居家隔离的日子里,各类方便速食食品成了许多人的心头爱。特别是螺蛳粉,异军突起,火遍全网,几乎卖到脱销。有的螺蛳粉热销店铺的购买页面还显示,现在下单,预售40天后发货,这是种什么操作?

万万没想到,这些日子发不出货的,除了口罩,还有螺蛳粉。
今天我们就来聊一聊火遍全网的螺蛳粉。
01
让吃货们买到断货的
螺蛳粉
螺蛳粉气味腥臭,味道酸辣,被戏称为“生化武器”。然而吃起来却让人欲罢不能,再加上称为灵魂的酸笋,不禁让人大呼,爱了爱了!就是这个味儿!
那么谁家卖的螺蛳粉最火,最好吃?吃货们都怎么看?
我们搜集整理了淘宝上关于螺蛳粉店铺的数据:
店铺销量排行

可以看到:销量前三的店铺分别是李子柒旗舰店、好欢螺旗舰店、嘻螺会鼎容鲜专卖店。其中李子柒旗舰店的以月销量66万+一骑绝尘。紧随其后的是好欢螺月销量57万+。第三是嘻螺会21万+。
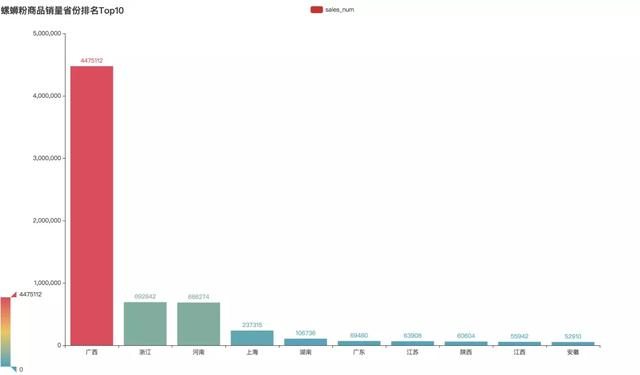
各省螺蛳粉店铺和销量排行
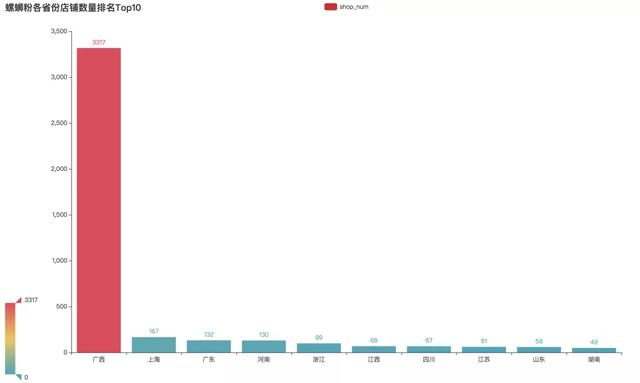
最为螺蛳粉发源地,无论是在店铺数量和商品销量上,广西地区都占据了全国的大部分比重,绝对的王者。
螺蛳粉都卖多少钱?
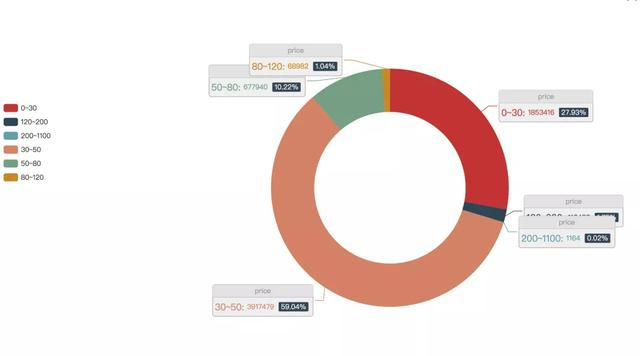
我们分析了市面上销售螺蛳粉的价格区间,发现一份螺蛳粉一般3-5包。其中定价在30-50元一份的卖得最好,占到全网总销量的59.04%。这个价格区间,普遍让人接受,3-5包的量也很合适。
其次是0-30元一份的,销量占比27.93%,这个价格不仅物美价廉,对于想尝试螺蛳粉的新手都十分友好。
然后是一份售价50-80的螺蛳粉,销量占比10.22%。这个价位一般都有5包以上,对于螺蛳粉的重度爱好者来说是不错的选择。
买螺蛳粉,大家都看重什么?
