一、样本选择偏差与自选择偏差
样本选择偏差
样本选择偏差的非随机选择机制在于对样本的选择不随机。在样本数据的采集过程中,只对某部分群体进行调查,但这部分群体与其他群体在某些方面的特征差异较大,因此根据这样的样本做回归得到的普适性结论并不可信。体现在具体的数据集中就是,数据集中只有特定群体的样本,或者,虽然有全部群体的所有解释变量数据,但除特定群体之外的其他群体的被解释变量数据缺失,在这两种情况下进行的回归,都将直接忽视其他群体的样本信息(y缺失的样本在参与回归时将被drop掉)。实质上,样本选择偏差说的就是参与回归的样本不能代表总体从而产生估计偏误的问题。
自选择偏差
自选择偏差的非随机选择机制在于对自变量的选择不随机。在使用DID方法评估政策效应时,一个明显的事实就是,相对于未实施政策的地区(控制组),实施政策的地区(处理组)通常情况下经济发展都较为发达、各类基础设施建设都较为完善,而所谓的“政策效果评估”也即考察政策的经济效应,因此地区是否参与政策这一行为是内生的。体现在回归方程中就是,经济指标(如,GDP、人均GDP、GDP增长率等)作为被解释变量y,地区(在某时点)是否实施该项政策的哑元变量D作为核心解释变量,但由于政策内生,因此某些影响地区是否参与决策D的(可观测或不可观测)因素也将同时影响经济指标y,由于这些因素或者无法穷尽、或者影响形式未知、或者不可测度,因此被放到随机扰动项中,造成解释变量D与扰动项ε相关。实质上,自选择偏差说的就是实验组与控制组的先验条件存在较大差异从而导致估计偏误的问题。
区别
在具体回归方程中就是,样本选择偏差中被解释变量y是否被观测到或是否取值(而非取值大小)是非随机的;而自选择偏差中哑元解释变量D的取值是非随机的。陈强(2014)《高级计量经济学及Stata应用(第二版)》第539页认为,样本选择问题通常不考虑某项目或政策的效应,故个体间的差异并不在于是否得到处理,而在于是否能进入样本(即被解释变量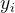 是否可观测),通常
是否可观测),通常 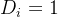 意味着 可观测,而
意味着 可观测,而 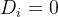 则意味着 不可观测。而在处理效应模型中,无论 或 ,结果变量 均可观测。这种说法基本概括了两者的区别,但有一个小问题,在样本选择偏差中,
则意味着 不可观测。而在处理效应模型中,无论 或 ,结果变量 均可观测。这种说法基本概括了两者的区别,但有一个小问题,在样本选择偏差中,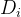 的取值与 是否可观测并不存在必然的关系,因为 是一个确定并可准确测度的因素,而影响 是否可观测的却是一个不可观测的潜变量,这个潜变量由一系列控制变量与外生变量决定。
的取值与 是否可观测并不存在必然的关系,因为 是一个确定并可准确测度的因素,而影响 是否可观测的却是一个不可观测的潜变量,这个潜变量由一系列控制变量与外生变量决定。
二、两个模型的估计思路
2.1 样本选择模型
对于样本选择偏差导致的估计偏误,将使用样本选择模型(Sample Selection Model)来缓解。样本选择偏差与样本选择模型(或称Heckman两步估计法、Heckit)由诺贝尔经济学奖获得者Heckman教授于1979年提出。
本质上,样本选择偏差其实是一个因遗漏变量而导致内生性的特例(具体推导请看任意一本高级计量经济学教材,如陈强(2014)《高级计量经济学及Stata应用(第二版)》第234页、Hansen(2021)《ECONOMETRICS(Version 2021)》第852页等)。
回归方程中被遗漏的变量叫做逆米尔斯比率(Inverse Mill’s Ratio,IMR或 λ \lambda λ),也被称为风险函数(Hazard Function),计算公式为:

其中, 为第 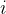 个样本在第一步回归(选择方程)的拟合值,
