点击上方“机器学习与生成对抗网络”,"星标置顶”
重磅干货,第一时间送达

来自 | 知乎 作者 | 赵丽丽 编辑 | 新机器视觉
在介绍视觉内容检索流程前,先来回顾下文本检索流程。
一、相似文本检索
相似文本检索可以分成构建词库、构建索引和检索三部分,如下图所示。
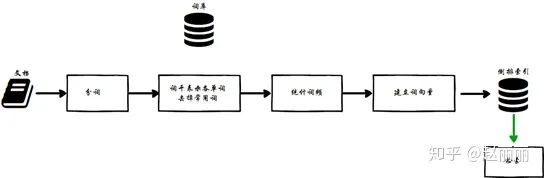
构建词库是离线操作,主要对目标数据集中的文本进行解析提取词干信息,建立当前数据集的词库,然后基于词库,对数据集中所有文档提取本文特征。构建词库在整个检索系统生命周期开始阶段实施,一般情况仅执行一次,是针对目标检索文本数据集进行的非频繁性操作。
构建索引和检索是在线操作。其中,构建索引是在检索服务启动时进行,负责将目标数据集的文本特征以某种方式组织到内存中,方便后续快速检索和距离计算。检索阶段查找目标库中与查询内容query相近的文本结果,该阶段提取query文档的文本特征,同目标库中的各文档的特征向量进行距离计算,对结果进行排序,返回距离最近特征向量对应的文档索引。
文本检索过程实际上可以理解为文本特征匹配的过程,以上过程文本使用词袋向量(Bag-of-Words,BoW)来表征文本内容。BoW是常用的一种文本特征表示,它通过统计单词在文档中出现的频次来表示一个文档,因其简单有效的优点得到了广泛应用。BoW特征提取过程包括以下几个步骤:
1) 将文档中的文本解析成单词。
2) 使用词干表示各单词,去掉常用词。
3) 统计当前文档中每个单词(词干)出现的频次。
4) 建立表示该文档的向量,向量的每次元素代表对应位置的单词出现的频次,向量长度等于词库内单词个数。在构建词向量时,通常会引入加权机制。常用的一种加权方式为采用tf-idf (term frequecy-inverse document frequency)。tf-idf的计算方式如下:
假设词库共有k个单词,当前文档doc用词向量  表示,其中
表示,其中  的计算方式为
的计算方式为  。其中,
。其中,  为词库中第i个单词在文档doc中出现的次数,
为词库中第i个单词在文档doc中出现的次数,  为文档doc包含的单词总数,
为文档doc包含的单词总数,  为单词i在整个目标文档库中出现的次数,N为目标库包含的文档总数。可以看出,文档d的词向量中的每个元素是由两项乘积构成,第一项
为单词i在整个目标文档库中出现的次数,N为目标库包含的文档总数。可以看出,文档d的词向量中的每个元素是由两项乘积构成,第一项  为词频,它会增加在当前文档中出现频次较高的单词的权重;第二项
为词频,它会增加在当前文档中出现频次较高的单词的权重;第二项  会降低在目标库中出现频次较高的单词的权重。
会降低在目标库中出现频次较高的单词的权重。
二、基于内容的图像检索流程
图像内容检索流程与文本检索流程类似,但二者信息表征方法不同。文本通过词频计算BoW来表征一段文本内容,而图像则使用视觉特征来表示。Google团队2003年[1]提出的视频内容检索方法借鉴文本检索流程,使用局部特征构建视觉词袋向量(Bag-of-Visual-Words,BoVW),也称BoF(Bag-of-Features),来表示图像。这里的视觉单词是指量化后的视觉特征。Video-Google[1]中检索系统也分为构建词库、构建索引和检索三部分。下图是视觉词库构建流程:
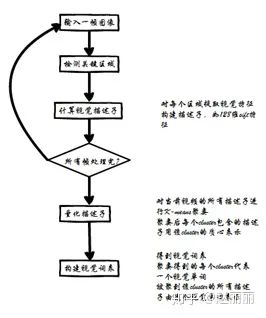
对图像提取若干个局部特征描述子,如sift,对这些描述子进行量化。量化器通常通过聚类得到:对特征描述子集合进行k-means聚类,聚类后得到的k个质心即为视觉单词。描述子desc的量化结果q(desc)为与desc最相近的质心的索引。所有质心构成了视觉词表。图像中的特征单词的词频构成了该图像的向量描述BoVW。假设视觉词表中的单词个数为N,那么BoVW向量的长度为N,向量中的元素为对应单词出现在该图像中的频次或者采用采用td-idf权重更新向量中每个元素值。
基础得到的视觉词库,计算所有图像(或视频中帧)数据的BoVW向量。检索进程启动时,将目标数据库中所有图像的BoVW向量构建索引。输入一副检索图像,提取该图像的BoVW特征,与目标库向量进行距离比对,查找近邻向量。最直观的查找方法是蛮力查找即将查询向量q与所有的BoVW向量进行距离计算。这种穷举方式对大数据集或高维向量的查找效率非常低。为改进这个问题,Video-Google[1]提出采用倒排文件IVF结构进行索引构建,IVF索引结构如下图所示。图中i表示每个视觉单词。
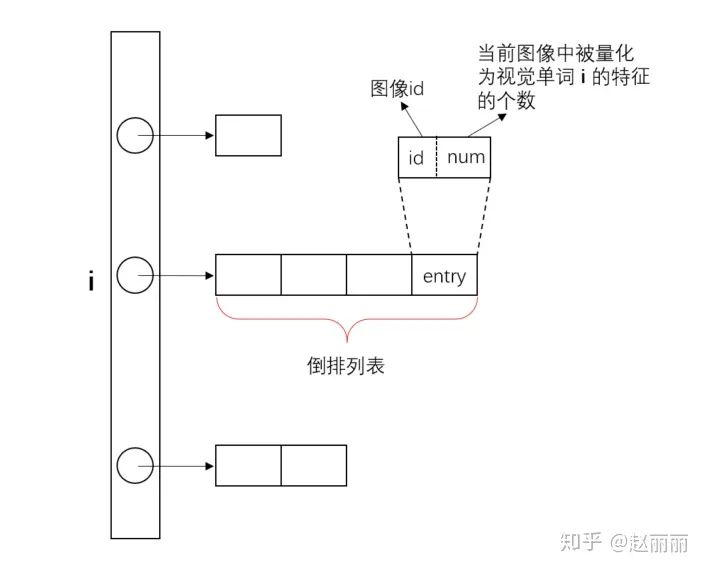
由于词向量通常是很稀疏的,我们无需遍历目标库中的所有文件,因而可以通过建立倒排文件,对每个单词构建一个列表,列表中是所有包含当前单词的图像meta信息。检索时,只需要计算那些与当前查询图像包含相同单词的图像的BoVW向量间的距离即可,即通过减小搜索范围来降低搜索复杂度。
Video-Google提供了经典的基于内容的图像检索流程,核心技术可以总结为两点:特征提取和近邻查找。后续图像检索基于大多基于此思想,针对不同业务场景下的数据特点,对涉及的特征提取和近邻查找技术进行优化,最终目标是提取能够高效表征图像的特征向量,进行快速视觉内容查找。
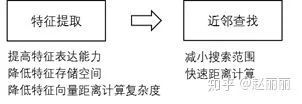
以下分别对近几年面向检索应用的特征提取和快速近邻查找的经典算法技术进行介绍。
三、图像特征提取技术