从广大螺蛳粉的评价中我们可以看到:

大家的焦点尤其在,螺蛳粉产地要“正宗”。来自“广西”,特别是螺蛳粉的发源地“柳州”。
当然有意思的是,销量最高的李子柒卖的螺蛳粉产地不在广西,而是嘉兴。可能这就是网红强大的带货力吧。
其次“包邮”也是最关键的。毕竟,为了几块钱运费跟电商卖家磨半天嘴皮子,或者毫不留情地直接pass掉不包邮的店铺,这都是我们的真实写照。
02
Python分析
李子柒的螺蛳粉 到底有多火?
接着,我们再看到全网螺蛳粉销量之王的李子柒店铺。这次我们用Python来进行分析,先看到结论:

评论时间热度图:

从数据可以看到,螺蛳粉的数据从去年12月2日开始,一直不温不火,然而从3月中下旬开始,购买和评论数量持续走高,如今这个数据还在急剧上升。
消费者关注维度占比:
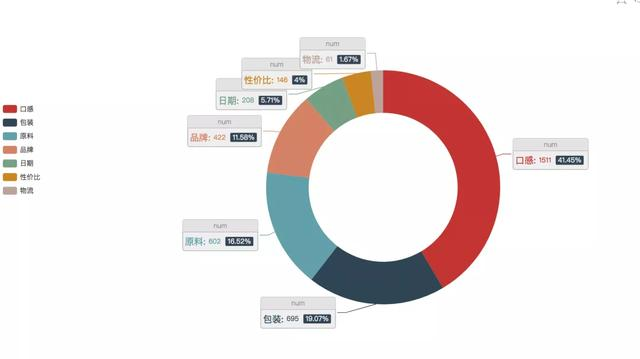
看来,螺蛳粉的口感(好不好吃)是客户最最最关注的点,占比高达41.45%,领先其他类别N个身位。
其他的维度:包装、原料、品牌,而物流和日期则提及较少,看来消费者不是太关注这些角度,或者目前基本满足要求。
关注点细节占比分布:
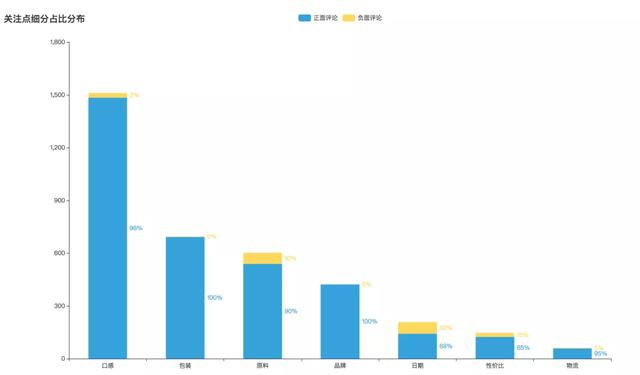
整体来看,主流评论以好评为主,其中口感、品牌(这个地方其实没有细分)、包装以正面评价占绝对主导。
原料、日期和性价比,负面评价占比分别是10%和32%和15%。
评论分布词云图:

从词云可以看到,螺蛳粉好不好吃是大家关注的焦点。“味道”“口感”“好吃”“新鲜度”等词都频频出现。
其次“李子柒”的巨大带货能力也不容小觑,毕竟很多人都是冲着李子柒小姐姐来买的。
公众号后台,回复关键字“螺蛳粉”获取完整数据。
具体步骤和代码如下:
一、导入数据和基本处理
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
# 读入数据
df = pd.read_excel('李子柒螺蛳粉评论.xlsx')
df.head()

# 去除重复值
df.drop_duplicates(inplace=True)
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1980 entries, 0 to 1979
Data columns (total 5 columns):
UserNick 1980 non-null object
comment_time 1980 non-null datetime64[ns]
content 1980 non-null object
auctionSku 1980 non-null object
comment_date 1980 non-null object
dtypes: datetime64[ns](1), object(4)
memory usage: 92.8+ KB
二、数据分析
时间-热度分析
代码:
# 时间走势图
df['comment_time'] = pd.to_datetime(df['comment_time'])
df['comment_date'] = df['comment_time'].dt.date
comment_num = df['comment_date'].value_counts().sort_index()
from pyecharts.charts import Line
from pyecharts import options as opts
# 折线图
line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))
line1.add_xaxis(comment_num.index.tolist())
line1.add_yaxis('热度', comment_num.values.tolist(),
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False))
line1.set_global_opts(title_opts=opts.TitleOpts(title='商品评价数量走势图'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate='30')),
toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts(max_=400))
line1.set_series_opts(linestyle_opts=opts.LineStyleOpts(width=3))
