最近在用ppyolo训练好的模型对新采集的数据进行标记,再人工微调,减少从头打标签的时间,但是推理保存的结果都是txt格式的,想要在labelimg中可视化,那就需要将txt转换成xml。
以下代码即可完成这一功能。
# -*- coding:UTF-8 -*-
import os
import cv2
def txt_to_xml(classname_path, txt_path, img_path, xml_path):
# 1.读取txt文件中的标签类别
with open(classname_path, 'r') as f:
classes = f.readlines() # list, 每个类别末尾都有'\n'
classes = [cls.strip('\n') for cls in classes]
# 2.找到txt标签文件夹
files = os.listdir(txt_path)
# 用于存储 "老图"
pre_img_name = ''
# 3.遍历文件夹
for i, name in enumerate(files):
# mac系统中文件夹里有该文件,默认的也删不掉,那就直接pass
if name == '.DS_Store':
continue
print(name)
# 4.打开txt
txtFile = open(txt_path + name)
# 读取所有内容
txtList = txtFile.readlines()
# 读取图片名称
img_name = name.split(".")[0]
pic = cv2.imread(img_path + img_name + ".jpg")
# 获取图像大小信息
Pheight, Pwidth, Pdepth = pic.shape
# 5.遍历txt文件中每行内容
for row in txtList:
# 按' '分割txt的一行的内容
oneline = row.strip().split(" ")
# 遇到的是一张新图片
if img_name != pre_img_name:
# 6.新建xml文件
xml_file = open((xml_path + img_name + '.xml'), 'w')
xml_file.write('<annotation>\n')
xml_file.write(' <folder>billiards</folder>\n')
xml_file.write(' <filename>' + img_name + '.jpg' + '</filename>\n')
xml_file.write(' <path>E:/Images</path>\n')
xml_file.write(' <source>\n')
xml_file.write(' <database>orgaquant</database>\n')
xml_file.write(' </source>\n')
xml_file.write(' <size>\n')
xml_file.write(' <width>' + str(Pwidth) + '</width>\n')
xml_file.write(' <height>' + str(Pheight) + '</height>\n')
xml_file.write(' <depth>' + str(Pdepth) + '</depth>\n')
xml_file.write(' </size>\n')
xml_file.write(' <object>\n')
xml_file.write(' <name>' + classes[int(oneline[0])] + '</name>\n')
xml_file.write(' <difficult>' + str(0) + '</difficult>\n')
xml_file.write(' <bndbox>\n')
xml_file.write(' <xmin>' + str(
int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)) + '</xmin>\n')
xml_file.write(' <ymin>' + str(
int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)) + '</ymin>\n')
xml_file.write(' <xmax>' + str(
int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)) + '</xmax>\n')
xml_file.write(' <ymax>' + str(
int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)) + '</ymax>\n')
xml_file.write(' </bndbox>\n')
xml_file.write(' </object>\n')
xml_file.close()
pre_img_name = img_name # 将其设为"老"图
else: # 不是新图而是"老图"
# 7.同一张图片,只需要追加写入object
xml_file = open((xml_path + img_name + '.xml'), 'a')
xml_file.write(' <object>\n')
xml_file.write(' <name>' + classes[int(oneline[0])] + '</name>\n')
xml_file.write(' <difficult>' + str(0) + '</difficult>\n')
''' 按需添加这里和上面
xml_file.write(' <pose>Unspecified</pose>\n')
xml_file.write(' <truncated>0</truncated>\n')
xml_file.write(' <difficult>0</difficult>\n')
'''
xml_file.write(' <bndbox>\n')
xml_file.write(' <xmin>' + str(
int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)) + '</xmin>\n')
xml_file.write(' <ymin>' + str(
int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)) + '</ymin>\n')
xml_file.write(' <xmax>' + str(
int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)) + '</xmax>\n')
xml_file.write(' <ymax>' + str(
int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)) + '</ymax>\n')
xml_file.write(' </bndbox>\n')
xml_file.write(' </object>\n')
xml_file.close()
# 8.读完txt文件最后写入</annotation>
xml_file1 = open((xml_path + pre_img_name + '.xml'), 'a')
xml_file1.write('</annotation>')
xml_file1.close()
print("Done !")
if __name__== '__main__':
classname_path = '/Users/h1y/Documents/mac2server/billiards/billiards_classes.txt' # names文件的路径
# 修改成自己的文件夹 注意文件夹最后要加上/
txt_path = "/Users/h1y/Documents/mac2server/billiards/txt2xml/labels/"
img_path = "/Users/h1y/Documents/mac2server/billiards/txt2xml/images/"
xml_path = "/Users/h1y/Documents/mac2server/billiards/txt2xml/"
txt_to_xml(classname_path, txt_path, img_path, xml_path)
其中,代码中第一步提到的类别标签txt文件内容格式如下,每一行为一个类别

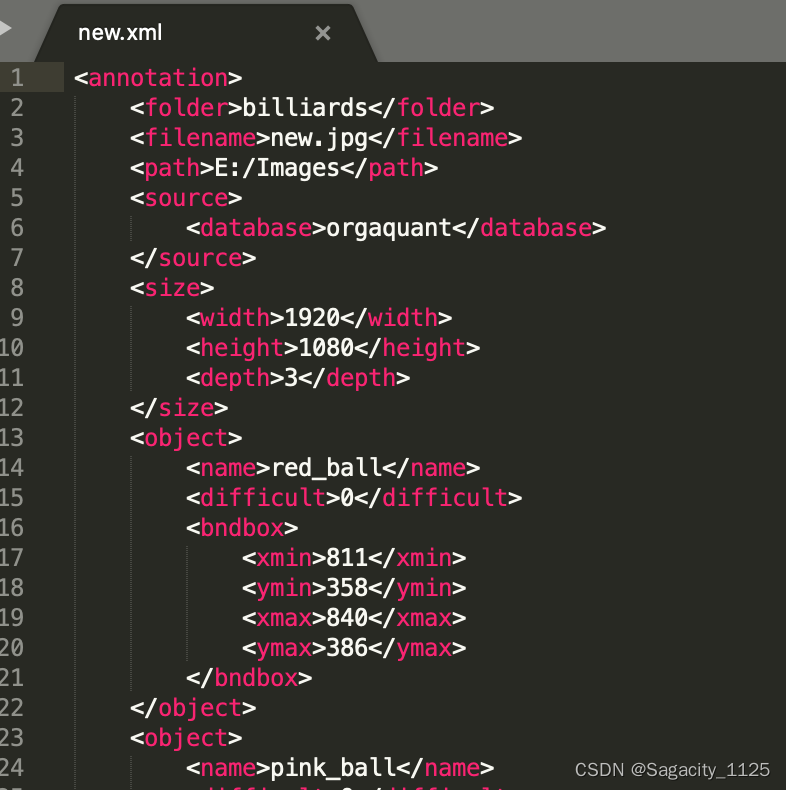
转换后的xml文件和labelimg生成的格式一样,如下所示