图像视觉特征分为多种,从存储形式分为浮点特征和二进制特征,从提取方式上分为传统特征和深度特征。卷积神经网络(CNN)出现之前,大部分特征是基于手工设计的提取算法进行特征提取,如sift、hog、harr、gist等。卷积神经网络在多项视觉任务如分类、检测、分割等表现出 state-of-the-art 的效果,在图像检索领域,基于CNN提取的深度特征同样也表现出远优于传统特征的效果。因此,本部分重点介绍深度特征提取技术,对于传统特征提取算法不作介绍。
无论是传统特征还是深度特征,从表征内容上可以化分为局部特征和全局特征。如传统特征sift为局部特征,而gist为全局特征;深度神经网络的卷积层输出feature map可理解为局部特征,而全连接层FC输出可视为图像的全局特征。使用局部特征表征图像时,需要将局部特征聚合成为能够表征图像整体信息的全局特征。此外,特征聚合还可以将不同数量的局部特征编码到同一长度,比如不同图像的sift特征个数是不同,使用聚合方法可以使得每张图像的特征表示长度相等。
特征Embedding
前面介绍的video-google使用BoVW向量来表征一副图像,是一种聚合方式。当视觉单词数量较多时,BoVW维度很高,对于类别复杂的大规模图像数据集,维度甚至会高达几百万,实际应用时会严重影响检索性能。此外,原始局部特征如sift具备一定的噪声,其可辨识性(discriminability)是受限的,即来自不相关的两幅图像的两个sift特征很有可能会被匹配成相似。因此,后续有许多局部特征Embedding的方法提出,用来将局部特征聚合生成更强可辨识性的图像特征。这些方法通常会生成比原始局部特征更高维度的向量,尽管如此,Embedding后的向量维度也远远低于BoVW的维度。常用的Embedding方法有VLAD[2]、Fisher Vector[3],Triangular embedding[4]等,已有实验表明这些方法应用于传统局部特征后得到的embedding特征能有效提高图像检索准确率。以下简单介绍VLAD和Fisher Vector的思想。
VLAD具体思路如下:基于学习数据中的所有局部特征向量x(d维),使用K-means聚类,得到k个质心  ;图像的VLAD表示是一个
;图像的VLAD表示是一个  x
x  维的向量,向量元素
维的向量,向量元素  ,
,  为质心索引,
为质心索引,  为局部特征向量中每个元素的索引,对每个输入向量x,计算距离它最近的质心向量
为局部特征向量中每个元素的索引,对每个输入向量x,计算距离它最近的质心向量  ,则 为所有距离 最近的特征向量与 之间的差异在对应向量位置j上的累积和,即
,则 为所有距离 最近的特征向量与 之间的差异在对应向量位置j上的累积和,即  。最后,对得到的 向量使用L2范式进行归一化。质心数k通常取16~256即可得到较好的效果。
。最后,对得到的 向量使用L2范式进行归一化。质心数k通常取16~256即可得到较好的效果。
Fisher Vector[3]可以通俗的将Fisher Vector理解为对高斯混合分布GMM的参数均值、方差和分量权重球偏导得到的梯度向量。其物理含义为:对于两幅不同的输入图像,其特征点的分布可能是相同的,但是其变化方向(梯度)相同的概率非常小,因此可以用分布的梯度来更加准确地表示输入图像。具体细节参见原始论文。Fisher Vector也是对原图像特征进行升维操作,假设原始特征向量维度为d,GMM分量个数为N,Fisher Vector的维度为(1 + d + d)* N - 1 。原始论文非常理论,感兴趣的可以读一下。
以上聚合方法的特征维度比原始特征维度更高,因此若后续对聚合后的特征进行PCA操作,会增加计算复杂度,同时还可能导致数据过拟合。
深度特征
Neural Codes for Image Retrieval[5]这篇文章评估了基于CNN的深度特征应用于图像检时的效果。以下是论文给出的一些结论:
1) 在分类数据集上训练得到的深度特征应用于不同数据集的检索任务时仍然起作用;
2) 在检索数据集上finetune分类模型,能够大幅提高检索效果;
3) PCA降维应用于深度特征能够在几乎不降低检索准确率的同时有效压缩特征长度;
4) 借鉴"fisher vector faces in the wild"中的方法学习投影矩阵,进行向量降维(应用于alexnet倒数第二层fc),效果比PCA降维好非常多。[5]在选择用于学习投影矩阵的训练数据时采用如下方式:对目标数据中构建匹配关系图,所有相似的图像对被通过边连接,图构建完成后,采用以下方式选择训练数据图像对:若图像A和图像B不相连,且他们都与图像C相连,那么A和B构成相似图像对,且A和C或者B和C不能组成图像对。这种操作是为了避免训练图像对中出现两幅图像是near-duplicate的情况。投影矩阵的学习过程可以参见“fisher vector faces in the wild”原文。
深度神经网络卷积层输出的特征(下称深度卷积特征)被认为是代表特定特征感受野得到的局部图像特征,因此每个深度卷积特征可被看作是某种使用传统特征如sift提取得到的局部特征。2015年的这篇论文[6]调研和评估了应用于图像检索时,各种特征聚合方法作用于深度卷积特征得到图像的全局特征表示。论文表明:不同于传统特征如sift,对于深度卷积特征,通过累加求和生成的聚合特征SPoC(sum-pooled convolutional features)的检索效果优于使用VLAD[2],Fisher Vector[3]和Triangular embedding[4]等方法得到的聚合特征的检索效果。注意,论文中作者在导论部分也提到,之前有学术工作表明基于深度卷积特征+Fisher Vector的Embedding方式生成的特征在分类任务上是非常有效的。
对于输入图像I,SPoC的生成方法如下:
1) 对输入I进行推理得到最后一个卷积层的输出特征f,对f(维度C x W x H)进行空间维度上的求和,得到维度为C的特征向量 
