论文地址:https://arxiv.org/abs/1704.02447
code:https://github.com/xingyizhou/pytorch-pose-hg-3d
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
Xingyi Zhou1,2, Qixing Huang2, Xiao Sun3, Xiangyang Xue1, Yichen Wei3
在野外进行3D人体姿态估计:一种弱监督方法
摘要
在本文中,我们研究了野外三维人体姿态估计的任务。 由于缺乏训练数据,此任务具有挑战性,因为现有数据集要么是具有2D姿势的野生图像,要么是具有3D姿势的实验室图像。
我们提出了一种弱监督转移学习方法,该方法在统一的深中性网络中使用混合的2D和3D标签,呈现两级级联结构。 我们的网络通过3D深度回归子网络增强了最先进的2D姿态估计子网络。 与之前的按顺序和分开训练两阶段方法不同,我们的训练是两个子网络端到端并充分利用2D姿态和深度估计子任务之间的相关性。 通过共享表示可以更好地学习深层特征。 在这样做时,受限制的实验室环境中的3D姿势标签被转移到野外图像中。 此外,我们引入了3D几何约束来规范3D姿态预测,这在没有地面实况深度标签的情况下是有效的。 我们的方法在2D和3D基准测试中实现了有竞争力的结果。
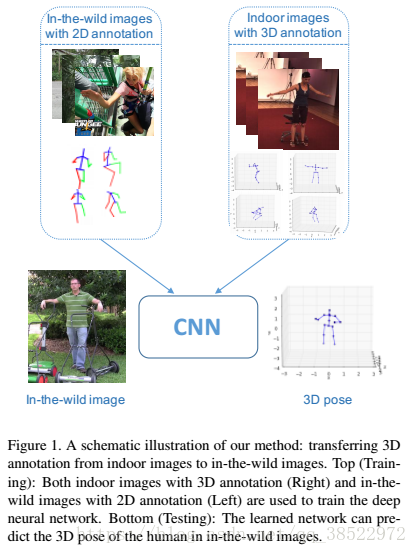
- 简介
人体姿势估计问题已在计算机视觉中得到了大量研究。 它在人机交互,虚拟现实和动作识别方面有许多重要的应用。 现有的研究工作分为两类:2D姿态估计和3D姿态估计。 由于大规模2D标注人体姿势的可用性和深度神经网络的出现,2D人体姿势估计问题最近取得了巨大的成功[17,29,11,4,7]。 最先进的技术能够在各种设置中实现准确的预测(例如,野外图像[2])。
相比之下,3D人体姿势估计的进步仍然有限。 部分原因是由于从单个图像恢复3D信息的模糊性,还有一部分原因是由于缺少大规模3D姿势标注数据集。 准确的说,还没有针对野外图像的全面的3D人体姿势数据集。 常用的3D数据集[12,24]由受控实验室环境中的mocap系统获取。 在这些数据集上训练的深度神经网络[13,33]并不能很好地推广到其他实例,例如在野外。
mocap系统解释了解:https://www.jianshu.com/p/5b35493c386f
https://zhuanlan.zhihu.com/p/37415840
在野外已经有很多关于3D人体姿势估计的工作。 它们通常按两个连续步骤进行[34,26,5,3,30,31]。 第一步估计2D关节位置[17,29,11]。 第二步从这些2D关节[21,32,1]恢复3D姿势。 这两个步骤的训练是分开进行的。 即,从野外的2D标注训练2D姿势预测,并且从现有的3D MoCap数据训练来自2D关节的3D姿势恢复。 这样的顺序流水线显然是次优的,因为在第二步中丢弃了包含用于3D姿势恢复的丰富提示的原始野外2D图像信息。
最近,Mehta等人。 [15]已经表明,2D到3D知识转移,即使用预训练的2D姿势网络来初始化3D姿势回归网络可以显着改善3D姿势估计性能。 这表明2D和3D姿势估计任务固有地纠缠在一起并且可以共享共同的表示
受这项工作的启发,我们认为反向知识边缘转移,即从室内图像的3D注释到野外图像,为野外3D姿态预测提供了有效的解决方案。 在这项工作中,我们引入了一个统一的框架,可以利用野外图像中的2D注释作为3D姿势估计任务的弱标签。 换句话说,我们考虑一个弱监督的转移学习问题,其中源域由受限室内环境中的完全注释图像组成并且目标域由野外的弱标记图像组成。
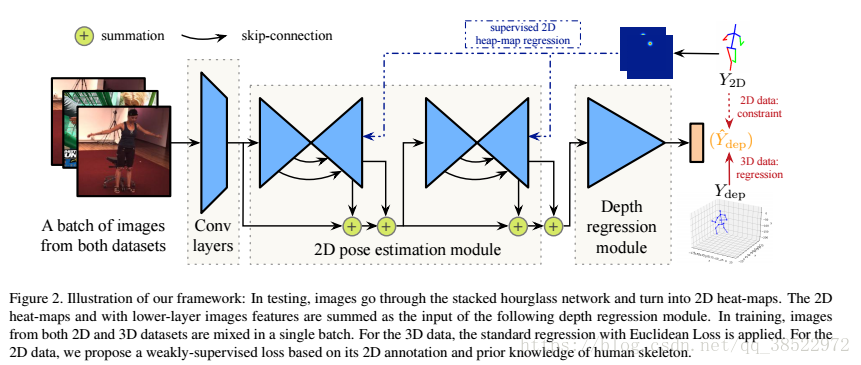
