自己第一次试着用scrapy进行爬取网页,总共爬下9240条数据,也就两分钟不到,400多页吧。用的比较简单,但是爬取成功后感觉成就感满满的。
来张爬取结果图

爬取字段:
“hospitalName”: “hospitalDesc”: “hospitalSize”:”hospitalAddress”:
1爬取字段
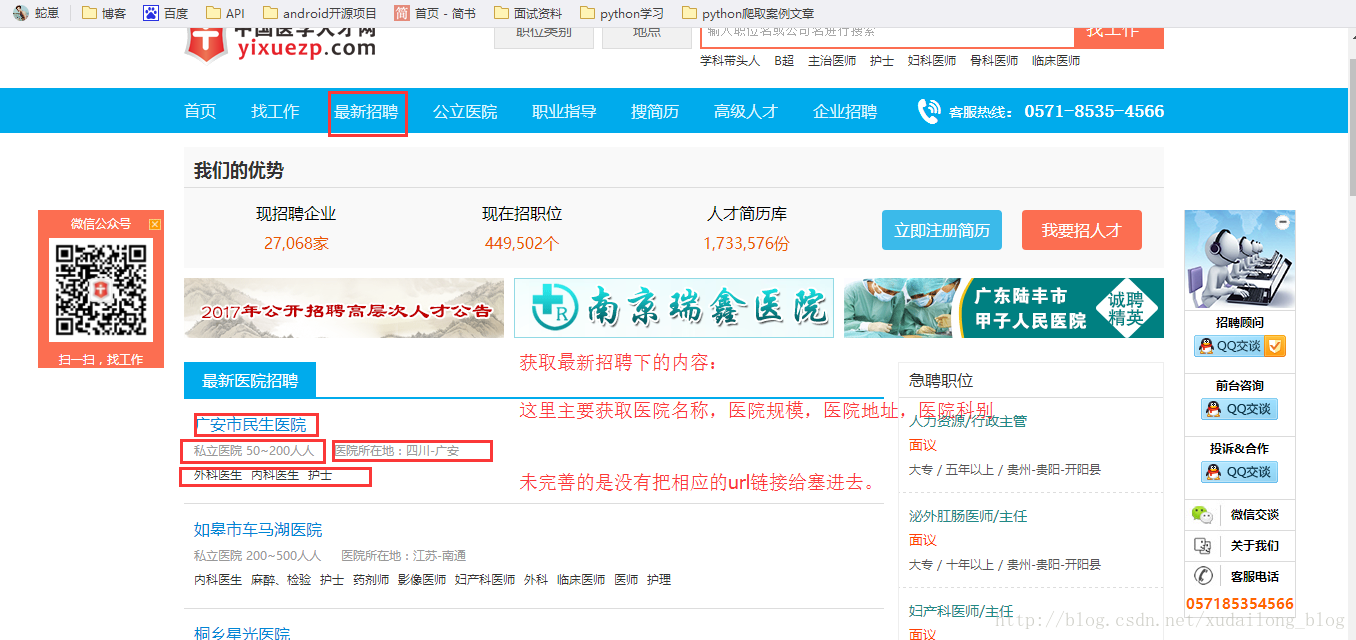
这里爬取的内容上面都有标注,只不过,爬取下来没有保存链接(稍微有点小遗憾,白天干兼职很累的,上家公司现在还没发工资。。)
(1)先上爬取的信息内容:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ChinadoctornetItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 爬取中国医学人才网的条目(共5个条目)
# 医院名称
hospitalName = scrapy.Field()
# 医院规模
hospitalSize = scrapy.Field()
# 医院所在地
hospitalAddress = scrapy.Field()
# 医院科目
hospitalDesc = scrapy.Field()
# pass
(2)接着是spider里面的内容
这里用的是scrapy里面的xpath路径, 具体xpath自己可以用一个chrom helper来进行测试,
我提取的是整个医院的item,//div[@class='newsjob']/ul/li
然后下面是提取item里面的内容,在当前路径下用 .
自己试着调试着就能搞出来的
直接贴代码:
# encoding=utf8
import scrapy
from chinadoctornet.items import ChinadoctornetItem
class ChinaDocNet(scrapy.Spider):
# 启动爬虫的名称
name = 'docNet'
# 爬取域名的范围
allowed_domains = ['yixuezp.com']
# 爬虫第一个url地址
start_urls = ['http://www.yixuezp.com/zhaopin?page={}'.format(n) for n in range(0, 464)] # 463
def parse(self, response):
# 医院name
node_list = response.xpath("//div[@class='newsjob']/ul/li")
items = []
for node in node_list:
item = ChinadoctornetItem()
hospitalName = node.xpath("./a/text()").extract()
hospitalSize = node.xpath("./span[1]/text()").extract()
hospitalAddress = node.xpath("./span[2]/text()").extract()
hospitalDesc = node.xpath("./p/a/text()").extract()
item['hospitalName'] = hospitalName
item['hospitalSize'] = hospitalSize
item['hospitalAddress'] = hospitalAddress
item['hospitalDesc'] = hospitalDesc
items.append(item)
# return items # 如果直接return的话,一页数据只会返回一条数据
yield item #用yield 的话,可以交给下载器,继续执行下一步操作。
(3)以json格式进行下载数据
代码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class ChinadoctornetPipeline(object):
def process_item(self, item, spider):
return item
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('中国医学人才网招聘最新招聘专栏2.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
最后就是这样子了, 下载器这一块代码是直接复制上一份的,不过,代码都一样,多记想想为什么,就通了。
settings里面的代码没有动,只是吧ROBOTSTXT_OBEY设置为False了。
下次再进行几个网站的爬取,早点找工作啊,还要找些典型的网站进行练手。
这个是为:我是呆子爬取的数据