该文章已更新到语雀中,后台回复“语雀”可获取进击吧大数据整个职业生涯持续更新的所有资料
该文基于Hive专题-从SQL聊Hive底层执行原理进一步的深入学习Hive,相信大多数童鞋对于Hive底层的执行流程只是局限于理论层面。那么本篇将带大家花半个小时左右的时间在自己的机器上实现Hive源码的追踪。通过本篇,你将可以学习到:
1、各个组件的安装部署
2、解决问题思路能力
3、自己动手实现本地调试Hive源码,即本地提交sql更加贴切追溯底层流程
网上也有很多类似的实现文章,但大多数比较零散。本篇将带你从零到1完整的实现该功能。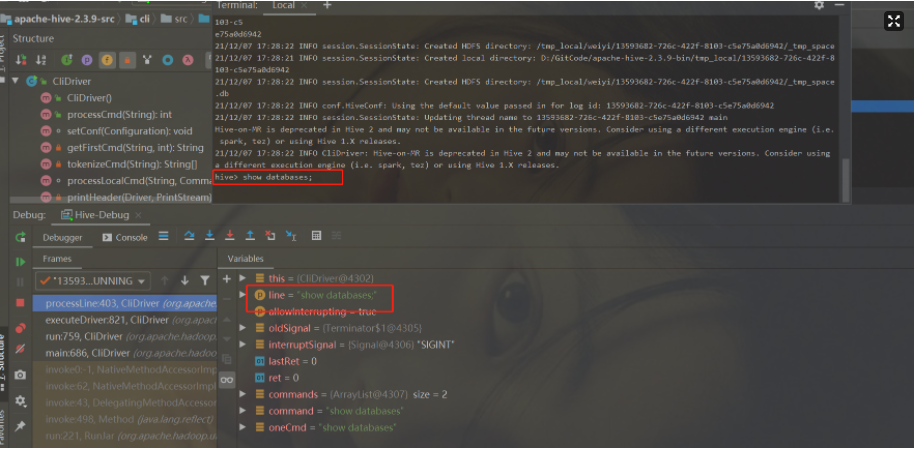 注意:本篇涉及到所有基础软件包以及执行文件均已上传到语雀文档中且本篇****基于Windows整理
注意:本篇涉及到所有基础软件包以及执行文件均已上传到语雀文档中且本篇****基于Windows整理
环境准备
一、Maven安装
1.1、下载软件包并解压缩
该软件包已经上传到语雀文档中,有需要的童鞋可以在后台回复"语雀"领取,如密码失效,请联系小编
1.2、配置环境变量

1.3、配置maven镜像
打开$MAVEN_HOME/conf/settings.xml文件,调整maven仓库地址以及镜像地址
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository>你自己的路径</localRepository>
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
</settings>
二、cywin安装
该软件安装主要是为了支持windows编译源码涉及到的基础环境包