个样本在第一步回归(选择方程)的拟合值,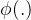 为标准正态的概率密度函数(Probability Density Function,pdf), Φ (⋅) 为累积分布函数(Cumulative Distribution Function,cdf)。
为标准正态的概率密度函数(Probability Density Function,pdf), Φ (⋅) 为累积分布函数(Cumulative Distribution Function,cdf)。
因此,样本选择模型的估计思路是:首先,计算全部样本的IMR;随后将遗漏变量IMR代入原回归方程中,具体来说:
第一步 :用 probit 方法估计选择方程,其中原回归方程的被解释变量 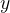 是否被观测到或是否取值的虚拟变量_dummy 作为 probit 的被解释变量,解释变量包括原回归方程所有解释变量和至少一个外生变量,该外生变量只影响y是否取值,而不影响y的大小,即满足相关性和外生性的要求(但不是工具变量)。估计出所有变量的系数后,将样本数据代入至 probit 模型中,计算出拟合值
是否被观测到或是否取值的虚拟变量_dummy 作为 probit 的被解释变量,解释变量包括原回归方程所有解释变量和至少一个外生变量,该外生变量只影响y是否取值,而不影响y的大小,即满足相关性和外生性的要求(但不是工具变量)。估计出所有变量的系数后,将样本数据代入至 probit 模型中,计算出拟合值 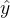 ,再将 代入风险函数中计算出 IMR 。这里有四点需要注意:
,再将 代入风险函数中计算出 IMR 。这里有四点需要注意:
1. 选择方程的被解释变量是原回归方程中被解释变量 是否被观测到或是否取值的虚拟变量,即_dummy,当 取值不为空(包括取值为0)时,_dummy等于1,只有当 _dummy取值为空(missing)时,_dummy才等于0。关于这一点,现实应用中存在的问题是,即便我们十分清楚存在样本选择偏差,但由于前期数据搜集过程中直接忽视了 取值为空的样本,因此无法采用样本选择模型,因为样本选择模型第一步选择方程使用的是所有样本,包括 取值为空的样本和取值不为空的样本。由于数据搜集过程存在问题,因此许多文献使用的所谓Heckman两步法实际上是一种“伪样本选择模型”,与Heckman(1979)提出的两步估计法(Two-Step Estimation,或Heckit)完全不同,而且也不是下文将要介绍的处理效应模型。
2. 选择方程的被解释变量只能是原回归方程中被解释变量 是否被观测到或是否取值的虚拟变量,而不能是其他变量,更不能是解释变量是否取值的虚拟变量。如果第一步回归的被解释变量是原回归中解释变量是否取值的虚拟变量,那么该模型就不再是样本选择模型了,而变成了下文将要介绍的处理效应模型,关于这一点,实际应用中经常被搞混。
3. 第一步选择方程的解释变量必须要包括原回归中所有解释变量和至少一个外生变量,也就是说,原回归的解释变量是选择方程解释变量的真子集。如果只使用原回归中一部分的解释变量或不引入外生变量,那么就不能确保IMR与原回归的随机干扰项不相关,从而造成估计系数依然存在偏误。实际应用中,多数文献并未引入外生变量,部分文献甚至没有汇报第一步选择方程中的解释变量,这样的做法十分不推荐。此外,论文中如果引入了外生变量,就需要对相关性与外生性进行具体说明,其中相关性不能只从外生变量的回归系数显著这一个方面进行说明,还要从其他文献和从理论上进行分析;外生性的说明与之类似。
4. 第一步选择方程只能使用probit模型进行回归,不能使用logit模型。在选择方程中,假设扰动项服从正态分布,从而可以推导出将IMR代入原回归方程可以缓解样本选择偏差问题,因此对于被解释变量为0-1型的虚拟变量,只能使用probit模型而不能使用logit模型,因为logit模型不具有扰动项服从正态分布的假设。但问题是,probit假设时间效应和个体效应与扰动项不相关,即第一步选择方程中只能使用随机效应模型,不能使用更一般化的固定效应模型。实际应用中,多数文献在汇报第一阶段回归结果时,在末尾加上“时间固定效应 - Yes”、“个体固定效应 - Yes”等,这样的做法是有待商榷的,因为这根本就不是固定效应模型。
