这篇论文提出的GIou损失函数,是一种目标检测领域用于回归目标框损失函数。该Trick适用于任何目标检测算法。本文以YOLOv3为例进行阐述。
论文:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression 源码
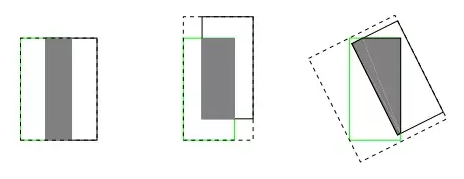
MSE回归策略 在原始的YOLOv3中,利用MSE作为损失函数来进行目标框的回归,如下图所示,不同质量的预测结果,利用MSE评价指标有时候并不能区分开来。更重要的一点是,MSE损失函数对目标的尺度相当敏感,在原始的论文中通过对目标的长宽开根号的方式降低尺度对回归准确性的影响,但并没有根治这种问题。 IOU回归策略 由于IOU计算的是交并比,因此IOU更能体现回归框的质量,而且IOU在目标尺度上具有较好的鲁棒性。作者考虑使用IOU替代MSE进行目标框的回归。作者通过实验发现,用IOU作为损失函数进行回归,相较于MSE的结果有提升。 然而用IOU作为损失函数时会遇到如下两个问题: 1.但检测框与gt之间没有重合时,IoU为0。而在优化损失函数时,梯度为0,意味着无法优化。 2.在检测框与gt之间IoU相同时,检测的效果也具有较大差异,如下图所示: GIou回归策略 基于IOU回归策略存在的两个问题,作者提出了GIou作为回归目标框的损失函数。下图所示为GIou和Iou之间的计算方式的区别,以及对应的代码。且GIou有如下优势。 1.GIoU具有作为一个度量标准的优良性质。包括非负性,同一性,对称性,以及三角不等式的性质 2.与IoU相似,具有尺度不变性 3.GIoU的值总是小于IoU的值 4.对于两个矩形框A和B,0≤IoU(A,B)≤1,而-1≤GIoU≤1 5.在A,B没有良好对齐时,会导致C的面积增大,从而使GIoU的值变小,而两个矩形框不重合时,依然可以计算GIoU,一定程度上解决了IoU不适合作为损失函数的原因 GIou & Iou & MSE实现对比代码 如下图所示,为Iou和GIou作为目标损失函数的伪代码,以及YOLOv3中MSE和GIou,Iou回归目标框的代码比对。 比较结果 如下图所示,利用Iou作为目标框回归函数相较于MSE对结果有一定提升,而利用GIou则得到了最好的结果。
最近在ICCV中出现的Gaussian YOLOv3以及本文提到的GIou YOLOv3。他们两者优化的是两个没有交集的部分,Gaussian优化的是网络输出,使用的仍然是mse,而Giou优化的是损失函数,因此把这两种策略结合在一起效果说不定会有进一步的优化。