2.1、下载软件包
该软件包已经上传到语雀文档中,有需要的童鞋可以在后台回复"语雀"领取,如密码失效,请联系小编
2.2、在线安装相关软件包
需要安装cywin,gcc+相关的编译包
binutils
gcc
gcc-mingw
gdb
三、JDK安装
3.1、下载软件包并解压缩
该软件包已经上传到语雀文档中,有需要的童鞋可以在后台回复"语雀"领取,如密码失效,请联系小编
3.2、配置环境变量
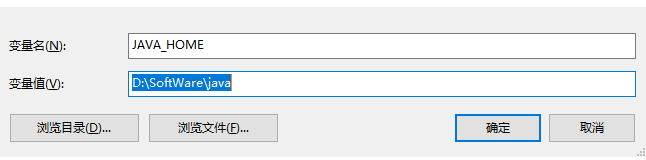
3.2.1、创建JAVA_HOME系统变量
 3.2.2、创建CLASSPATH变量
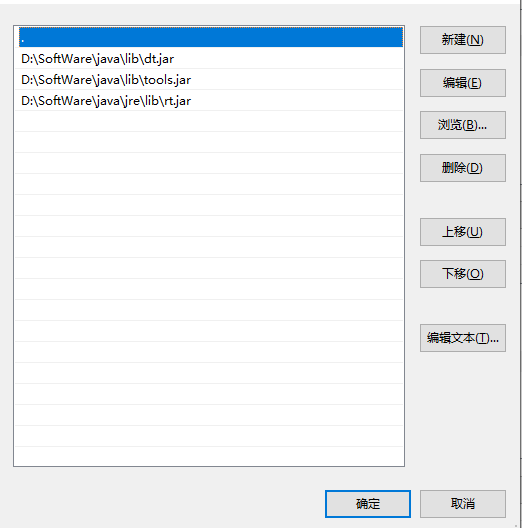
3.2.2、创建CLASSPATH变量
 3.2.3、Path变量追加
3.2.3、Path变量追加
四、Hadoop安装
4.1、下载软件包并解压缩
该软件包已经上传到语雀文档中,有需要的童鞋可以在后台回复"语雀"领取,如密码失效,请联系小编
4.2、配置环境变量
创建HADOOP_HOME系统变量,然后将该变量追加到Path全局变量中
4.3、编辑配置文件
注意:下载的软件包中可能不包含下列的文件,但提供了template文件,直接重命名即可。由于该篇是属于学习自用,所以只需要配置基础核心信息即可。下列文件位于$HADOOP_HOME/etc/hadoop目录下。
4.3.1、修改core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
4.3.2、修改yarn-site.xml文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