line1.render()
推测2019年12.02上线商品,购买和评论数量持续走高。
三、评论分析
我们从以下几个角度对评论进行分析:
def judge_comment(df, result):
# 创建一个空数据框
judges = pd.DataFrame(np.zeros(13 * len(df)).reshape(len(df),13),
columns = ['品牌','物流正面','物流负面','包装正面','包装负面','原料正面',
'原料负面','口感正面','口感负面','日期正面','日期负面',
'性价比正面','性价比负面'])
for i in range(len(result)):
word = result[i]
#李子柒的产品具有强IP属性,基本都是正面评价,这里不统计情绪,只统计提及次数
if '李子柒' in word or '子柒' in word or '小柒' in word or '李子七' in word or '小七' in word:
judges.iloc[i]['品牌'] = 1
#先判断是不是物流相关的
if '物流' in word or '快递' in word or '配送' in word or '取货' in word:
#再判断是正面还是负面情感
if '好' in word or '不错' in word or '棒' in word or '满意' in word or '迅速' in word:
judges.iloc[i]['物流正面'] = 1
elif '慢' in word or '龟速' in word or '暴力' in word or '差' in word:
judges.iloc[i]['物流负面'] = 1
#判断是否包装相关
if '包装' in word or '盒子' in word or '袋子' in word or '外观' in word:
if '高端' in word or '大气' in word or '还行' in word or '完整' in word or '好' in word or\
'严实' in word or '紧' in word or '精致' in word:
judges.iloc[i]['包装正面'] = 1
elif '破' in word or '破损' in word or '瘪' in word or '简陋' in word:
judges.iloc[i]['包装负面'] = 1
#产品
#产品原料是牛肉为主,且评价大多会提到牛肉,因此我们把这个单独拎出来分析
if '米粉' in word or '汤' in word or '配料' in word or '腐竹' in word or '花生' in word:
if '劲道' in word or '多' in word or '足' in word or '香' in word or '才' in word or\
'脆' in word or 'nice' in word:
judges.iloc[i]['原料正面'] = 1
elif '小' in word or '少' in word or '没' in word:
judges.iloc[i]['原料负面'] = 1
#口感的情绪
if '口味' in word or '味道' in word or '口感' in word or '吃起来' in word:
if '不错' in word or '浓鲜' in word or '十足' in word or '鲜' in word or\
'可以' in word or '喜欢' in word or '符合' in word:
judges.iloc[i]['口感正面'] = 1
elif '不好' in word or '不行' in word or '不鲜' in word or\
'太烂' in word:
judges.iloc[i]['口感负面'] = 1
#口感方面,有些是不需要出现前置词,消费者直接评价好吃难吃的,例如:
if '难吃' in word or '不好吃' in word:
judges.iloc[i]['口感负面'] = 1
elif '好吃' in word or '香' in word:
judges.iloc[i]['口感正面'] = 1
#日期是不是新鲜
if '日期' in word or '时间' in word or '保质期' in word:
if '新鲜' in word:
judges.iloc[i]['日期正面'] = 1
elif '久' in word or '长' in word:
judges.iloc[i]['日期负面'] = 1
elif '过期' in word:
judges.iloc[i]['日期负面'] = 1
#性价比
if '划算' in word or '便宜' in word or '赚了' in word or '囤货' in word or '超值' in word or \
'太值' in word or '物美价廉' in word or '实惠' in word or '性价比高' in word or '不贵' in word:
judges.iloc[i]['性价比正面'] = 1
elif '贵' in word or '不值' in word or '亏了' in word or '不划算' in word or '不便宜' in word:
judges.iloc[i]['性价比负面'] = 1
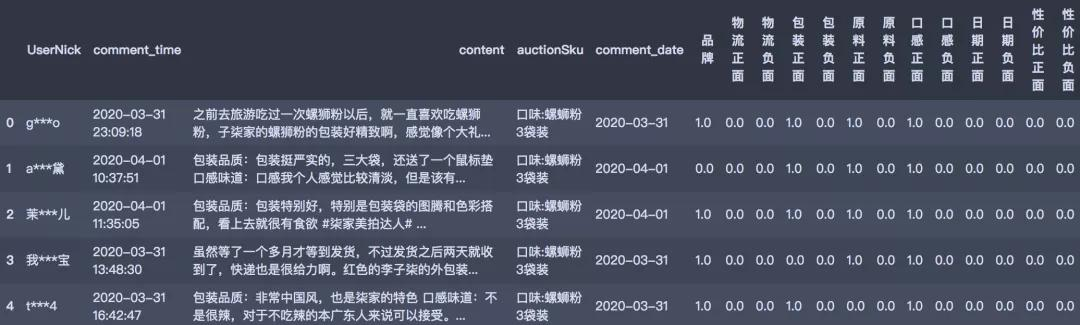
final_result = pd.concat([df,judges],axis = 1)
return final_result
# 得到数据框
judge = judge_comment(df, result=df.content)
judge.head()
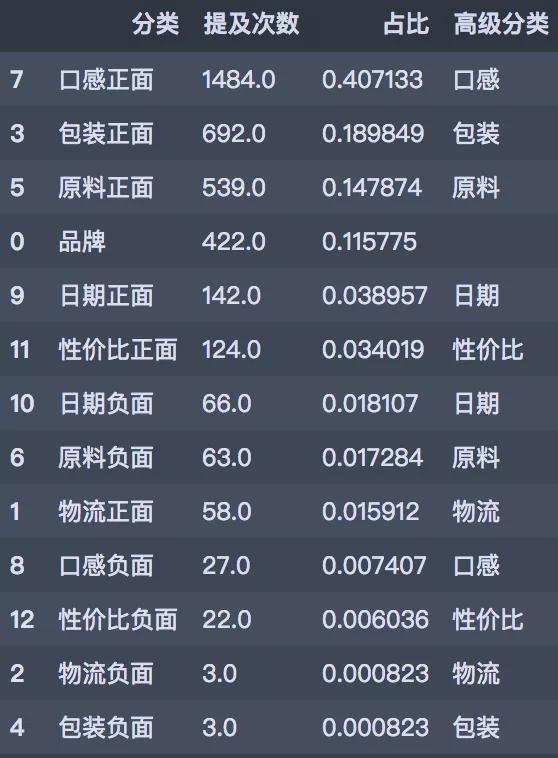
# 结果汇总
rank = judge.iloc[:, 5:].sum().reset_index().sort_values(0, ascending=False)
rank.columns = ['分类', '提及次数']
rank['占比'] = rank['提及次数'] / rank['提及次数'].sum()
rank['高级分类'] = rank['分类'].str[:-2]
rank
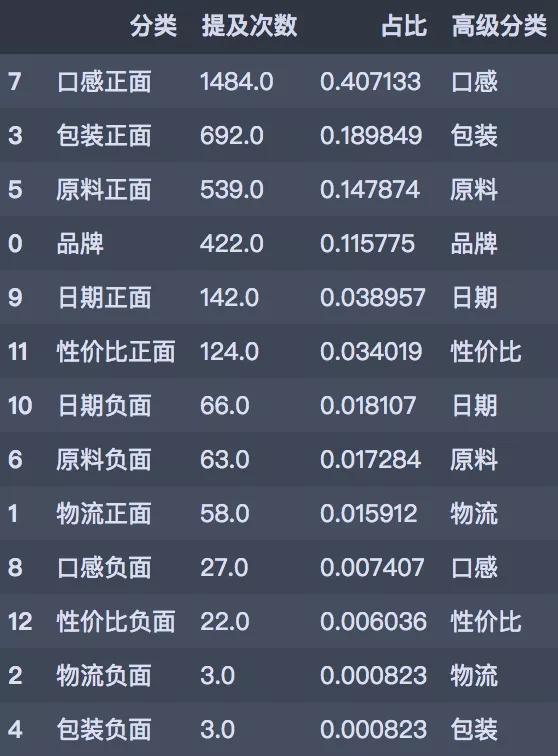
rank.loc[0, '高级分类'] = '品牌'
rank
df.shape
(1980, 5)
此次评论数据去重之后一共有1980条评论数据,粗略一看,口感和包装、原料占比较高,画个图更细致的看看。
rank_num = rank.groupby('高级分类')['提及次数'].sum().sort_values(ascending=False)
rank_num
高级分类
口感 1511.0
包装 695.0
原料 602.0
品牌 422.0
日期 208.0
性价比 146.0
物流 61.0
Name: 提及次数, dtype: float64
data_pair = [list(z) for z in zip(rank_num.index, rank_num.values)]
data_pair[['口感', 1511.0],
['包装', 695.0],
['原料', 602.0],
['品牌', 422.0],
['日期', 208.0],
['性价比', 146.0],
['物流', 61.0]]
from pyecharts.charts import Pie
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add(
series_name="num",
radius=["35%", "55%"],
data_pair=data_pair,
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
pie1.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", pos_top='30%', orient="vertical"),
toolbox_opts=opts.ToolboxOpts(),
title_opts=opts.TitleOpts(title='消费者关注占比分布'))
pie1.set_series_opts(
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)")
)
pie1.render()
看来,螺蛳粉的口感(好不好吃)是客户最最最关注的点,没有之一,占比高达41.45%,领先其他类别N个身位。
包装、原料、品牌,而物流和日期则提及较少,消费者貌似不太关注,或者说目前基本满足要求。
那不同类别正负面评价占比是怎么样的呢?