2) 大多数图像包含的核心信息在图像的中间部分,因此对上面得到的特征向量  引入位置系数
引入位置系数  ,即
,即  ,
,  可以通过高斯函数计算加权值。
可以通过高斯函数计算加权值。
3) 对  进行PCA降维去相关性和白化操作
进行PCA降维去相关性和白化操作  。其中
。其中  是维度为
是维度为  x
x  的PCA投影矩阵,投影后
的PCA投影矩阵,投影后  的维度为 。当
的维度为 。当  时,投影仅起去相关性作用;
时,投影仅起去相关性作用;  时,起到降维作用。
时,起到降维作用。  为矩阵奇异值构成的对角矩阵,奇异值是PCA协方差矩阵特征值的平方根,而对角矩阵的逆矩阵的对角元素为原始矩阵对角元素的倒数,因此 操作为PCA白化过程中的标准差归一化操作。
为矩阵奇异值构成的对角矩阵,奇异值是PCA协方差矩阵特征值的平方根,而对角矩阵的逆矩阵的对角元素为原始矩阵对角元素的倒数,因此 操作为PCA白化过程中的标准差归一化操作。
4) 对 进行L2范式归一化即可得到最终的SPoC聚合特征  。
。
SPoC特征在进行PCA协方差矩阵和奇异值求解时的计算更加高效,且不会出现以上VLAD等embedding方法导致的数据过拟合现象。SPoC [6]通过实验分析得出一些有意思的结论,以下列出,方便读者在实际落地场景中选择技术方案时参考。
1) 原始sift特征的可辨识性有限,应用于图像检索时,sift特征间的相似性计算结果可信性不大。作为对比,深度卷积特征作为局部特征,相似性计算结果更加可信。
我们实际应用中也发现,传统局部特征存在明显噪声,基于原始特征进行最邻近匹配准确率会低于VLAD embedding后的特征的匹配效果。
2) 对深度卷积特征进行sum pooling比max pooling有效。
3) 深度卷积特征与传统特征的分布特性不同,前者比后者具有更高的可辨识性,因此可以无需使用面向传统特征的聚合方法VLAD、Fisher Vector、Triangular embedding。
4) PCA降维应用于SPoC特征能够提升检索效果。
5) 对深度网络全连接层输出的特征fc应用VLAD Embedding对检索效果有提升,但对模型使用目标数据进行finetune后得到的fc检索效果优于fc+VLAD [5]。
最后,我们在实际应用中也发现,SPoC特征进行相似重排序明显优于fc特征。
二进制特征
前面提到特征按照存储方式又分为浮点特征和二进制特征。使用浮点特征表征图像信息,进行距离计算时能够更加细粒度地衡量图像间的差异,缺点是距离计算复杂度较高,此外浮点向量在进行存储时占用空间也更大。相比之下,二进制特征的存储更加高效,且向量间差异通常采用hamming距离衡量,计算复杂度较低。二进制特征的缺点是距离衡量粒度较粗,如对于128维度的二级制特征,图像间差异只存在128个数值范围内。
实际业务应用时,我们将二进制特征用作减小搜索空间的一种方式,采用多级查找方式,首先对查询图像与目标数据库中的图像的二进制特征进行汉明距离计算,选取top N距离对应的图像,然后再进行浮点向量间的距离计算,优化查找准确率。
将浮点特征Embedding成二进制特征的方法很多,如spectral hashing[7],读者感兴趣可以参考这篇文章[8]的Introduction部分,此处不赘述。对于深度特征,最简单的embedding方法是将输出特征(sigmoid化的)使用0.5 hard thresholding得到[9]。
基于深度特征采用0.5 thresholding的方式操作简单,检索效果也可满足实际应用需求。
四、快速查找技术
对于大规模高维向量数据集的检索任务,查找性能优化是核心问题。高维向量的检索性能优化通常分两种方式:一是查找优化,比如建立倒排索引,这种方式通过优化检索结构进行性能优化,不改变向量本身;另一种是向量优化,通过将高维浮点向量映射为低维向量,或者映射到汉明空间,以此减少距离计算复杂度;实际应用时,常常结合这两种方式进行检索优化。
查找优化
检索任务的最终目标是返回与查询值最相似的结果,通常分为最近邻查找(NN)和近似最邻近(ANN)查找。最近邻查找总能返回与查询值最相近的结果,如穷尽查找法,通过对全部目标向量数据进行遍历和计算得到最接近距离值,复杂度很高。一种优化的NN算法是通过构建K-D树进行查找,但在高维空间K-D树查找效率低效,复杂度近似等于蛮力搜索O(nD)。
ANN通过减小搜索空间的方式,提高查找效率。相比最邻近查找,ANN能够大幅度提高检索效率,找到近似最近距离的匹配目标。使用ANN检索到的匹配目标有效的原因在于:在实际应用中,如果距离测量准确地捕捉到查询所关注的核心内容,那么距离的细微差别就不重要了。比如我们在进行相似图片查找,真实情况下的最相似结果,和近似相似结果在视觉效果上差距往往很小。事实上,如果ANN的返回结果的质量严重差于真实最近邻查找返回的匹配结果,那么本身这个最近邻查找问题就是不稳定的,解决这样的一个问题也就没有什么意义了[10]。
LSH[10]是常用的一种近似临近查找方式,通过将原始数据摄影到某种空间后查询大概率最邻近结果,解决高维空间内的海量数据搜索问题。这篇博客[12]给出了LSH的通俗解释:“将原始数据空间中的两个相邻数据点通过相同的映射或投影变换后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。对原始数据集合中的所有数据都进行hash映射后,我们就得到了一个hash table,这些原始数据集被分散到了hash table的桶内,每个桶会落入一些原始数据,属于同一个桶内的数据就有很大可能是相邻的,当然也存在不相邻的数据被hash到了同一个桶内。因此,如果我们能够找到这样一些hash functions,使得经过它们的哈希映射变换后,原始空间中相邻的数据落入相同的桶内的话,那么我们在该数据集合中进行近邻查找就变得容易了,我们只需要将查询数据进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行线性匹配即可查找到与查询数据相邻的数据。换句话说,我们通过hash function映射变换操作,将原始数据集合分成了多个子集合,而每个子集合中的数据间是相邻的且该子集合中的元素个数较小,因此将一个在超大集合内查找相邻元素的问题转化为了在一个很小的集合内查找相邻元素的问题,显然计算量下降了很多。”
