽可能多的分隔符。
指定数据类型 除非另有指定,否则 NumPy 包的 np.loadtxt 函数默认假定传递的文本文件中的值是浮点值。
因此,如果您传递一个包含数字以外的字符的文本文件,该函数将抛出一个错误,指出它需要浮点值。
我们可以通过使用 datatype 参数指定文本文件中值的数据类型来克服这个问题。
在前面的示例中,我们看到日期、月份和年份被解释为浮点值。然而,我们知道这些值永远不可能以十进制形式存在。
让我们看一个新文件‘./体重_身高_4.txt ’,其中只有 1 列用于个人的出生日期,格式为 dd-mm-yyyy:
1991年2月13日
因此,我们将使用“-”作为分隔符来调用 loadtxt 方法:
data = np.loadtxt("./weight_height_4.txt", delimiter="-")
print(data[:3])
print("datatype =",data.dtype) 如果我们查看上面几行代码的输出,我们会发现这三个值中的每一个都默认存储为浮点值,并且数组的数据类型是“float64”。
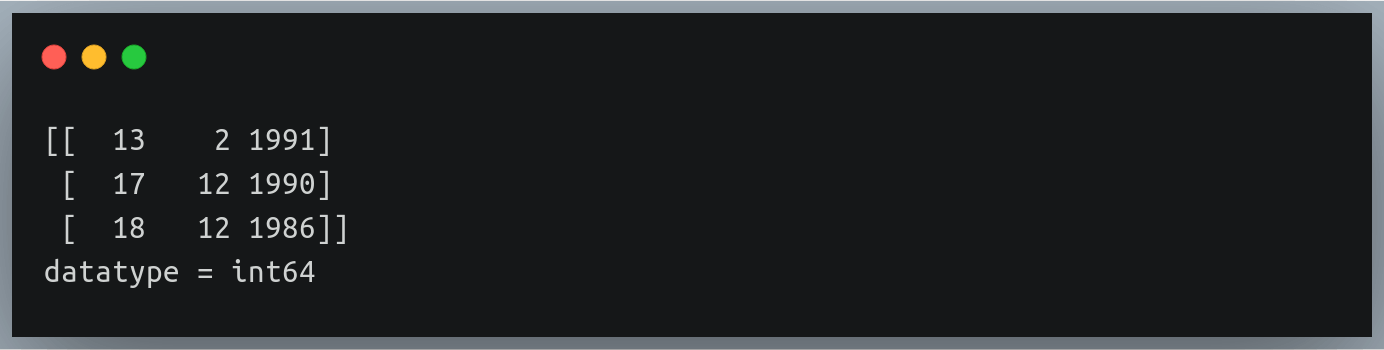
我们可以通过将值“int”传递给“dtype”参数来改变这种行为。这将要求函数将提取的值存储为整数,因此数组的数据类型也将为 int。
data = np.loadtxt("./weight_height_4.txt", delimiter="-", dtype="int")
print(data[:3])
print("datatype =",data.dtype) Output:
但是如果存在具有不同数据类型的列怎么办?