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType
list2 = [
{"value": 1484.0, "percent": 1484.0 / (1484.0 + 27.0)},
{"value": 692.0, "percent": 692.0 / (692.0 + 3.0)},
{"value": 539.0, "percent": 539.0 / (539.0 + 63.0)},
{"value": 422.0, "percent": 422.0 / (422.0 + 0)},
{"value": 142.0, "percent": 142.0 / (142.0 + 66.0)},
{"value": 124.0, "percent": 124.0 / (124.0 + 22.0)},
{"value": 58.0, "percent": 58.0 / (58.0 + 3.0)},
]
list3 = [
{"value": 27.0, "percent": 27.0 / (27.0 + 1484.0)},
{"value": 3.0, "percent": 3.0 / (3.0 + 692.0)},
{"value": 63.0, "percent": 63.0 / (63.0 + 539.0)},
{"value": 0, "percent": 0 / (0 + 422.0)},
{"value": 66.0, "percent": 66.0 / (66.0 + 142.0)},
{"value": 22.0, "percent": 22.0 / (22.0 + 124.0)},
{"value": 3.0, "percent": 3.0 / (3.0 + 58.0)},
]
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px', theme=ThemeType.LIGHT))
bar1.add_xaxis(['口感', '包装', '原料', '品牌', '日期', '性价比', '物流'])
bar1.add_yaxis("正面评论", list2, stack="stack1", category_gap="50%")
bar1.add_yaxis("负面评论", list3, stack="stack1", category_gap="50%")
bar1.set_global_opts(title_opts=opts.TitleOpts(title='关注点细分占比分布'))
bar1.set_series_opts(
label_opts=opts.LabelOpts(
position="right",
formatter=JsCode(
"function(x){return Number(x.data.percent * 100).toFixed() + '%';}"
),
)
)
bar1.render()
import jieba
import jieba.analyse
txt = df['content'].str.cat(sep='。')
# 添加关键词
jieba.add_word('李子柒')
# 读入停用词表
stop_words = []
with open('stop_words.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加停用词
stop_words.extend(['40', 'hellip', '一袋', '一包', '一个月',
'一点', '一个多月', '第一次', '哈哈哈',
'螺狮粉', '螺蛳'])
# 评论字段分词处理
word_num = jieba.analyse.extract_tags(txt,
topK=100,
withWeight=True,
allowPOS=())
# 去停用词
word_num_selected = []
for i in word_num:
if i[0] not in stop_words:
word_num_selected.append(i)
key_words = pd.DataFrame(word_num_selected, columns=['words','num'])
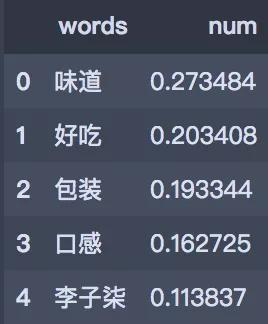
key_words.head()
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
# 词云图
word1 = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))
word1.add("", [*zip(key_words.words, key_words.num)],
word_size_range=[20, 200],
shape=SymbolType.DIAMOND)
word1.set_global_opts(title_opts=opts.TitleOpts('评论分布词云图'),
toolbox_opts=opts.ToolboxOpts())
word1.render()
from pyecharts.charts import Page
page = Page()
page.add(pie1, bar1, word1)
page.render('评论分析.html')
以上就是关于螺蛳粉的全部分析内容啦。 要问为什么螺蛳粉这么臭,还有这么多人爱呢?
其实对吃货们而言,喜欢的就是螺蛳粉又腥又臭又辣的味道,等疫情过去,螺蛳粉店估计也要爆满了。
想要获取源码的童鞋加群:850591259