构建一个hash table可能需要一个或多个hash function。hash function需要满足两个条件:
1)如果d(x,y) <= d1, 则h(x)=h(y)的概率至少为p1;
2)如果d(x,y) >= d2, 则h(x)=h(y)的概率至多为p2;
其中d(x,y)表示x和y之间的距离,d1<d2, h(x)和h(y)分别表示对x和y进行hash变换。
LSH算法框架包括离线建立索引和在线查找两个过程。其中索引建立过程,确定hash table的个数以及每个hash table包含的hash function个数,和具体采用哪种hash function。然后,将目标数据库中的所有数据经过hash function映射到hash table的桶内。在线查找包括两个部分,将查询数据映射到相应桶内和计算与相应桶内的数据的距离。
查找优化-Hamming Embedding
Video-google[1]中使用倒排文件索引,实际上也属于ANN的一种。倒排索引结构将查找过程分成两部分,索引查找和距离重排序(Reranking)。索引查找一般用穷尽法,遍历得到与查询向量相近的视觉单词对应的索引,进而得到要进行Reranking的候选特征向量;对查询图像的特征向量与候选列表向量进行距离计算并对结果重排序,返回最近邻结果。倒排文件通过聚类生成量化器,对原始特征进行量化,建立索引。量化操作可以过滤特征本身的噪声,使得相似的特征能够被匹配到,但是也会引入量化噪声。因此建立量化器时(聚类),选取合适的类簇数K非常重要:当K较小时,查找索引的复杂度较低,但是倒排列表包含候选元素较多,进行距离重排序的复杂度较高,同时量化噪声较大;当K较大时,查找索引的复杂度较大,但进行距离重排序的复杂度较低,量化噪声也较小。
Hamming Embedding[11],HE使用二级量化方式来平衡量化噪声和检索复杂度。它的核心思想是在传统量化基础上将向量embedding到binary空间,使用hamming距离阈值,减小重排序候选列表的长度。HE使用粗量化器q(coarse quantizer)和细量化器b(fine quantizer),二级量化的方式。每个输入特征x对应两个量化结果q(x)和b(x)。粗量化器使用上述基于聚类的量化方式,质心数k较小,粒度较粗。细量化器是使用投影矩阵将浮点向量embed到二进制向量的过程,投影矩阵使用训练数据学习得到,学习过程如下:
假设 为原始特征维度,  embed后的二进制特征维度,学习集合
embed后的二进制特征维度,学习集合  ,
, 为学习集包含的向量个数。
为学习集包含的向量个数。
1) 生成维度为 x 的正交投影矩阵P。具体生成方式为:随机产生一个高斯矩阵,对高斯矩阵进行QR正交分解,提取正交矩阵Q的前 行向量构成投影矩阵  。
。
2) 对学习集  中的每个向量
中的每个向量  使用矩阵P进行投影,
使用矩阵P进行投影,  ,得到向量
,得到向量  。
。
3) 对于cluster  ,计算其中值投影向量
,计算其中值投影向量  。 的每个元素
。 的每个元素  为所有被量化到当前cluster 的向量经过步骤(2)得到的
为所有被量化到当前cluster 的向量经过步骤(2)得到的  的中值,即
的中值,即  。
。
Embedding阶段,对目标集合  中的每个向量
中的每个向量  执行以下操作。注意
执行以下操作。注意  。
。
1) 粗量化器q量化  ,得到量化后向量q( );
,得到量化后向量q( );
2) 使用投影矩阵 将 投影到向量  ;
;
3) 细量化器将 映射到二进制向量  ,计算公式如下:
,计算公式如下:
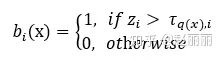
对于查询特征x和目标特征y,最终的特征匹配方法定义如下:
#知乎打大括号好难,所以此处用'伪伪代码',凑合看吧if q(x) == q(y) && h(b(x), b(y))<= h_t: f(x,y) = tfidf(q(x))else: f(x,y) = 0
f(x,y)为x和y的匹配值,h()为汉明距离计算,h_t为距离阈值。
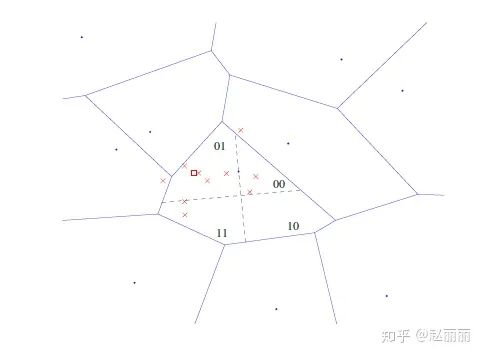
下图展示了HE的物理含义。图中voronoi多边形代表粗量化器q划分得到的一级空间,候选向量经过voronoi cell进行初步划分;然后对当前cell内再由binary空间进行二次划分,下图以二维binary特征为例,将每个voronoi cell又划分为四个hamming空间。搜索范围限制在同一个voronoi cell中的同一个hamming空间内。
为了提高几何仿射变换的检索稳定性,HE论文还提出一种weak geometrical consistency的方式,该方式结合到倒排索引的构建过程中,可以高效执行,此处不赘述。
结合HE二级量化方式的倒排索引结构中,每个entry对应一个特征即entry per descriptor(但仍存储image id)。在进行检索时,计算每个待查询特征x的二进制向量b(x)与被查询特征y的二进制向量(预先计算且存储)的汉明距离,若距离小于阈值h_t则使用上面公式计算相似距离;否则,认为y与x不匹配,跳过y,不计入image score的计算。
