最近在准备找工作面试,本文在此梳理了目标检测中涉及的面试要用的知识点,包含了一下几方面:
My paper reading 过程总结:
| 实际步骤 |
所花时间 |
评价 |
改进 |
| 先看了abstract, 1 introduction 以及 4 related works这三个部分,对objection detection 有了大致了解 |
0.5U |
|
|
| 看了2.1的Model部分,上网查找RCNN系列以及SSD和YOLO系列的总结对比 |
0.75U |
对这些模型底层实现都不了解,所以网上的总结整理有点没太看懂 |
先看SSD的具体原理,再速看YOLO系列原理,和SSD对比,R-CNN系列可以不看 |
| focus on SSD |
|
|
|
模型列表:
- R-CNN
- SPPnet
- Fast R-CNN
- Faster R-CNN
- YOLO
- SSD
阅读博客(主要阅读):
参考博客:
博客笔记:
笔记:
(1) 分类:
1 以RCNN为代表的基于Region Proposal的深度学习目标检测算法(RCNN,SPP-NET,Fast-RCNN,Faster-RCNN等);
2 以YOLO为代表的基于回归方法的深度学习目标检测算法(YOLO,SSD等)。
RCNN系列:
| 模型 |
原理总结 |
优点 |
缺点 |
| 传统方法 |
区域选择(滑窗)、特征提取(SIFT、HOG等)、分类器(SVM、Adaboost等)三个部分 |
|
一方面滑窗选择策略没有针对性、时间复杂度高,窗口冗余;另一方面手工设计的特征鲁棒性较差 |
| RCNN |
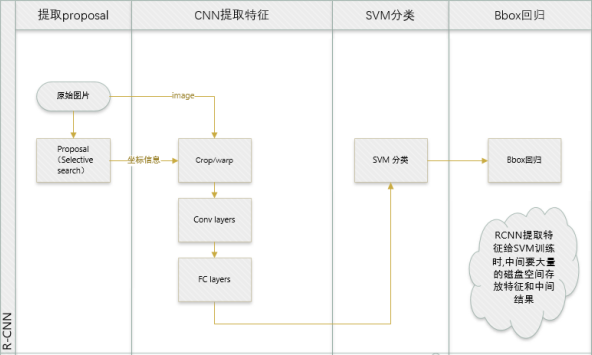
流程; 1 使用Selective Search提取Proposes,然后利用CNN等识别技术进行分类。 2 使用识别库进行预训练,而后用检测库调优参数。 3 使用SVM代替了CNN网络中最后的Softmax,同时用CNN输出的4096维向量进行Bounding Box回归。 4 流程前两个步骤(候选区域提取+特征提取)与待检测类别无关,可以在不同类之间共用;同时检测多类时,需要倍增的只有后两步骤(判别+精修),都是简单的线性运算,速度很快。 |
|