假设前两列具有浮点值,最后一列具有整数值。
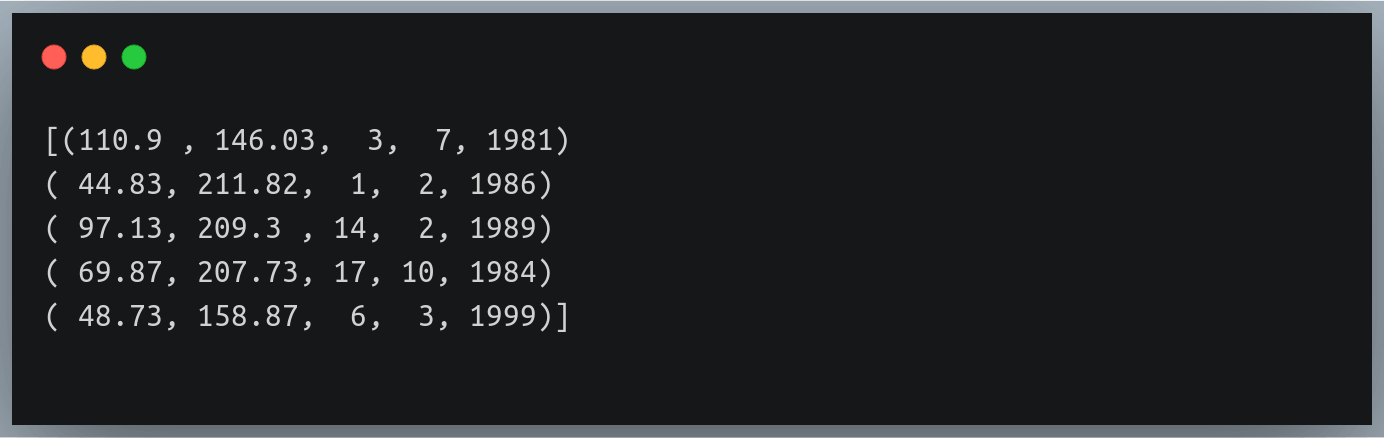
在这种情况下,我们可以将一个以逗号分隔的数据类型字符串传递给 dtype 参数,该字符串指定每列的数据类型(按其存在的顺序)。
但是,在这种情况下,该函数将返回值元组的 NumPy 数组,因为 NumPy 数组作为一个整体只能有 1 种数据类型。
让我们试试这个‘体重_身高_3.txt ' 文件,其中前两列(体重、高度)具有浮点值,最后三个值(日期、月份、年份)是整数:
Output:
在某些情况下(尤其是 CSV 文件),文本文件的第一行可能有“标题”,描述后续行中的每一列所代表的内容。从此类文本文件中读取数据时,我们可能想忽略第一行,因为我们不能(也不应该)将它们存储在 NumPy 数组中。
在这种情况下,我们可以使用“skiprows”参数并传递值 1,要求函数忽略文本文件的前 1 行。
让我们在 CSV 文件上尝试一下 – ‘体重身高.csv ’:
体重(公斤)、身高(厘米)
现在我们要忽略标题行,即文件的第一行:
data = np.loadtxt("./weight_height.csv", delimiter=",", skiprows=1)
print(data[:3]) Output:
同样,我们可以将任何正整数 n 传递给 Skiprows 参数,要求忽略文件中的前 n 行。
忽略第一列 有时,我们可能也想跳过第一列,因为我们对它不感兴趣。例如,如果我们的文本文件的第一列为“性别”,并且如果我们在提取数据时不需要包含该列的值,则我们需要一种方法来要求函数执行相同的操作。
我们在np.loadtxt函数中没有像skiprows这样的skipcols参数,使用它,我们可以表达这种需求。然而,np.loadtxt 还有另一个名为“usecols”的参数,我们在其中指定要保留的列的索引。
因此,如果我们想跳过第一列,我们可以简单地提供除第一列之外的所有列的索引(记住索引从零开始)
说得够多了,让我们开始工作吧!
让我们看一下新文件的内容‘体重_身高_5.txt ’,其中有一个我们想要忽略的额外性别列。
男, 110.90, 146.03
我们首先从第一行开始确定文件中的列数,然后传递一系列列索引(不包括第一行):
with open("./weight_height_5.txt") as f:
#determining number of columns from the first line of text
n_cols = len(f.readline().split(","))
data = np.loadtxt("./weight_height_5.txt", delimiter=",",usecols=np.arange(1, n_cols))
print("First five rows:\n",data[:5]) Here we are supplying a range of values beginning from 1 (second column) and extending up to n_cols (the last column)
我们可以通过仅传递我们想要保留的那些列的索引列表来推广 usecols 参数的使用。
加载前 n 行 正如我们可以使用skiprows参数跳过前n行一样,我们也可以选择仅加载前n行并跳过其余行。这可以使用 np.loadtxt 方法的 max_rows 参数来实现。
假设我们只想读取文本文件“weight_height_2.txt”中的前十行。我们将调用 np.loadtxt 方法以及 max_rows 参数并传递值 10。
data = np.loadtxt("./weight_height_2.txt", delimiter=",",max_rows = 10)
print("Shape of data:",data.shape) Output:
我们可以看到,返回的 NumPy 数组只有十行,这是文本文件的前十行。
如果我们将 max_rows 参数与 Skiprows 参数一起使用,则将跳过指定的行数,并提取接下来的 n 行,其中 n 是我们传递给 max_rows 的值。
加载特定行 如果我们希望 np.loadtxt 函数仅加载文本文件中的特定行,则没有参数支持此功能。
但是,我们可以通过定义一个接受行索引并返回这些索引处的行的生成器来实现这一点。然后,我们将此生成器对象传递给 np.loadtxt 方法。
我们首先定义生成器:
def generate_specific_rows(filePath, row_indices=[]):
with open(filePath) as f:
# using enumerate to track line no.
for i, line in enumerate(f):
#if line no. is in the row index list, then return that line
if i in row_indices:
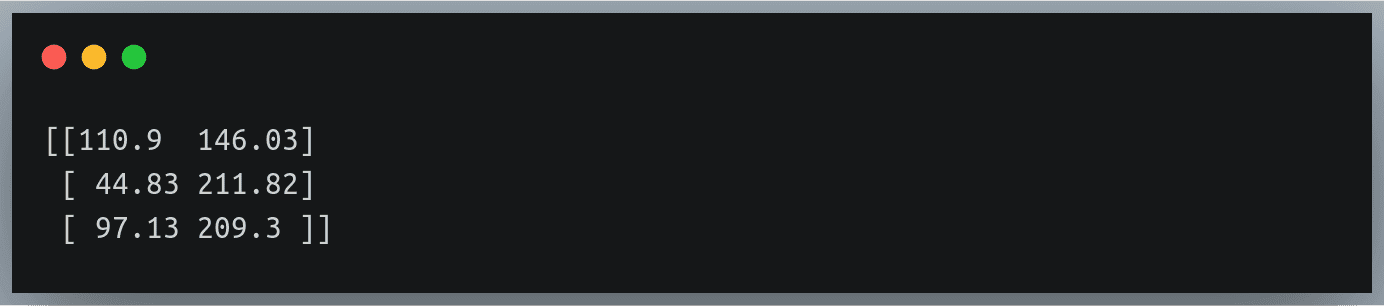
yield line 现在让我们使用 np.loadtxt 函数读取文件中的第 2、4 和 100 行‘体重_身高_2.txt ’
gen = generate_specific_rows("./weight_height_2.txt",row_indices = [1, 3, 99])
data = np.loadtxt(gen, delimiter=",")
print(data) 这应该返回一个具有三行两列的 NumPy 数组:
Output:
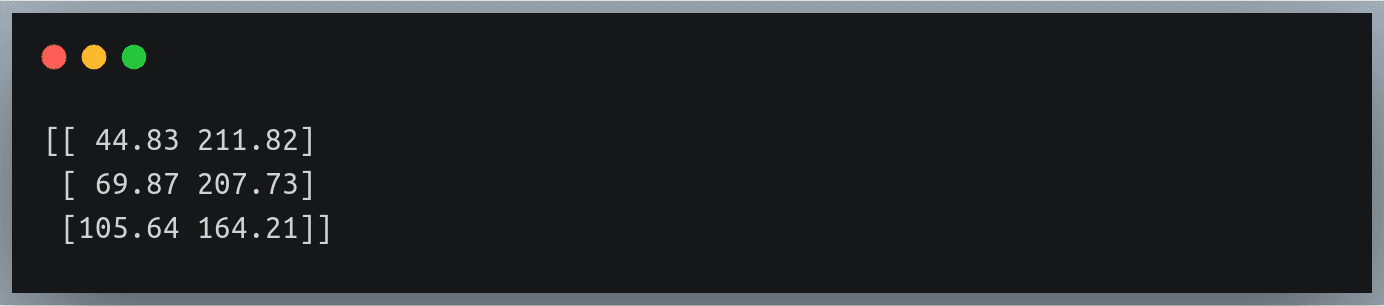
跳过最后一行 如果您想排除文本文件的最后一行,可以通过多种方式实现。您可以定义另一个生成器,逐行生成行并在最后一行之前停止,或者您可以使用更简单的方法 - 只需计算出文件中的行数,并将比该计数少的行数传递给 max_rows范围。
但是你如何计算出行数呢?