查找优化-IMI
倒排多索引(Inverted Multi-Index, IMI)[13]是对倒排索引的一种改进方法。
传统倒排索引在面对海量大规模数据如上千万甚至几十亿条数据向量时,构建的索引结构每个特征单词对应的倒排列表中包含的元素(entry)数目巨大,增加了后续reranking的计算量,严重影响检索速度。最直观的改进方法是增加索引特征单词的数量,使得每个索引值对应的倒排列表包含的元素数量相对较少,即缩小reranking的搜索空间,以此优化重排序速度性能。但这种性能优化方式会引入额外的时间开销:首先,索引单词数量越大,构建索引结构的时间开销也越大;其次,检索时,查找与query单词匹配的索引单词的时间开销也会增加。
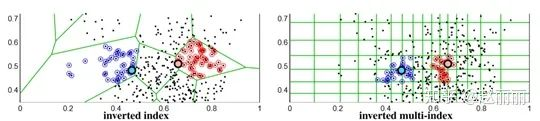
为解决以上问题,IMI采用乘积量化(product quantization)的思想构建多索引结构来优化重排序搜索空间。传统的倒排索引结构的索引的存在形式是一维数据,而倒排多索引结构的索引用一个多维度的table。使用倒排多索引结果进行检索时,返回的候选倒排列表更短,同时候选元素与查询单词距离更近,召回率更高。以二维索引table为例,多索引结构比传统索引结构检索效果更优的物理意义如下图所示。对于传统倒排索引结构(一维),属于同一个索引单词的向量位于相同的voronoi cell内,查询时,对匹配到查询向量的索引单词所在的voronoi cell内的所有元素都要参与reranking。以左图中绿色所示查询向量为例,返回候选元素中大部分与查询向量间的距离较远。而右图倒排多索引所示二维空间划分结构所示,绿色查询向量匹配的候选元素更加集中,与查询向量间的距离较近。
注意下文介绍的向量优化方法[15]使用PQ优化特征向量,降低距离计算复杂度,而IMI将PQ应用于索引构建和查找的过程。二者应用PQ的阶段不同,实际应用中可以将二者结合,使用PQ构建多索引结构,检索时快速匹配到候选索引,在reranking时再应用[15]进行快速距离计算。
倒排多索引table可以是二维或者更高维度,维度越高,reranking 搜索空间粒度越细,存储开销也越大。二维table在存储空间、检索时间以及检索准确性能之间能达到较好的平衡。下面以二维多索引为例,介绍多索引构建和检索过程。
索引构建. 假设数据集D包含N个M维特征向量。多维倒排索引将特征向量划分成S个子向量,S=2对应二维倒排索引。最简单的划分方式是按照长度平均划分,比如化分为两个M/2维的向量,对应位置的子向量构成新的数据集D1和D2。划分时要保证D1和D2数据是不相关的。分别对D1和D2进行聚类,生成两个码表U和V,每个码表包含K个特征单词(对应K个类簇)。
检索. 给定查询向量q,返回T个候选向量。检索分三个阶段:
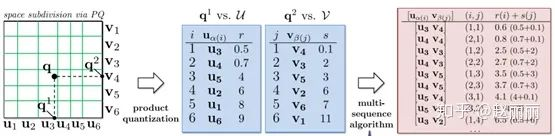
Stage 1. 给定查询向量q=[q1,q2],对于q1和q2分别查找并返回码表U和V中距离q1和q2最近的L个码字,按距离升序分别记为r(1),r(2),r(3),…, r(L), 和 s(1),s(2),s(3),…, s(L)。U和V通常包含较少码字,一般为几千个,因此可用穷尽法查找。
Stage 2. 对stage1返回的列表,计算距离r(i)+s(j),0<I,j<=L,按照距离升序返回TOP距离对应的码字组合(u_i v_j),如下图所示。最终返回的T个候选向量为u_i包含的向量和v_j包含的向量的交集。
上述过程中,作者提出使用multi-sequence算法进行距离计算和比较。算法基于优先级队列,入队列元素为码字索引对(i,j),优先级数值定义为码字索引(i,j)对应的距离的负值,即优先级priority=-(r(i)+s(j))。算法输出为T个候选向量,具体流程如下:
1) 输出候选向量列表OUTPUT为空,码字索引组合(1,1)入队列;
2) 若队列不为空,pop索引组合(i,j),该索引组合为优先级最高即距离最近的索引对,将该索引组合对应的候选元素加入到输出列表OUTPUT中;若OUTPUT长度>=T,程序中止;否则执行步骤3);
3) 若(i+1,j-1)不在队列中,则将(i+1,j)入队列;若(i-1,j+1)不在队列中,则将(i, j+1)入队列;
4) 执行步骤2)和3);
下图示意了multi-sequence算法的执行过程。
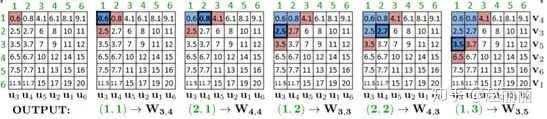
Stage 3. 对OUTPUT列表中的T个候选向量reranking。这个过程可以结合其他快速相似距离计算的方式,比如PQ,比如binary embedding等方式。论文 提出使用PQ一文的ADC算法进行快速距离计算。进一步提高了检索速度。
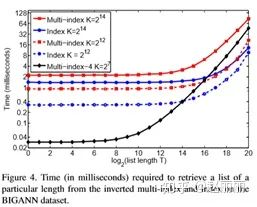
倒排多索引(multi-index)与传统索引(standard index)存储和时间开销对比:
1) 对于大小为K的码表,传统索引需要K个倒排列表W_i, 0<i<=K,而多索引要K*K个倒排列表W_i,j 0<i,j<=K,因而multi-index额外引入了存储开销,但所有列表包含的元素数量的总和没有增加,与standard index相同,即共N个元素(这里的元素可能是特征向量或压缩后的特征向量或是image id,feature id等metadata)。实际应用时,N个元素存储在连续空间内,因此,W_i,j只需要存储当前列表在连续空间中的起始位置(用一个整数)即可,存储这些起始索引的空间总开销为K*K*4,平均每个元素的额外开销为 K*K*4/N (原始论文中写成了K*4/N,应该是笔误)。这部分开销相对于元素本身占用的内存空间可以忽略不计。
