手写字体的检测
(1) Adaboost进行手写字体的检测
导入mnist数据集
import tensorflow.examples.tutorials.mnist.input_data as input_data
data_dir = '../MNIST_data/'
mnist = input_data.read_data_sets(data_dir,one_hot=False)
batch_size = 50000
test_x = mnist.test.images[:10000]
test_y = mnist.test.labels[:10000]
一共60000个数据集,取50000用于训练,10000用于测试训练出的模型。
调用Adaboost分类器进行训练:
batch_x,batch_y = mnist.train.next_batch(batch_size)
clf_rf = AdaBoostClassifier(n_estimators = 60)
clf_rf.fit(batch_x,batch_y)
评估预测的效果:
y_pred_rf = clf_rf.predict(test_x)
acc_rf = accuracy_score(test_y,y_pred_rf)
print("%s n_estimators = 60, accuracy:%f" % (datetime.now(), acc_rf))
选取较好的参数(弱分类器数量):
先通过调节弱分类器数量来获得一个训练效果比较不错的数量参数(虽然之后发现预测率好像是改变的)
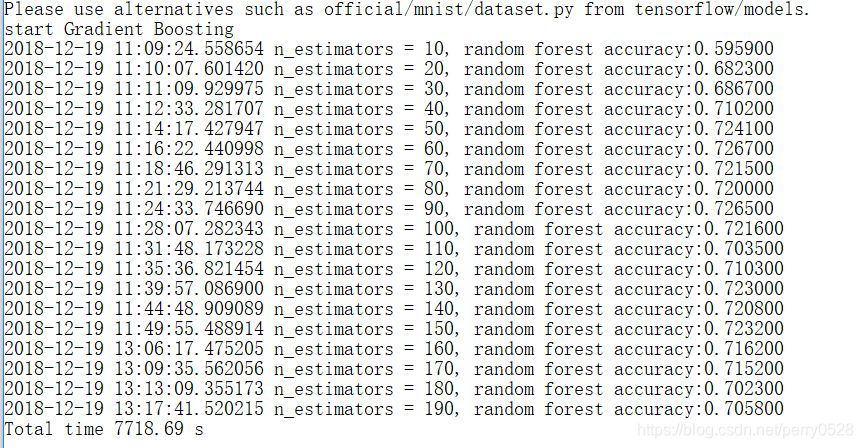
之后选取弱分类器参数为60进行训练
在对自己的手写图片读入前先进行几步处理:
- 将图片转为二值图
- resize为mnist训练集要求的(28*28)尺寸
- 将图像进行膨胀处理
img = cv2.resize(img, (28, 28), interpolation=cv2.INTER_CUBIC)
GrayImage = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,thresh2=cv2.threshold(GrayImage,127,255,cv2.THRESH_BINARY_INV)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3))
img = cv2.dilate(thresh2,kernel)
处理好的图片效果如下:

同时有一点很坑的要注意就是mnist要识别的是西方的手写字体,和我们常写的有一点区别。
下面是用于读入的手写数字

进行一步裁剪处理:

下面是预测效果:
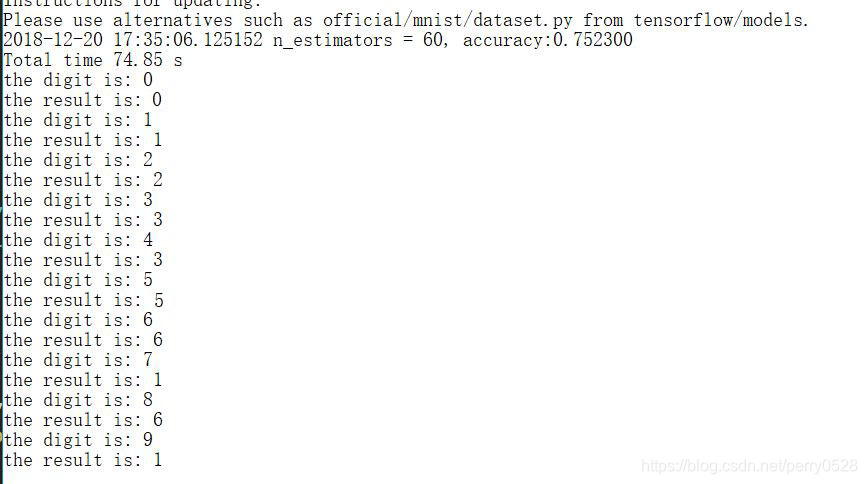
test集的准确率为75%左右,自己手写数字的准确率为60%,这是一个比较不期望的结果,于是考虑用一个自己搭建的CNN网络对模型进行测试(参考tensorflow中文社区)
(2) 卷积神经网络(CNN)进行手写字体的检测
1. 权重初始化
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
2. 卷积和池化
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
3. 第一层卷积
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
4.第二层卷积
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
5. 密集连接层
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
6. Dropout
(屏蔽神经元的输出以及自动处理神经元输出值的scale )
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
7. 输出层
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
8. 训练和评估模型
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver() # defaults to saving all variables
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
saver.save(sess, './model/model.ckpt') #保存模型参数,注意把这里改为自己的路径
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
最终跑出的模型准确度接近99.3%
训练出的模型:
9. 用存储的model对自己的手写字体进行测试:
init_op = tf.initialize_all_variables()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
saver.restore(sess, "./model/model.ckpt")#这里使用了之前保存的模型参数
prediction=tf.argmax(y_conv,1)
predint=prediction.eval(feed_dict={x: [result],keep_prob: 1.0}, session=sess)
print('the digit is 9: ')
print('recognize result:')
print(predint[0])
10. 效果:
(最终效果10张图全部都预测准确,再测了几张写得不是特别规范的数字也基本都识别正确)

完整代码参见:
https://github.com/WangPerryWPY/Computer-Version/tree/master/Exp7/code/work2