4.3.3、修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.4、依赖文件
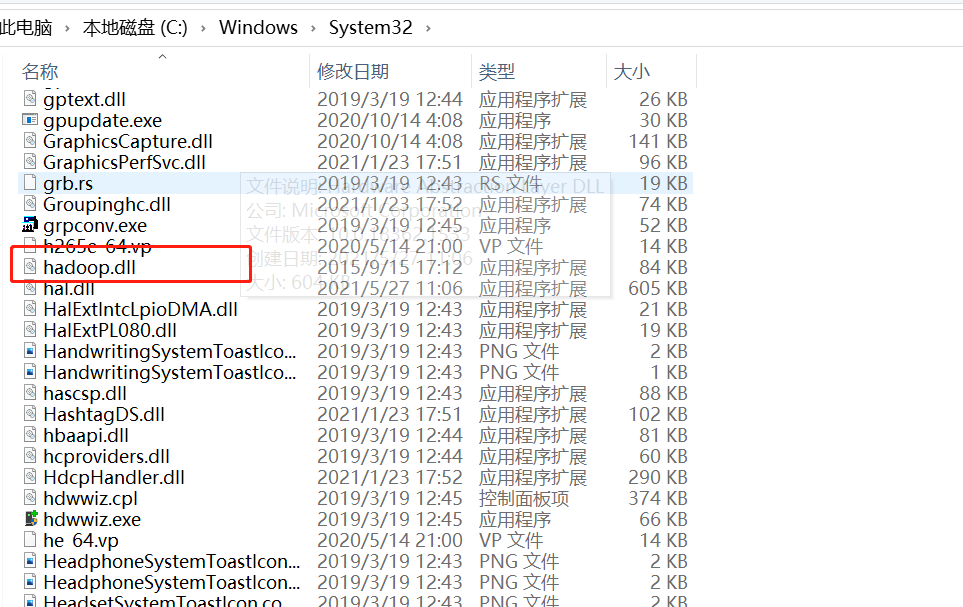
在Windows环境下启动Hadoop,需要专门的二进制文件和依赖库,即winutils支持和hadoop.dll等文件。需要把该文件放到HADOOP_HOME/bin目录下,同时可以将hadoop.dll放到C:\Windows\System32下一份避免出现依赖性错误。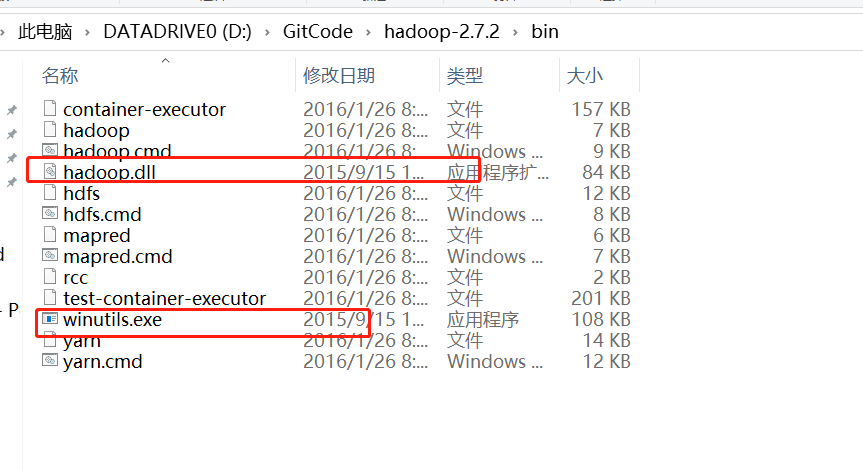
4.5、初始化启动
以下命令在cmd命令行中,跳转到HADOOP_HOME/bin目录下和HADOOP_HOME/sbin目录下执行
# 首先初始化namenode,打开cmd执行下面的命令
$HADOOP_HOME/bin> hadoop namenode -format
# 当初始化完成后,启动hadoop
$HADOOP_HOME/sbin> start-all.cmd
 当以下进程都启动成功后,hadoop基本环境也算是搭建成功了!
当以下进程都启动成功后,hadoop基本环境也算是搭建成功了!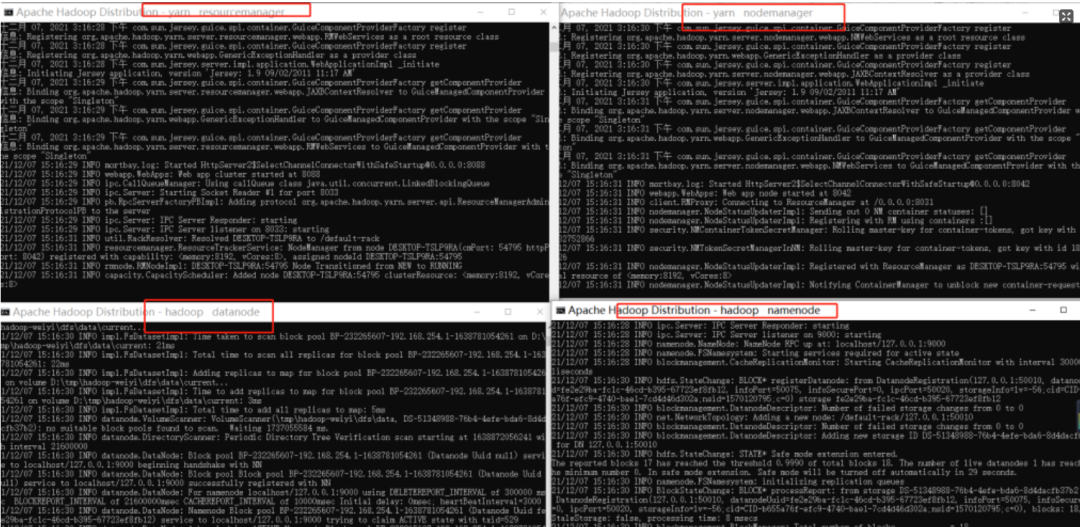
五、Mysql安装
5.1、下载软件包并解压缩
该软件包已经上传到语雀文档中,有需要的童鞋可以在后台回复"语雀"领取,如密码失效,请联系小编
5.2、配置环境变量
5.2.1、创建MYSQL_HOME变量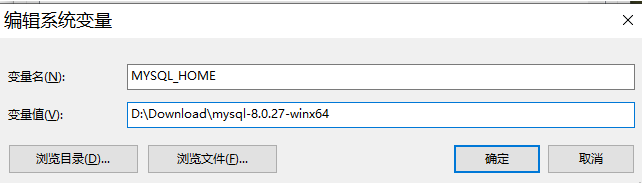 5.2.2、将MYSQL_HOME变量追加到Path变量中