1 训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练边框回归器。 2 训练耗时,占用磁盘空间大:5000张图像产生几百G的特征文件。 3 速度慢: 使用GPU, VGG16模型处理一张图像需要47s。 |
| SPP net |
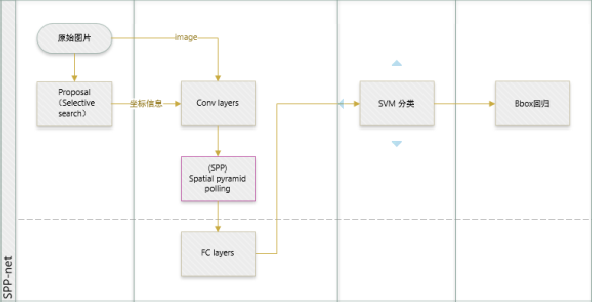

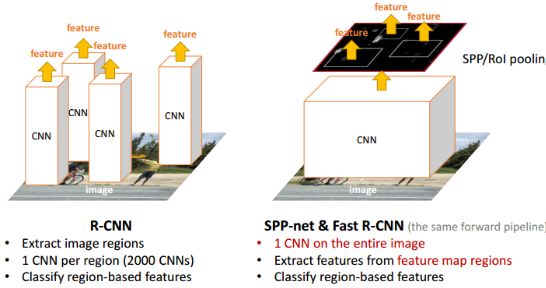
more details: http://lanbing510.info/2017/08/24/RCNN-FastRCNN-FasterRCNN.html |
1 通过Spatial Pyramid Pooling解决了深度网络固定输入层尺寸的这个限制,使得网络可以享受不限制输入尺寸带来的好处。 2 解决了RCNN速度慢的问题,不需要对每个Proposal(2000个左右)进行Wrap或Crop输入CNN提取Feature Map,只需要对整图提一次Feature Map,然后将Proposal区域映射到卷积特征层得到全链接层的输入特征。 |
|
| Fast R-CNN |
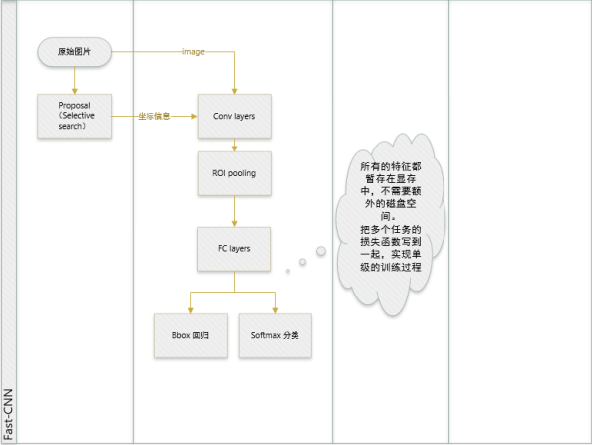
1 Fast-RCNN直接使用Softmax替代了RCNN中SVM进行分类,同时在网络中加入了多任务函数边框回归,实现了端到端的训练(除SS Region Proposal阶段)。 2 借鉴SPP-NET,提出了一个ROI层。ROI Pooling Layer实际上是SPP-NET的一个精简版,SPP-NET对每个Proposal使用了不同大小的金字塔映射,而ROI Pooling Layer只需要下采样到一个7x7的特征图。对于VGG16网络conv5_3有512个特征图,这样所有Region Proposal对应了一个7*7*512维度的特征向量作为全连接层的输入。 3 使用了不同于SPP-NET的训练方式,训练时,把同张图片的Prososals作为一批进行学习,而Proposals的坐标直接映射到conv5层上,这样相当于一张图片的所有训练样本只卷积了一次。 4 论文在回归问题上并没有用很常见的2范数作为回归,而是使用所谓的鲁棒L1范数作为损失函数。 5 论文将比较大的全链接层用SVD分解了一下使得检测的时候更加迅速。 |
|