with open("./weight_height_2.txt") as f:
n = len(list(f))
print("n =", n) 现在 n 包含 ` 中存在的行数体重_身高_2.txt ` 文件,该值应为 100。
现在,我们将像以前一样使用 np.loadtxt 方法以及值为 n – 1 的 max_rows 参数来读取文本文件。
data = np.loadtxt("./weight_height_2.txt", delimiter=",",max_rows=n - 1)
print("data shape =",data.shape) Output:
正如我们所看到的,原始文本文件有 100 行,但是当我们从文件中读取数据时,它的形状是 (99, 2),因为它跳过了文件中的最后一行。
跳过特定列 假设您想在从文本文件加载数据时通过指定某些列的索引来忽略这些列。
虽然 np.loadtxt 方法提供了一个参数来指定要保留哪些列(usecols),但它没有提供相反的方法,即指定要跳过哪些列。但是,我们总能找到解决方法!
我们首先定义要忽略的列的索引,然后使用它们,我们将导出要保留的索引列表,因为这两个集合是互斥的。
然后,我们会将这个派生索引列表传递给 usecols 参数。
这是整个过程的伪代码:
查找文件 n_cols 中的列数(在前面的部分中进行了说明)
定义要忽略的索引列表
创建从 0 到 n_cols 的索引范围,并从此范围中消除步骤 2 的索引
将此新列表传递给 np.loadtxt 方法中的 usecols 参数
让我们创建一个包装函数 loadtext_without_columns 来实现上述所有步骤:
def loadtext_without_columns(filePath, skipcols=[], delimiter=","):
with open(filePath) as f:
n_cols = len(f.readline().split(delimiter))
#define a range from 0 to n_cols
usecols = np.arange(0, n_cols)
#remove the indices found in skipcols
usecols = set(usecols) - set(skipcols)
#sort the new indices in ascending order
usecols = sorted(usecols)
#load the file and retain indices found in usecols
data = np.loadtxt(filePath, delimiter = delimiter, usecols = usecols)
return data 为了测试我们的代码,我们将使用一个新文件`体重_身高_6.txt `,有五列 - 前两列表示宽度和高度,其余 3 列表示个人的出生日期、月份和年份。
所有值均由单个分隔符 - 逗号分隔:
110.90, 146.03, 1981年3月7日
假设我们对个人的身高和出生日期不感兴趣,因此我们想跳过位置 1 和 2 处的列。
让我们调用包装函数来指定我们的要求:
data = loadtext_without_columns("./weight_height_6.txt",skipcols = [1, 2], delimiter = ",")
# print first 5 rows
print(data[:5]) Output:
我们可以看到我们的包装函数只返回三列——重量、月份和年份。它确保我们指定的列已被跳过!
加载 3D 数组 到目前为止,我们一直以 2D NumPy 数组的形式读取文件的内容。这是 np.loadtxt 方法的默认行为,我们可以指定任何其他参数来将读取的数据解释为 3D 数组。
因此,解决此问题的最简单方法是将数据读取为 NumPy 数组并使用NumPy 重塑 方法将数据重塑为我们想要的任何形状、任何维度。
我们只需要小心,如果我们想将其解释为多维数组,我们应该确保它以适当的方式存储在文本文件中,并且在重塑数组后,我们会得到我们真正想要的东西。
让我们举一个示例文件 – ‘体重_身高_7.txt ’.