5.2.2、将MYSQL_HOME变量追加到Path变量中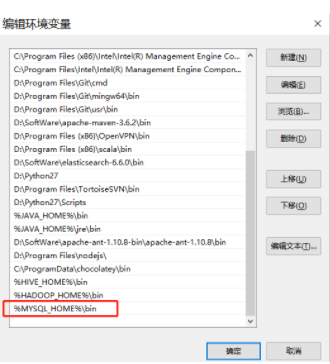
5.3、生成Data文件
使用系统管理员打开CMD窗口
--执行下面命令
mysqld --initialize-insecure --user=mysql
5.4、安装Mysql并启动
--执行命令
mysqld -install
--启动服务
net start MySQL
5.5、密码修改
--初始登录时不需要密码,直接回车即可
mysql -u root -p
--修改root默认密码
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
--刷新提交
flush privileges;
六、Hive编译安装
如果你想要深入学习Hive底层,那么源码编译是必不可少的,所以本篇将采用源码包编译安装的方式。
6.1、下载软件包并解压缩
该软件包已经上传到语雀文档中,有需要的童鞋可以在后台回复"语雀"领取,如密码失效,请联系小编
6.2、编译
在IDEA下执行如下命令:
mvn clean package -Phadoop-2 -DskipTests -Pdist
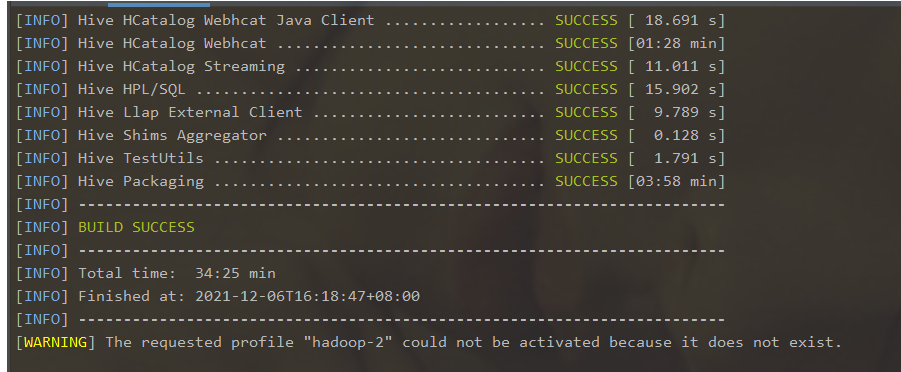 当编译结果如上图所示,则表示编译成功,可以进入下一步。
当编译结果如上图所示,则表示编译成功,可以进入下一步。
注意:在编译的过程中遇到问题的可能性非常大,大部分是因为maven,可能是网络问题,也可能跟你的镜像配置也有关系。另外对于一些模块编译过程中出现Could not transfer artifact XXXX的问题,可以先把pom文件中的scope设置注释掉!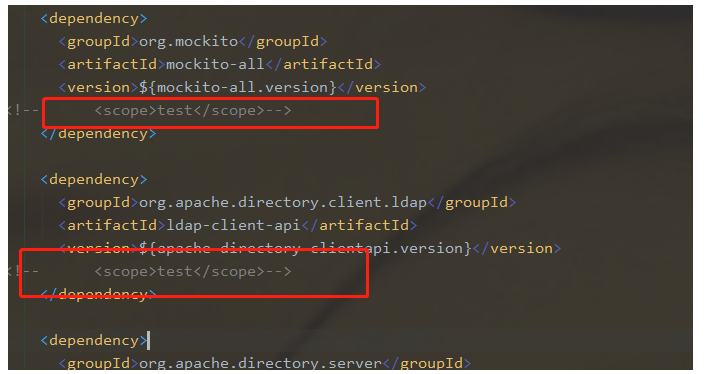