使用Selective Search提取Region Proposals,没有实现真正意义上的端对端,操作也十分耗时。 |
| Faster R-CNN |
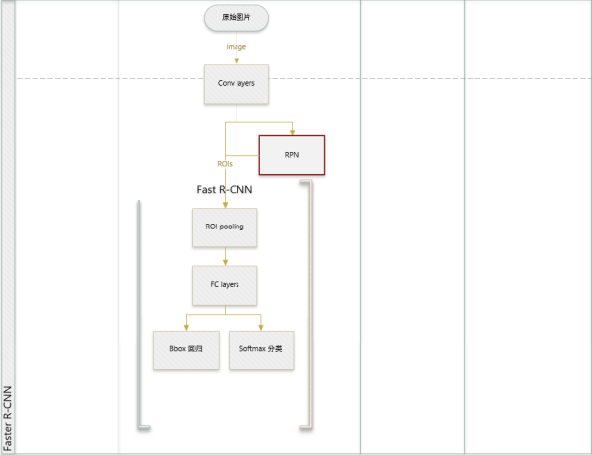
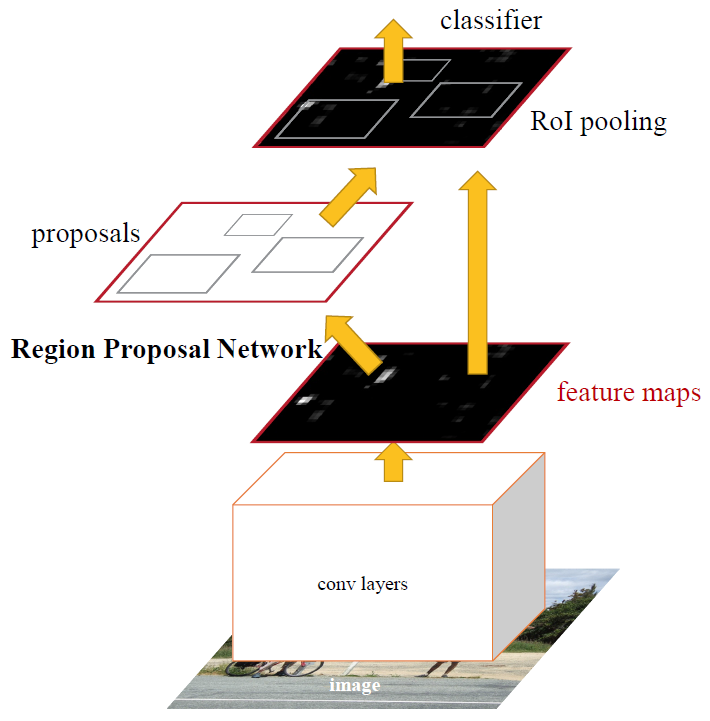 1 提出了Region Proposal Network(RPN),将Proposal阶段和CNN分类融到了一起,实现了一个完全的End-To-End的CNN目标检测模型。RPN可以快速提取高质量的Proposal,不仅加快了目标检测速度,还提高了目标检测性能。 2 将Fast-RCNN和RPN放在同一个网络结构中训练,共享网络参数。 |
虽然现在也是用的滑动窗口策略,但是,滑动窗口操作是在卷积层特征图上进行的,维度较原始图像降低了16*16倍(16如何得到的可参见前文);多尺度采用了9种Anchor,对应了三种尺度和三种长宽比,加上后边接了边框回归,所以即便是这9种Anchor外的窗口也能得到一个跟目标比较接近的Region Proposal。 |
|
| 总结 |
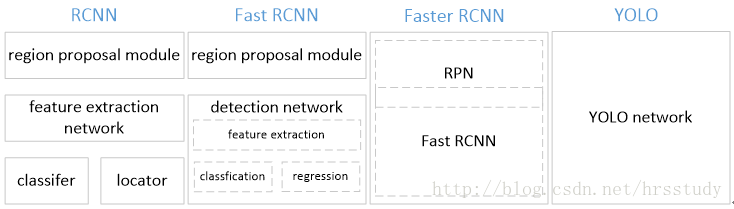
|
|
|
YOLO和SSD:
相比较于RCNN系列:利用回归的思想(既给定输入图像,直接在图像的多个位置上回归出这个位置的目标边框以及目标类别),很大的加快了检测的速度
| 模型 |
原理总结 |
优点 |
缺点 |
| YOLO |
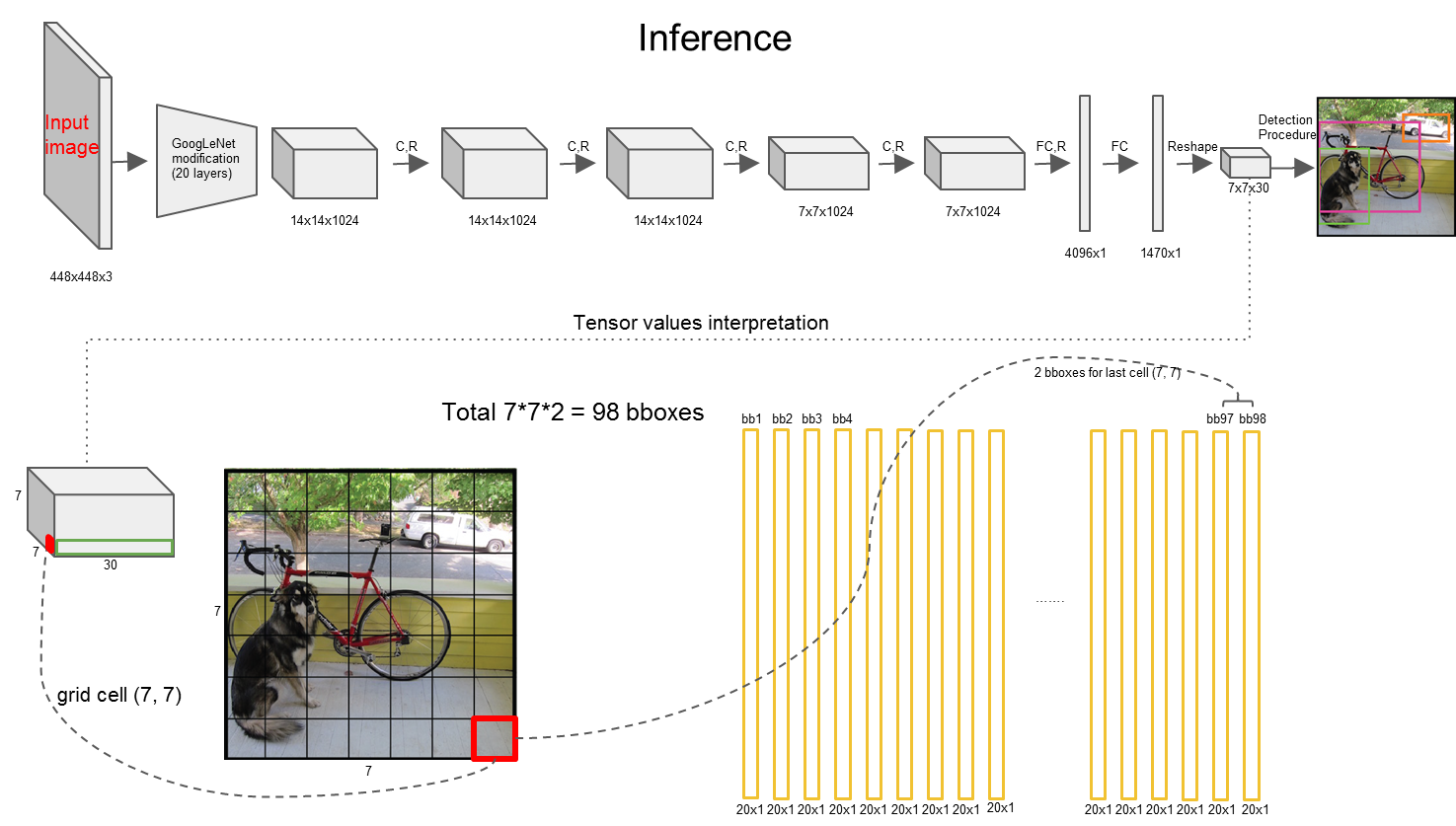

yolo :之前处理目标检测的算法都归为了分类问题,然而作者将物体检测任务当做一个regression问题来处理,使用一个神经网络,直接从一整张图像来预测出bounding box 的坐标、box中包含物体的置信度和物体的probabilities。整个检测流程都在一个网络中,实现了end-to-end来优化目标检测。 一、大致流程 1 给个一个输入图像,首先将图像划分成7*7的网格。 2 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)。 3 根据上一步可以预测出7*7*2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可。 |