这是与“weight_height_2.txt”相同的文件。唯一的区别是该文件有 90 行,每个 30 行块代表个人所属的不同部分或类别。
因此,总共有 3 个部分(A、B 和 C)——每个部分有 30 个人,他们的体重和身高列在新行中。
部分名称在每个部分开头之前用注释表示(您可以在第 1、32 和 63 行进行检查)。
注释语句以“#”开头,np.loadtxt 在读取数据时会忽略这些行。我们还可以使用参数“comments”为注释行指定任何其他标识符。
现在,当您读取此文件并打印其形状时,它将显示 (90,2),因为这就是 np.loadtxt 读取数据的方式 - 它将多行数据排列成二维数组。
但我们知道每组 30 个人之间存在逻辑分离,我们希望形状为 (3, 30, 2) – 其中第一个维度表示部分,第二个维度表示该部分中的每个人部分,最后一个维度表示与每个人相关的值的数量(此处 2 表示体重和身高)。
使用 NumPy 重塑方法 所以我们希望我们的数据被表示为 3D 数组。
我们可以通过使用 NumPy 的 reshape 方法简单地重塑返回的数据来实现这一点。
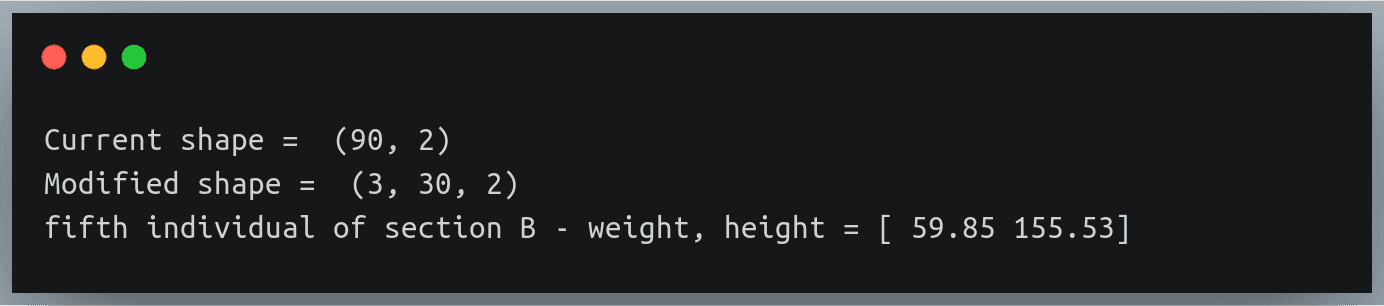
data = np.loadtxt("./weight_height_7.txt",delimiter=",")
print("Current shape = ",data.shape)
data = data.reshape(3,30,2)
print("Modified shape = ",data.shape)
print("fifth individual of section B - weight, height =",data[1,4,:]) Output:
请注意我们如何使用三个索引打印特定个人的详细信息
返回的结果属于B部分的第5个个体——这可以从文本中得到验证:#B部分 100.91, 155.55 72.93, 150.38 116.68, 137.15 86.51、172.15 59.85, 155.53 …
与替代方案的比较 虽然 numpy.loadtxt 是一个非常有用的从文本文件读取数据的实用程序,但它并不是唯一的!
有许多替代方案可以完成与 np.loadtxt 相同的任务;其中许多在很多方面都比 np.loadtxt 更好。让我们简单地看一下三个这样的替代函数。
numpy.genfromtxt
这是与 np.loadtxt 一起讨论最多和最常用的方法
两者之间没有重大区别;唯一突出的是 np.genfromtxt 平滑处理缺失值的能力。
事实上,NumPy 的文档将 np.loadtxt 描述为“当没有数据丢失时的等效函数(与 np.genfromtxt)。
因此,这两种方法几乎相似,只是 np.genfromtxt 可以对文本文件中的数据进行更复杂的处理。
numpy.fromfile
np.fromfile 通常在处理存储在二进制文件中的数据时使用,不带分隔符。
它可以读取纯文本文件,但这样做会遇到很多问题(继续尝试使用 np.fromfile 读取我们讨论的文件)
虽然它的执行时间比 np.loadtxt 更快,但在处理文本文件中结构良好的数据时,它通常不是首选。
此外,NumPy 的文档提到 np.loadtxt 是一种“比 np.fromfile 更灵活”的从文本文件加载数据的方式。
pandas.read_csv
pandas.read_csv 是数据科学家、机器学习工程师、数据分析师等从文本文件读取数据的最受欢迎的选择。
它提供了比 np.loadtxt 或 np.genfromtxt 更多的灵活性。
您不能像我们一样将生成器传递给 pandas.read_csv 。
然而,就执行速度而言,pandas.read_csv 比 np.loadtxt 更好
处理缺失值 正如我们在比较 np.loadtxt 与其他选项的部分中所讨论的,np.genfromtxt 默认情况下会处理缺失值。我们没有任何直接的方法来处理 np.loadtxt 中的缺失值
在这里,我们将了解使用 np.loadtxt 方法处理缺失值的间接(且稍微复杂)的方法。
转换器参数:
np.loadtxt 有一个转换器参数,用于指定文件中每一列所需的预处理(如果有)。
例如,如果文本文件以厘米为单位存储高度列,而我们希望将它们存储为英寸,则可以为高度列定义一个转换器。
Converters 参数接受一个字典,其中键是列索引,值是接受列值、“转换”它并返回修改后的值的方法。
我们如何使用转换器来处理缺失值?