2) 传统倒排索引结构中每个倒排列表中包含的元素数量是相对均匀的,如上上上个图所示,落入每个voronoi cell中的数据个数是接近的,而倒排多索引结构中落入每个grid中的元素数量是不平衡的,有些grid中包含元素个数甚至为0,尽管如此,每个grid内的元素更加密集,因此multi-index表现出更好的检索召回效果。
3) 使用multi-sequence算法计算top最优索引组合时,会带来额外时间开销,这部分的时间对比如下图所示。但这部分开销相比较后续reranking的操作时间,可以忽略。
查找优化-深度特征
IMI索引方法的需要保证特征向量划分后的多个数据集是不相关的,对于传统特征如sift是满足该条件的。对于这种特征,构成特征向量的不同元素用来描述图片不同区域的特征,可通俗理解为一个128维sift特征的前64维特征提取自图像A区域的特征,后64维提取完全不相交的B区域的特征。然而深度特征并不具备上述可分条件,划分后的数据空间具有较强相关性,因而IMI应用于深度特征具有局限性。
这篇论文[14]给出了面向海量深度特征数据的快速索引方法,提出了一种非正交的IMI索引方法,Non-Orthogonal Inverted Multi-Index. No-IMI索引结构定义如下:
NO-IMI包括两个码表,S和T,每个码表的包含K个码字,S称为1阶码表,为原始数据聚类生成。T为2阶码表,为原始数据与各对应1阶cluster的质心(S中码字)之间的残差值聚类生成。如下图中是个蓝色点代表1阶质心,红色点代表2阶质心。与IMI类似,NO-IMI将数据空间划分成K*K个单元;但与IMI不同的是,NO-IMI不对向量空间划分,即S和T中码字长度等于特征向量长度D。K*K单元的码字为S和T码字的和,即c_i,j = S_i + T_j。每个单元C_i,j包含了距离该单元码字c_i,j最近的所有特征向量。
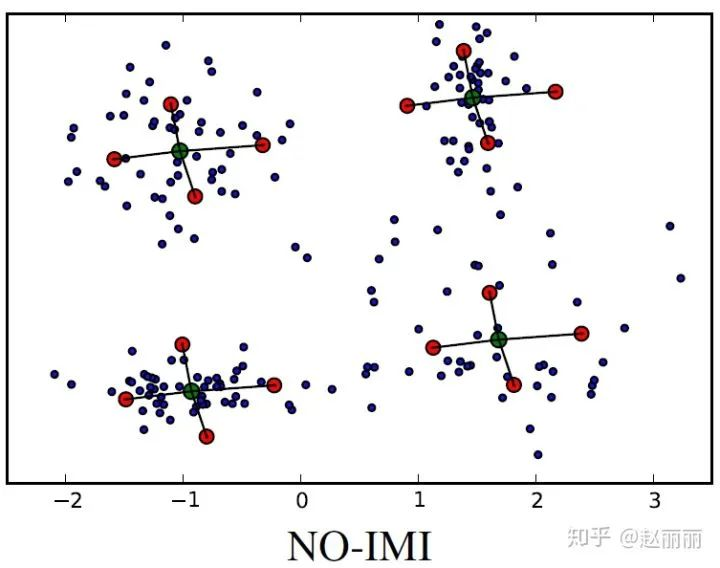
No-IMI的聚类过程与Hierachical K-Means有些类似。区别在于:HKM的每个2级聚类是在对应1级cluster下进行的,即在运行期间需要保存K*K个向量数据。但NO-IMI的2级聚类共享所有cluster的残差,因此只需要保存K+K个向量数据,大大节省了运行时内存占用。
NO-IMI共享所有1级cluster的向量残差需要保证每个cluster的向量残差数据分布是相同的,为了满足这个条件,NO-IMI引入一个KxK大小的权值矩阵alpha-matrix,该矩阵每个元素作用于对应的cluster,如alpha_i,j为第j个二级cluster对应于第i个一级cluster时的权值因子。即c_i,j = S_i + alpha(i,j)T_j。
NO-IMI索引构建过程包括两部分:码表学习和索引构建。码表学习阶段生成S、T码表和alpha矩阵。论文中将学习目标定义为最小化所有训练数据与其最近的cell的质心的距离的和,如下式所示。为达到这个优化目标,NO-IMI采用block-coordinate descent方法迭代求解S、T和alpha的最优值。在迭代之前,S码表被初始化为原始数据聚类生成的码表;T码表被初始化为对残差数据聚类生成的码表。

索引构建时,对数据集中的每个特征向量p计算其与c_i,j的距离,得到距离最近的cell的索引。
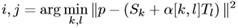
若采用穷尽法,对每个向量p要组合所有的S和T的码字取值,因此需要计算K*K次才能得出最佳索引。仔细观察,上式距离计算公式可进一步分解为4个部分:
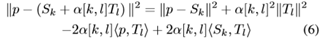
其中,<>为向量内积操作。上式中,第1项和3项的  的时间复杂度为O(D*K);第2项和第4项可以事先计算好存储在loopup表格中,因此这两部分的时间复杂度为O(1)。其中,在选择1级cluster时,可以从K中选取最近的r个cluster进行计算,r<<K,因此第3项alpha*<p,T_l>的时间复杂度为O(r*K),因此最终距离计算的复杂度为O(DK+rK)。
的时间复杂度为O(D*K);第2项和第4项可以事先计算好存储在loopup表格中,因此这两部分的时间复杂度为O(1)。其中,在选择1级cluster时,可以从K中选取最近的r个cluster进行计算,r<<K,因此第3项alpha*<p,T_l>的时间复杂度为O(r*K),因此最终距离计算的复杂度为O(DK+rK)。
NO-IMI检索过程. 对于输入查询向量q,检索过程分为返回top L个cell对应的候选向量列表,和对于候选向量reranking两部分。此处只介绍返回top L个cell的过程。reranking操作不是这篇论文大的核心。可参考其他技术方案。
1) 计算q与一阶码表S中各码字距离,返回top r最小距离和对应码字索引;时间复杂度为O(KD+KLogK)
2) 计算q与二级码表T中各码字距离,计算(6)中的最终距离;这个步骤返回一个rK大小的数组,包含公式(6)计算得到的q与r个1级K个2级码字的距离;时间复杂度为O(rK)
3) 对2中的rK个距离排序,返回top L距离的cell的候选向量列表。
向量优化
上文介绍的查找优化方法通过减小搜索空间,提高检索效率。另外一种优化检索性能的方式是进行向量的重映射,将高维浮点向量映射到其他空间,映射后的向量可以采用更高效的方式进行距离计算。前面提到的二进制特征embedding的方式,也属于向量优化。