版本一: 1 将物体检测作为回归问题求解。基于一个单独的End-To-End网络,完成从原始图像的输入到物体位置和类别的输出,输入图像经过一次Inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。 2 YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用Inception Module,而是使用1*1卷积层(此处1*1卷积层的存在是为了跨通道信息整合)+3*3卷积层简单替代。 3 Fast YOLO使用9个卷积层代替YOLO的24个,网络更轻快,速度从YOLO的45fps提升到155fps,但同时损失了检测准确率。 4 使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。 5 泛化能力强。在自然图像上训练好的结果在艺术作品中的依然具有很好的效果。 版本二:
- 速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
- 使用全图作为 Context 信息,可以更好地避免背景错误(背景错误不到Faster-R-CNN的一半)。
- 可以学到目标的泛化特征。
|
|
| SSD |
设计思想: ssd 在特征图上采用卷积核来预测一系列的 default bounding boxes 的类别分数、偏移量,同时实现end-to-end 的训练。 
特点:
- 从YOLO中继承了将detection转化为regression的思路,一次完成目标定位与分类
- 基于Faster RCNN中的Anchor,提出了相似的Prior box;
- 加入基于特征金字塔(Pyramidal Feature Hierarchy)的检测方式,即在不同感受野的feature map上预测目标
|
- 速度上,比yolo还要快
- 在检测精度上,可以和Faster RCNN相媲美
版本二:
- SSD最大的贡献,就是在多个feature map上进行预测,这点我在上一篇FPN也说过它的好处,可以适应更多的scale。
- 第二个是用小的卷积进行分类回归,区别于YOLO及其faster rcnn的fc,大大降低参数和提速