第二步 :将第一步回归计算得到的 IMR 作为控制变量引入原回归方程中。如果IMR显著,说明原回归中存在样本选择偏差,需要使用样本选择模型进行缓解,而其余变量的回归系数则是缓解样本选择偏差后更为稳健的结果;如果IMR不显著,说明原回归存在的样本选择偏差问题不是很严重,不需要使用样本选择模型,当然,使用了也没关系,因为引入控制变量的回归结果可以与原回归结果比较,作为一种形式的稳健性检验。这里有两点需要注意:
1. 两步估计法中第二步回归代入的是第一步回归的结果,因此第一步回归的估计误差也将被代入第二步,造成效率损失,最终导致第二步估计系数的标准误存在偏差,影响p值进而影响系数显著性。解决方法有两种:一是对第二步回归的标准误进行校正处理,但标准误的校正方法相对复杂,因此现阶段采用这种解决方案的文献几乎没有;二是使用极大似然估计(Maximum Likelihood Estimate,MLE),直接对两阶段回归进行整体估计,这种方法在实际应用中使用较多,但存在的问题在于如果样本量太大,计算会非常耗时。因此,考虑到操作的简便性、理解的直观性以及对分布的假设更为宽松,目前国内流行使用的还是两步估计法。
2. 第二步回归使用的样本数目少于第一步。假设所有的解释变量(包括第一步的外生变量)都没有缺失值,仅被解释变量 y 存在缺失值,那么第一步回归中使用的样本数目是全样本,因为第一步选择方程的被解释变量y_dummy设置为当 y 取值不为空(包括y取值为0)时 y_dummy 等于1,y取值为空时 y_dummy 等于0,故所有样本的 y_dummy 都有取值,因此都参与了第一步回归。而第二步回归中的被解释变量y存在缺失值,存在缺失值的样本在参与回归时将直接被剔除。因此第二步回归使用的样本数目少于第一步,这也是样本选择模型一个最直观的特征,这与下文介绍的处理效应模型形成比较。
2.2 处理效应模型
对于自选择偏差导致的估计偏误,将使用处理效应模型(Treatment Effects Model)来缓解,该模型由Maddala(1983)提出。
事实上,使用处理效应模型也只是一定程度上缓解自选择偏差问题。决定个体是否参与实验的因素可以分为两种:
1. 可观测因素,如果个体参与实验的决策依赖于可观测因素,就说明该个体的决策依可测变量选择。
2. 不可观测因素,如果个体参与实验的决策依赖于不可观测因素,就说明该个体的决策依不可测变量选择。
相应地,解决自选择偏差问题的方法也大致可以分为两类:
1. 解决依可测变量选择问题的方法如上期介绍的PSM,通过控制处理组与控制组协变量的取值大致相等,从而达到变量选择近似随机的目的。
2. 解决依不可测变量选择问题的方法包括PSM - DID方法、断点回归方法(RDD)以及这里的处理效应模型等。需要注意的是,单纯的PSM只能解决依可测变量选择的内生问题,而将PSM和DID结合(即PSM - DID)就可以缓解一部分由不可观测因素带来的自选择偏差问题。
处理效应模型的构建基于Heckman两步法的思想,但与Heckman两步法或者样本选择模型有着本质上的区别,最明显的区别在于,样本选择模型第一阶段回归的被解释变量是第二阶段被解释变量 是否取值的虚拟变量_dummy,并且_dummy不参与第二阶段回归;而处理效应模型第一阶段回归的被解释变量是第二阶段的核心解释变量D,并且D的取值为0或1,不存在缺失值。
同样,自选择偏差本质上也是一个因遗漏变量而导致的内生性问题,被遗漏的变量也是IMR,但其计算公式与样本选择偏差存在区别。具体而言,存在自选择偏差的回归方程中被遗漏的IMR计算公式为:
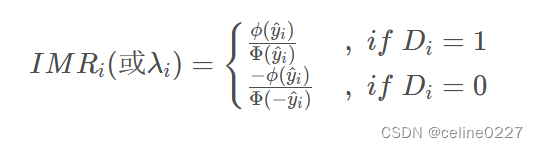
明显可以看到,在处理效应模型中,D取值为1的样本与D取值为0的样本的 IMR 计算公式不同,而且由于处理效应模型第二阶段回归中所有样本均参与了回归,因此如果混用了计量模型将直接导致变量 IMR 的取值错误,进而影响第二步回归的估计结果。