我们需要首先决定默认数据类型,即用于填充实际值缺失位置的值。假设我们想用 0 填充缺失的身高和体重值,因此我们的 fill_value 将为 0。
接下来,我们可以为文件中的每一列定义一个转换器,它检查该列中是否有某个值或空字符串,如果是空字符串,它将用我们的 fill_value 填充它。
为此,我们必须找到文本文件中的列数,我们已经在前面的部分中讨论了如何实现这一点。
我们将使用该文件‘体重_身高_8.txt ”,与“weight_height_2.txt”相同,但有几个缺失值。
, 146.03
让我们编写代码,用 0 填充这些缺失值的位置。
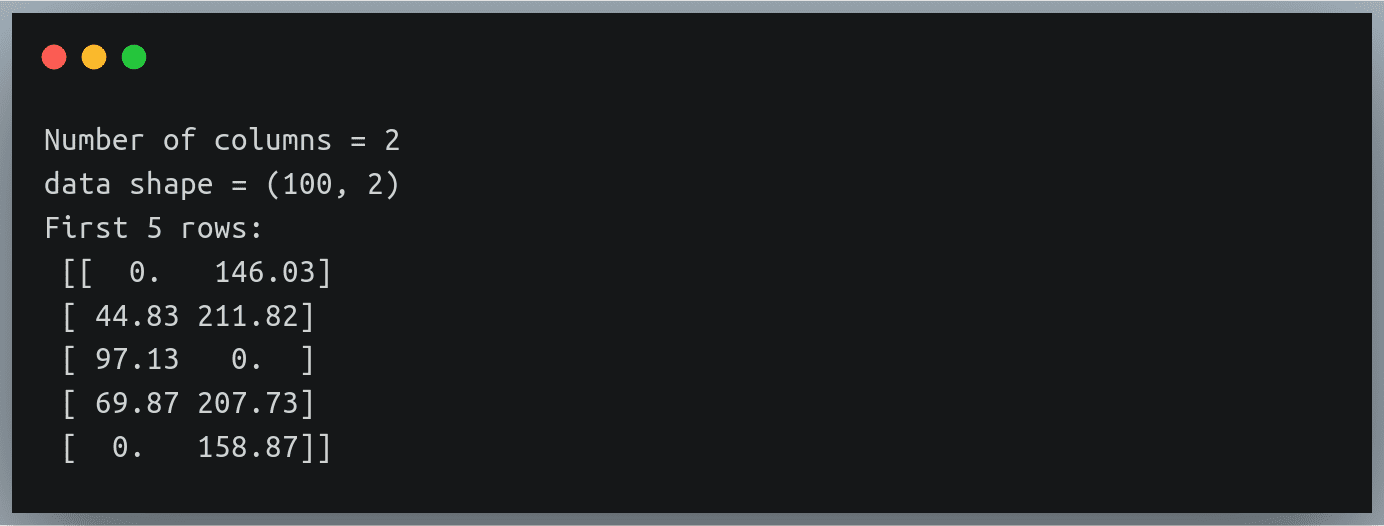
# finding number of columns in the file
with open("./weight_height_8.txt") as f:
n_cols = len(f.readline().split(","))
print("Number of columns", n_cols)
# defining converters for each of the column (using 'dictionary
# comprehension') to fill each missing value with fill_value
fill_value = 0
converters = {i: lambda s: float(s.strip() or fill_value) for i in range(2)}
data = np.loadtxt("./weight_height_8.txt", delimiter=",",converters = converters)
print("data shape =",data.shape)
print("First 5 rows:\n",data[:5]) Output:
缺失的身高和体重值已正确替换为 0。没什么神奇的!
结论 numpy.loadtxt 无疑是读取存储在文本文件中的结构良好的数据的最标准选择之一。它为我们提供了极大的灵活性,可以选择各种选项来指定我们想要读取数据的方式,无论是否不指定 - 请记住,总有一个解决方法!