这里我们详细介绍一种基于乘积量化(Product Quantization)的向量优化方式[15]。PQ在这里用来解决的重排序时的向量间距离的快速计算的问题。它的核心思想是分割向量,对分割后的向量空间建立独立码表;通过将高维向量分割成多个低维向量,达到节省存储空间的目的;通过subvector-to-centroid的查表方式,达到降低计算复杂度的目的。
在进行介绍之前,先约定以下定义。质心-聚类得到的质心向量;码字-质心向量的索引;码表-各质心和码字对应关系的集合。
问题提出. 如果我们对所有相似的向量用一个向量(质心)来表示,那么我们可以把各质心间的距离预先计算出来,在实时查询时,只需要找到查询向量和被查询向量各自的质心索引,就可以得到二者的距离,也就可以避免去实时计算距离,对于高维浮点向量,这样能够大大减少重排序时间。这样有效的前提是,质心与其对应类簇的向量都足够接近。假设我们用聚类的方式来得到质心,那么类簇数越多。质心越具有代表性。极限情况下,类簇数等于数据库中向量数目,相当于查询向量与每个向量进行距离计算,量化误差为0。
假设目标数据库中每个向量用对应质心的索引来表示,质心个数为 ,编码这些质心索引的码字长度为 ,  。上面提到质心数越多,量化误差越小;假设要学习的质心数
。上面提到质心数越多,量化误差越小;假设要学习的质心数  ,那么学习到这些质心所需的样本向量数要远远高于 ,这样带来两个问题:1.使用如此大量级的样本向量学习质心的计算复杂度非常高;2.存储空间占用大,假设每个向量是128维浮点向量,平均每个质心对应的类簇包含的样本向量数为N,那么要存储这些学习样本需要
,那么学习到这些质心所需的样本向量数要远远高于 ,这样带来两个问题:1.使用如此大量级的样本向量学习质心的计算复杂度非常高;2.存储空间占用大,假设每个向量是128维浮点向量,平均每个质心对应的类簇包含的样本向量数为N,那么要存储这些学习样本需要  bytes。
bytes。
为解决以上问题,PQ借鉴笛卡尔乘积思想对向量进行量化。具体量化方式如下:
假设输入向量  ,将
,将  分割成m个子向量,每个子向量长度为
分割成m个子向量,每个子向量长度为  。对每个子向量
。对每个子向量  ,使用量化器
,使用量化器  进行独立量化(即聚类),量化后码字索引(即质心索引)集合为
进行独立量化(即聚类),量化后码字索引(即质心索引)集合为  ,对应子码表
,对应子码表  (即质心向量的集合)。NOTE: SUCH product-based approximation works better if the D/m-dimensional components of vectors have independent distributions.
(即质心向量的集合)。NOTE: SUCH product-based approximation works better if the D/m-dimensional components of vectors have independent distributions.
输入向量 的码表 定义为各个子码表 的笛卡尔乘积:

笛卡尔乘积的定义参见下图

假设每个子码表 包含的质心数相等,均为  。那么可以得到,码表 包含的质心数
。那么可以得到,码表 包含的质心数  。因此,要得到 个质心,只需进行m次“对
。因此,要得到 个质心,只需进行m次“对  维度的向量进行聚类得到 个质心”,大大降低了计算和存储复杂度。基于笛卡尔乘积,PQ方法的本质在于使用小规模的质心集合中的元素排列组合生成大规模的质心集合。
维度的向量进行聚类得到 个质心”,大大降低了计算和存储复杂度。基于笛卡尔乘积,PQ方法的本质在于使用小规模的质心集合中的元素排列组合生成大规模的质心集合。

以128为向量为例,要学到 个质心,当m=8时,只需要对每个维度为  的子向量学到
的子向量学到  个质心,存储这些学习样本只需要
个质心,存储这些学习样本只需要  bytes,远远小于上面原始存储空间需求 bytes。
bytes,远远小于上面原始存储空间需求 bytes。
PQ方法相比hamming embedding方法的一个优势在于,PQ的量化空间非常大(质心数),可表示的向量之间的差异远远超过汉明空间能表示的向量差异。如质心数为2^64时,使用PQ方法,128维度向量的量化取值有2^64种。
距离计算. PQ提出两种距离计算方式:SDC(symmetric distance computation)和ADC(asymmetric distance computation)。假设x为查询向量,y为要与之进行距离计算的目标数据库向量。q(x)和q(y)分别为二者的量化结果,即各自对应的质心向量的索引。
SDC为对称距离计算,即查询向量和数据库向量均质心向量进行距离计算,即d(x,y) ~= d(q(x),q(y))。
ADC为非对称距离计算,计算查询向量和数据库向量对应质心向量间的距离,即d(x,y) ~= d(x, q(y))
为提升检索效率,各子向量空间下质心向量间的距离是被预先计算和存储的。
SDC和ADC的距离计算流程如下:
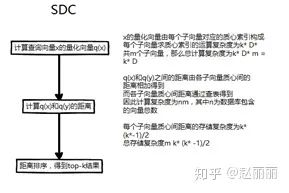
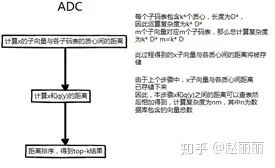
可以看出,无论是SDC还是ADC,在进行距离计算时,核心操作只包含查表和加法,大大降低了检索复杂度。SDC和ADC的计算复杂度类似,ADC比SDC多了部分运行时内存需求,即需要实时保存x子向量与各质心间的距离,共mk*个元素的存储空间,实际应用时这部分内存空间可以忽略不计。但是,ADC方法由于使用未量化的查询向量进行距离计算,量化误差相比SDC更小,因此作者建议实际应用时,采用ADC方法。