同样,处理效应模型的估计思路是:首先,计算全部样本的IMR;随后,将遗漏变量 IMR 代入原回归方程中,具体来说
第一步 :使用 probit 模型估计选择方程,其中选择方程的被解释变量是第二步回归中的核心解释变量D,该解释变量为虚拟变量且不存在缺失值;选择方程的解释变量包括由第二阶段回归中所有解释变量组成的控制变量集以及一个或多个外生变量组成的工具变量集 Z,这里之所以直接说 Z 是工具变量,是因为要求 Z 满足相关性与外生性,而相关性说的是 Z 与原回归方程中的解释变量 D 相关,而非样本选择模型中的要求外生变量与 y_dummy 相关。同样,回归模型只能使用probit方法,此外也不能使用固定效应模型,在汇报时只能说是“个体效应 - Yes”或“时间效应 - Yes”。
需要注意的是,选择方程中的工具变量应尽量避免使用D的滞后项D_lag,原因在于如果是普通DID,对于所有处理组来说政策实施时点都是一致的,那么在第一步回归中,D_lag会因为多重共线性而被omitted;如果是多期DID,尽管政策实施时点不固定,但总共的实施时点必然不会过多,D_lag同样也会因为多重共线性而被omitted。而对于非DID的D而言,滞后项D_lag则有可能作为一个良好的工具变量。
第二步 :将样本数据代入第一步选择方程中,得到各个样本的的拟合值 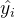 ,再将 代入处理效应模型的风险函数,计算得到各样本的 IMR,最后将 IMR 作为额外的控制变量引入原回归方程中,考察核心解释变量 D 以及 IMR 的估计系数。如果 IMR的估计系数显著,说明自选择偏差问题不可忽视,此时核心解释变量D的系数就是考虑了自选择偏差后的估计结果,并可与基准回归结果对比构成稳健性检验;而如果IMR的估计系数不显著,则说明自选择偏差问题在原回归中不明显,基准回归结果本身就是可信的。
,再将 代入处理效应模型的风险函数,计算得到各样本的 IMR,最后将 IMR 作为额外的控制变量引入原回归方程中,考察核心解释变量 D 以及 IMR 的估计系数。如果 IMR的估计系数显著,说明自选择偏差问题不可忽视,此时核心解释变量D的系数就是考虑了自选择偏差后的估计结果,并可与基准回归结果对比构成稳健性检验;而如果IMR的估计系数不显著,则说明自选择偏差问题在原回归中不明显,基准回归结果本身就是可信的。
需要注意的是,核心解释变量D在两步模型中均参与了回归,其中第一阶段回归中D作为被解释变量,在第二阶段回归中作为解释变量,并且我们假设D不存在缺失值,因此处理效应模型两步回归中的样本均是全样本,这不同于样本选择模型。
2.3 估计思路的对比
总结一下样本选择模型和处理效应模型的估计思路的异同点。
相同点在于:
1. 都是两步估计法。Heckman于1979年提出的两步估计法最开始是用于解决样本选择偏差的,即最初的Heckman两步法指的就是样本选择模型,后来有学者借鉴这种两步估计法的思想,应用于解决自选择偏差的处理效应模型。这两个模型在估计思路上是一脉相承的,而正是因为这种相似性,所以才导致各个学者对这两个模型的错误理解与错误应用,这种错误在现阶段的文献中较为常见。
2. 都可以使用MLE进行模型的整体估计。两步估计法(如2SLS、PSM - DID以及这里的样本选择模型和处理效应模型等)一个明显的缺陷是,第一步估计的误差将被带入第二步,导致效率损失。而使用MLE从整体上进行参数估计可以避免这种问题,但如果样本量过大,MLE估计耗时较长,且MLE对分布的假设较为严格,因此需要在估计的精准性、操作的简便性等方面进行权衡。