6.3、安装
编译完成后,可以在$HIVE_SRC_HOME/packaging/target目录下找到对应的可执行的压缩包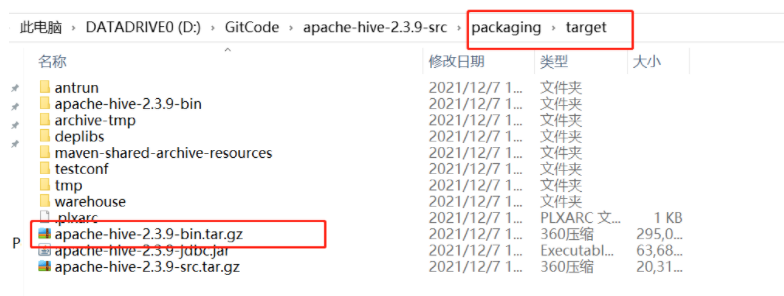 6.3.1、配置环境变量
6.3.1、配置环境变量
创建HIVE_HOME系统变量,然后将该变量追加引用到Path变量中 6.3.2、编辑hive-env.sh文件
6.3.2、编辑hive-env.sh文件
# 配置环境信息
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=D:\GitCode\hadoop-2.7.2
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=D:\GitCode\apache-hive-2.3.9-bin\conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=D:\GitCode\apache-hive-2.3.9-bin\lib
6.3.3、编辑hive-site.xml文件
该文件中的参数稍微有些多,不过我们只改动基础的部分即可。
<property>
<name>hive.repl.rootdir</name>
<value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value>
</property>
<property>
<name>hive.repl.cmrootdir</name>