与之前的作品类似[34,26,5,3,30,31],我们的网络也包括2D模块和3D模块。 然而,我们的方法不是仅仅将2D模块的输出作为输入提供给3D模块,而是将3D模块与2D模块的中间层连接起来。 这允许我们共享2D和3D任务之间的共同表示。 该网络是同时具有2D和3D数据端到端的训练。 这使我们的工作与所有现有工作区别开来。
为了更好地规范弱监督3D姿态估计的学习,我们引入了用于训练3D模块的几何约束。 几何约束基于以下事实:人体骨骼中的相对骨骼长度保持近似固定。 当将来自室内环境中的标记图像的3D姿势信息适应于野外的未标记图像时,实验验证了该约束的有效性。
这项工作做出以下贡献:
我们首次提出了一种用于野外图像的端到端3D人体姿势估计框架。 它在几个基准测试中实现了最先进的性能。
我们从仅具有2D联合注释的图像中提出了用于3D姿态估计的3D几何约束。其具有低内存和计算成本。 它改善了估计姿势的几何有效性。
- 相关工作
人类姿势估计在过去已被大量研究[16,23],并且提供文献的完整概述超出了本文的范围。 在本节中,我们将重点放在以前关于3D人体姿态估计的工作上,这些工作与本文的背景最为相关。 我们还将讨论关于对训练神经网络施加弱/无监督约束的相关工作
3D人体姿势估计。 给定良好标记的数据(例如,人类骨骼的3D关节位置[12,24]),可以将3D人体姿势估计公式化为标准的监督学习问题。 一种流行的方法是训练神经网络直接回归关节位置[13]。 最近,人们已经将这种方法推广到不同的方向。 Zhou等人。 [33]建议明确执行预测中的骨长度约束,使用生成的前向运动层; Tekin 等人。 [25]在网络顶部嵌入了一个预训练的自动编码器。 与之相反,Pavlakos等人引入了一种3D方法,该方法回归了3D骨架的体积表示[19]。 尽管标准3D姿态估计基准数据集的性能提高,但由于自然图像与这些基准数据集所使用的特定捕获环境之间的区域差异,所得到的网络不会推广到野外图像。
解决三维人体姿势估计数据集与野外图像之间的域差异的标准方法是将任务分成两个单独的子任务[34,26,5,3,30]。第一个子任务估计2D关节位置。该子任务可以利用任何现有的2D人体姿势估计方法(例如,[17,29,11,4]),并且可以从野外图像的数据集中进行训练。第二个子任务回归这些2D关节的3D位置。由于此步骤的输入仅是一组2D位置,因此可以在任何基准数据集上训练3D姿态估计网络,然后在其他设置中进行调整。关于来自2D关节位置的3D姿态估计,[34]使用EM通过组合由2D热图引起的稀疏字典来计算3D骨架的算法; [30,19]使用3D姿势数据及其2D投影来训练没有原始图像的热图到3D姿势网络; Bogo等。 [3]优化线性3D人体模型[14]的姿势和形状项,以最佳地拟合其2D投影;陈等人。 [5]使用最近邻搜索将估计的2D姿势与3D姿势以及可以从大型3D姿势库产生类似2D投影的相机视图相匹配;最后是Tome等人。 [26]提出了预训练的概率3D姿势模型层,首先生成合理的3D人体模型从2D热图,然后通过改进这些热图结合3D姿势投影和图像功能。所有这些
然而,方法有一个共同的局限:3D姿势仅从2D关节估计,已知2D关节产生模糊结果。相比之下,我们的方法可以利用2D关节位置以及原始图像的中间特征代表。
3D人体姿态估计的另一种方法是从合成数据集中进行训练,这些数据集是通过使用已知的3D地面实况变形人体模板模型而生成的[6,22]。 这确实是一种可行的解决方案,但基本挑战是如何对3D环境进行建模,以使合成图像的分布与自然图像的分布相匹配。 事实证明,沿着这条线的最先进的方法在自然图像上的竞争力较弱。
还有其他利用混合2D和3D数据进行3D人体姿势估计的工作。 Mehta等。 [15]使用3D数据微调预训练的2D姿态估计网络。 Popa等人。 [20]将3D人体姿态估计视为具有不同数据的2D和深度回归的多任务学习。 我们与那些使用弱监督损失的工作不同&#x