3. 第一阶段回归都需要引入外生变量,同时应包括第二阶段的所有外生解释变量。引入的外生变量需满足相关性和外生性的要求,即与选择方程中的被解释变量在理论上和统计上均具有相关性,而与第二步回归的被解释变量不具有直接的相关关系。引入外生变量的目的是确保第一步计算得到的IMR在引入原回归方程后不与干扰项相关。该外生变量在处理效应模型中可以直接称作工具变量。此外,如果核心解释变量D是DID模型的did项,那么为了防止出现多重共线性,应该尽量避免使用D的滞后项D_lag作为工具变量。事实上,如果找到了一个良好的工具变量,也完全能够使用2SLS解决内生性问题。此外,两个模型除了都需要在第一阶段引入至少一个外生变量,第一阶段回归中的其余控制变量也应该是第二阶段回归中所有的控制变量,即应该包括所有的外生解释变量,原因在于保证两阶段估计的一致性。然而,部分文献在第一阶段并未包括第二阶段所有的外生解释变量,少部分文献甚至根本就不引入第二阶段的外生解释变量(如,考虑滞后效应,直接引入第二阶段外生解释变量的滞后项),并且在Stata处理效应模型的官方命令etregress的help文件的演示案例中,第一阶段回归也并未包括所有的外生解释变量,原因可能在于IMR是一个非线性项,因此不包含所有外生解释变量引起的内生性问题可能并没有2SLS那么严重。
4. 第一步回归都只能是probit模型。由于logit模型不具备扰动项服从正态分布的假设,如果使用logit模型估计选择方程,将直接导致IMR计算错误,因为Heckman(1979)在推导IMR时,假设选择方程的随机扰动项服从正态分布。这与PSM不同,PSM估计概率方程可以使用logit模型,也可以使用probit模型,并且实际使用中流行的是logit模型。然而,选择方程使用probit模型进行估计有一个问题不可忽视,那就是probit(包括Stata的xtprobit)不能估计固定效应模型,因此即便在回归方程中引入时间虚拟变量和个体虚拟变量,控制的也只是“时间效应”和“个体效应”,不能加入“固定”二字。
不同点在于:
1. 解决的问题不同。样本选择模型解决的是样本选择偏差导致的内生性问题,处理效应模型解决(或者“缓解”)的是依不可观测因素导致的自选择偏差问题。在实际应用中,部分文献在分析内生性问题时将样本选择偏差与自选择偏差混淆,从而使用的模型也是不恰当的。在数据搜集过程中,对被解释变量存在缺失值的样本,多数文献的做法是直接把这些样本剔除,因而即便文章中考虑到了样本选择偏差问题,我们也无法使用样本选择模型(或Heckman两步法)。事实上,囿于数据缺陷,大多数实证类论文都不具备实施Heckman两步法的条件。对于DID类的实证论文,对内生性的分析角度应该更多考虑从自选择偏差切入,而非样本选择偏差,因为各样本处理组虚拟变量D的取值本身就提供了自选择偏差分析的条件,即D取值为1的样本与D取值为0的样本在某些方面是否存在明显的特征差异?或者,是否存在某些因素影响了各样本是否实施政策的决定,而这些因素在两组间又是否存在巨大差异?同时,这些因素是否在理论与统计意义上影响我们想研究的经济指标?在这样的分析之后,就可以使用处理效应模型来缓解因自选择偏差而导致的估计偏误。
2. 变量的设置不同。在样本选择模型第一阶段回归方程中,被解释变量是原方程中的被解释变量y是否被观测到的虚拟变量y_dummy,该变量不参与第二阶段回归,同时第一阶段引入的外生变量直接影响的是y_dummy。在处理效应模型第一阶段回归方程中,被解释变量是原方程的核心解释变量D,D取值为0或1,且不存在缺失值,该变量还同时参与了第二阶段回归,此外第一阶段引入的外生变量(或称工具变量)直接影响的是D。
3. 各阶段样本参与回归的数目不同。假设除关键变量,其余变量都不存在缺失值,那么对于样本选择模型来说,第一阶段回归的解释变量均不存在缺失值,被解释变量y_dummy取值为0或1,也不存在缺失值,因此选择方程中参与回归的样本是全样本,第二阶段由于被解释变量y本身就存在缺失值,因此参与第二阶段回归的样本不是全样本,从而第一阶段的样本多于第二阶段。对于处理效应模型来说,所有变量均不存在缺失值,因此两阶段参与回归的样本是相同的,虽然在第一阶段引入滞后项D_lag作为工具变量的情况下会损失一部分样本,但由于计算出来的IMR同样也存在缺失值,从而第二阶段参与回归的样本也将与第一阶段相同。
3. IMR的计算公式不同。对于样本选择模型,各样本的IMR计算公式相同;对于处理效应模型来说,D取值为1的样本和D取值为0的样本IMR计算公式并不相同,并且所有样本的IMR均参与了第二步回归。所以,如果混淆了样本选择模型和处理效应模型,将直接导致变量IMR的计算错误,反而进一步造成了估计偏误。