<value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local\${hive.session.id}_resources</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
6.3.3、log文件重命名
将conf文件中的几个Log文件后缀带有template移除即可 6.3.4、驱动包加载
6.3.4、驱动包加载
本文使用mysql作为元数据存储,因此需要将JDBC的驱动包放到$HIVE_HOME/lib目录下
6.4、元数据初始化
在windows环境下,$HIVE_HOME/bin目录下并未找到cmd结尾的可执行文件,因此为了调通基础环境,可以从低版本中进行拷贝。本文涉及到的脚本和软件包都打包上传到云盘中
# 打开cmd命令行
$HIVE_HOME/bin> hive schematool -dbType mysql -initSchema --verbose
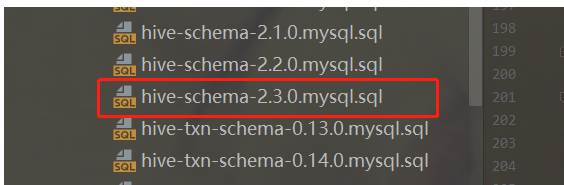
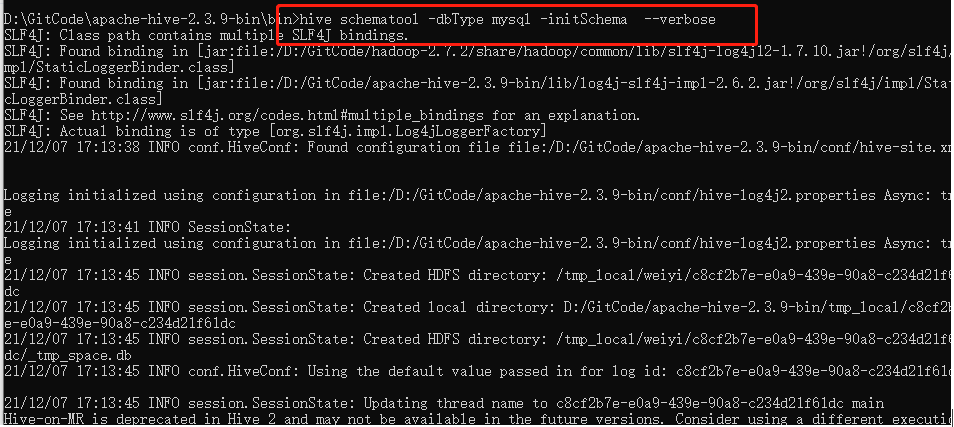 注意:在初始化过程中,可能会有表无法创建的问题,这里手动创建即可。或者直接source sql文件。本篇文章使用的是hive-shceam-2.3.0.mysql.sql,SQL文件位置于HIVE_HOME/scripts/metastore/upgrade/mysql下:
注意:在初始化过程中,可能会有表无法创建的问题,这里手动创建即可。或者直接source sql文件。本篇文章使用的是hive-shceam-2.3.0.mysql.sql,SQL文件位置于HIVE_HOME/scripts/metastore/upgrade/mysql下: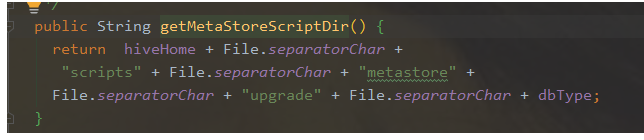
服务启动调试
在搭建Hadoop的环节中,已经将Hadoop服务启动了,这里将Hive Metastore服务启动
hive --service metastore
2.1、服务端启动Debug模式
为了方便学习,大家可以在IDEA中打开Terminal,开启debug模式和metastore服务启动。
hive --debug
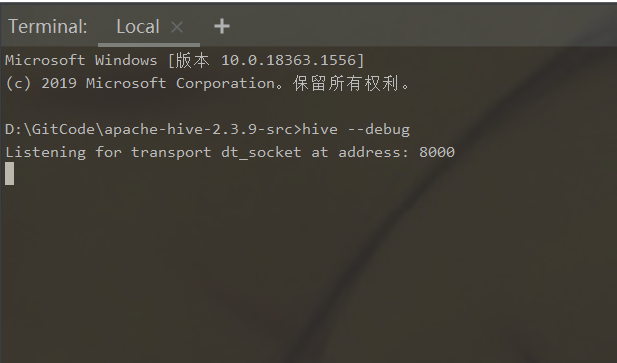
2.2、客户端断点模式
2.2.1、配置remote debug
在IDEA中配置Remote DeBug信息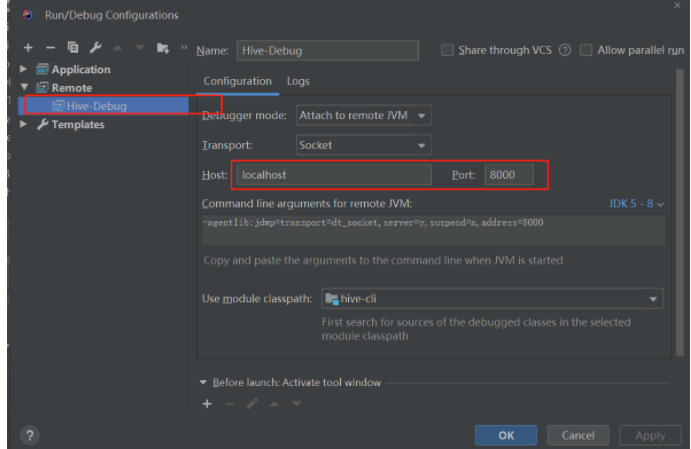 2.2.2、断点标识
2.2.2、断点标识
本文是在客户端进行源码追溯,所以一般会进入CliDriver类中,比如在main方法中打上断点,然后开始Debug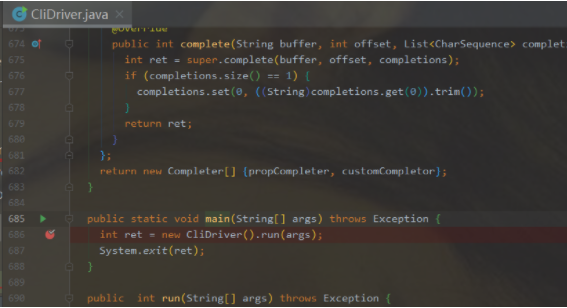
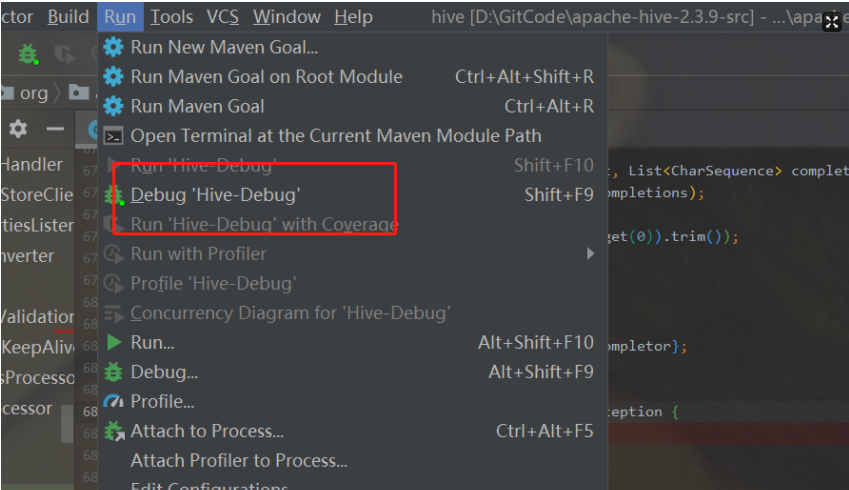
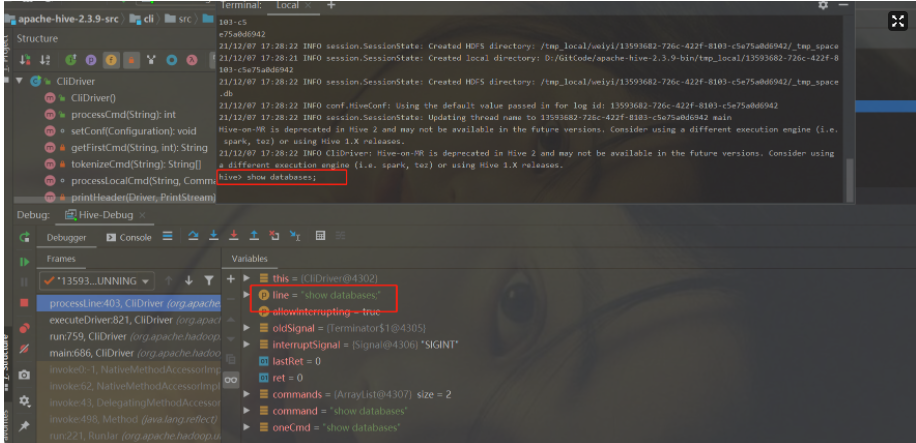 到这里,整个调试功能就已经实现了,大家可以在本地编写HSQL,然后根据断点深入学习Hive底层具体的执行流程,甚至自己改造源码!
到这里,整个调试功能就已经实现了,大家可以在本地编写HSQL,然后根据断点深入学习Hive底层具体的执行流程,甚至自己改造源码!