速度对比: 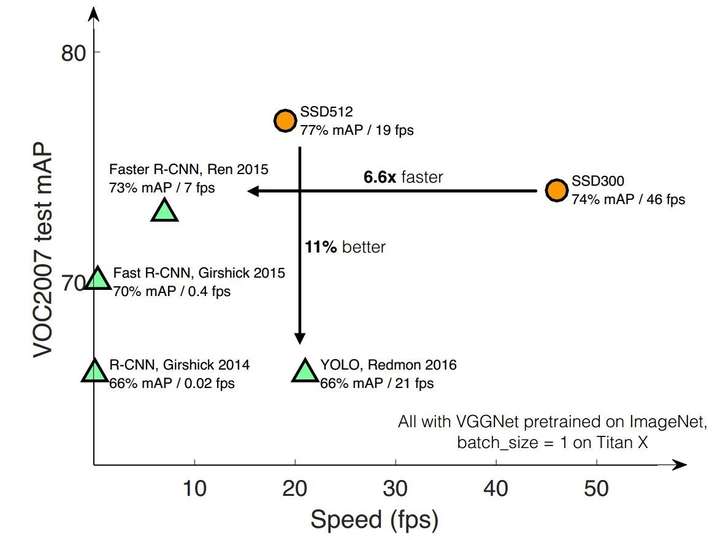
|
- 需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中prior box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的prior box大小和形状恰好都不一样,导致调试过程非常依赖经验。
- 虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。作者认为,这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
|
| YOLO V2 |
|
yolo v2 的改进的点:
- Batch Normalization 在卷基层后面增加了batch Normalization,加快了收敛速度,同时mApt提高了2%
- High Resolution Classifier 训练网络的时候将网络从224*224变为448*448,当然后续为了保证特征图中只有基数个定位位置,从而保证只有一个中心细胞,网络最终设置为416*416。最终实现了4%的mAP提升。
- Convoutional with Anchor Boxes 去掉yolo1 的全连接层,加入了anchor boxes。提高了召回率。81% 到 88%。当然 mAP 下降了0.3.(69.5-39.2)
- Dimension Clusters 提出了kmeans聚类(k =5) 这种c选择了模型复杂度和召回率。使用欧式距离进行边界框优先权的衡量,距离越小,优先权越高。
- Direction location prediction: 尤其是训练开始 模型非常不稳定。使用了logistic 激活函数,使得网络在(0-1)之间波动。
- Fine-Grained Features 使用了passthrough layer。 组合了高分辨的特征和低分辨率的特征通过融合相邻的特征到不同的通道中。
- Multi-Scale Training 不是固定好尺寸来进行训练,在训练的过程中,隔10 batches,随机地选择一种尺度来进行训练
|
|
| YOLO 9000 |
|
|
|
| YOLO V3 |
|
|
|
笔记:
Faster R-CNN