检索. PQ采用向量优化的方式,检索时在近似最邻近空间内仍采用穷尽法进行遍历,因此PQ论文提出使用ADC方法结合倒排索引的方法IVFADC(inverted file system with the asymmetric distance computation),进一步缩小检索空间,提升检索性能。IVFADC的检索架构如下图所示。
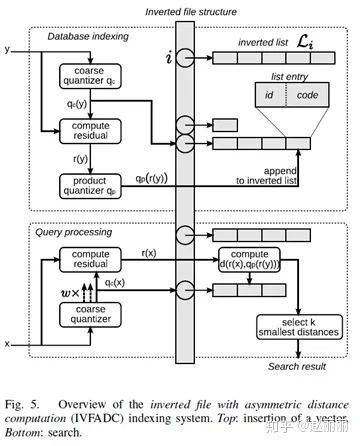
IVFADC包含两级量化操作。第一级量化是一个粗粒度量化过程,采用类似于video-google文中的方法,对数据库中的向量进行粗粒度K-means聚类,生成码表和量化器  ,该码表的码字构成了倒排索引结构中的每个节点。第二级量化是对残差向量使用乘积量化器PQ量化,生成码表和量化器
,该码表的码字构成了倒排索引结构中的每个节点。第二级量化是对残差向量使用乘积量化器PQ量化,生成码表和量化器  。
。
IVFADC的索引构建过程,即为对数据库中每个向量y执行如下流程的过程。
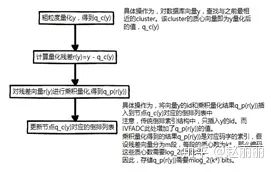
检索流程描述如下:
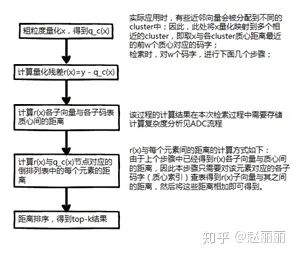
IVFADC检索复杂度分析:使用倒排索引结构,ADC额外增加的计算时间为粗粒度量化x的时间,假设粗粒度码表包含  个cluster,那么
个cluster,那么  的操作复杂度为
的操作复杂度为  ;而在检索时,若采用穷尽搜索,需要遍历数据库内所有n个元素,而引入倒排索引,仅需要遍历w(n/k')个元素(此处假设每个倒排列表包含元素数量均衡) 。
;而在检索时,若采用穷尽搜索,需要遍历数据库内所有n个元素,而引入倒排索引,仅需要遍历w(n/k')个元素(此处假设每个倒排列表包含元素数量均衡) 。
五、工业界案例
以上对视觉检索流程中涉及的经典算法技术进行了介绍。近两年工业界也陆续开公开了各自视觉检索技术的技术案例,本部分以电商平台ebay[16]和社交凭条Pinterest[17]为例简单介绍。
ebay基于深度哈希特征的相似图像检索方法,包括特征提取和检索策略以及检索基础架构的技术方案。特征部分,ebay采用基于深度神经网络全连接层输出的sigmoid特征的0.5 threshold映射后的二进制特征。索引部分,ebay采用多级检索方式。对所有商品定义叶子类别,即非常细粒度的类别,细化到如‘运动鞋’、'高跟鞋'等。在深度神经网络进行特征学习的过程,同时进行叶子类别分类的学习,二者共享部分网络特征。如下图所示:
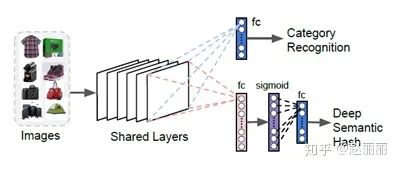
检索时,1.查询图像仅在相同或相近的叶子类别中进行检索,大幅度减少了目标检索数据量;2,.然后对新的目标检索空间S下的数据进行hamming距离计算,采用穷尽法遍历,返回距离的最相近的Top list L;3.最后,对L中的数据结合商品属性标签进行重排序,返回最终的top相似结果。商品属性包括不同的品牌、颜色等, 通过XGBoost训练得到商品属性预测模型。模型训练的输入是深度特征向量,文中提到使用了ResNet-50的pool5层输出向量。工程架构方面细节可参见论文。此不赘述。
Pinterest[17]这篇技术论文的公开时间早于ebay,整体内容与ebay类似,从特征到检索架构介绍视觉相似检索。此外,这篇文章提到了实际场景中常遇到的大规模图像数据检索服务的特征更新问题。特征更新主要是解决不影响现有服务运行的前提下高效生成增量特征的问题。增量特征包括两部分:新增图像对应的特征和算法模型更新带来的历史图像数据的特征更新。Pinterest文中按照特征类型、版本和时间分开存储。特征类型如全局特征、局部特征、深度特征、传统特征、浮点特征、二进制特征等;版本对应算法模型更新;每个特征类型的每个版本对应一个feature store,每个feature store包含多个epoch,每个epoch对应新增图像数据的特征提取。在这种存储方案下,对于每天新增图像数据,找到各特征类型的各版本,增加对应时间的feature epoch;对于新的特征或算法模型的更新,生成一个新的feature epoch,遍历所有历史图像数据,生成对应epoch。
此外,Facebook也在去年开源了其多媒体数据向量聚类和检索库Faiss[18]。Faiss主要解决聚类和检索问题,当前版本的Faiss实现了各种聚类算法和经典的索引构建以及快速查找算法,包括上文介绍的IVF、IMI、PQ、LSH等。Faiss不提供特征提取接口,即开发人员需要针对自己业务场景下的多媒体信息提取特征向量。注意,各种索引构建和查找算法,是依赖于向量分布特性的。比如应用PQ算法时,需要保证划分后的向量空间是独立的,若划分后的向量强相关,那么查找效果可能会较差。也就是特征提取算法和检索算法是相互依赖的。深度特征的分布与传统特征是不同的[6],对于视觉内容的检索问题,当前版本的Faiss提供的方法更适合传统方法提取的特征向量。
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
猜您喜欢:
超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 | 《Python进阶》中文版
附下载 | 经典《Think Python》中文版
附下载 | 《Pytorch模型训练实用教程》
附下载 | 最新2020李沐《动手学深度学习》
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 |《计算机视觉中的数学方法》分享
