本文讲解了时间序列数据异常值检测的基本概念和在 Kylin 中开发使用异常值检测 UDF 的方法,可以作为其他 UDF 开发的参考。
通过在 Kylin 中移植 Hivemall 的 UDF,我们可以充分利用 Kylin 的优势,减少直接使用 Hivemall 过程中的数据加工、存储等繁杂步骤的工作量,提升用户的查询体验。本文使用的验证环境为 Kylin 2.6.3。
时间序列数据的异常值检测
时间序列数据是聚合数据中的一种重要类别,数据分析人员经常需要使用各种方法从不同角度对聚合得到的时间序列数据进行挖掘,异常值检测(Anomaly Detection)就是其中的一种常见方法。异常值检测的主要目标是从时间序列数据中区分出与预期的正常值不符的值[1],如离群值(outlier)和突变点(change-point)等,这些值往往具有比较高的关注价值,是分析人员在进行业务分析时需要重点关注的对象。
时间序列数据的异常值检测具有广泛的应用场景,例如:应用在一般的商业领域中,有助于定位生产销售中的异常波动;应用在运维中,有助于迅速发现故障;应用在医学上,有助于医生做出诊断,等等。
Hivemall 的异常值检测函数
使用传统方法在大数据集上进行异常值检测存在效率低、不够灵活等问题,因此就有人尝试引入 Hive,通过对 Hive 进行扩展来解决这些问题。例如,Apache 孵化项目 Hivemall (http://hivemall.incubator.apache.org)为 Hive 提供了大量的数据分析 UDF(User-defined Function,用户定义函数)作为扩展,其中就包括一个用于进行异常值检测的函数 changefinder。changefinder 函数实现了 ChangeFinder 算法[2],提供一维和二维数据浮点数据的离群值和突变点检测功能。
Hivemall 在官网中提供了一个使用示例数据(https://github.com/apache/incubator-hivemall/blob/master/core/src/test/resources/hivemall/anomaly/twitter.csv.gz?raw=true,这是一组来自 Twitter 的时间序列数据)进行异常值检测的例子,例子中的查询语句和查询结果片段如下:
SELECT
num,
changefinder(value, "-outlier_threshold 0.03 -changepoint_threshold 0.0035") AS result
FROM
timeseries
ORDER BY num ASC
;
num |
result |
... |
... |
16 |
{"outlier_score":0.051287243859365894,"changepoint_score":0.003292139657059704,"is_outlier":true,"is_changepoint":false} |
17 |
{"outlier_score":0.03994335565212781,"changepoint_score":0.003484242549446824,"is_outlier":true,"is_changepoint":false} |
18 |
{"outlier_score":0.9153515196592132,"changepoint_score":0.0036439645550477373,"is_outlier":true,"is_changepoint":true} |
19 |
{"outlier_score":0.03940593403992665,"changepoint_score":0.0035825157392152134,"is_outlier":true,"is_changepoint":true} |
20 |
{"outlier_score":0.27172093630215555,"changepoint_score":0.003542822324886785,"is_outlier":true,"is_changepoint":true} |
21 |
{"outlier_score":0.006784031454620809,"changepoint_score":0.0035029441620275975,"is_outlier":false,"is_changepoint":true} |
22 |
{"outlier_score":0.011838969816513334,"changepoint_score":0.003519599336202336,"is_outlier":false,"is_changepoint":true} |
23 |
{"outlier_score":0.09609857927656007,"changepoint_score":0.003478729798944702,"is_outlier":true,"is_changepoint":false} |
24 |
{"outlier_score":0.23927000145081978,"changepoint_score":0.0034338476757061237,"is_outlier":true,"is_changepoint":false} |
25 |
{"outlier_score":0.04645945042821564,"changepoint_score":0.0034052091926036914,"is_outlier":true,"is_changepoint":false} |
... |
... |
在 Kylin 中使用 UDF
Apache Kylin 是一个基于 Hadoop 平台的 OLAP 引擎,它采用预计算的理念,预先对查询中可能使用到的表和维度进行关联、聚合,使得后续的查询可以直接使用预计算的结果。预计算结果被存储下来 ,通过消耗存储空间换取更快速的查询响应,即所谓的空间换时间。Hivemall 基于 Hive 大幅提升了在大数据集上进行异常值检测的效率和灵活性,但在分析聚合数据的场景下,以其查询效率仍然无法实现实时交互式分析,因此可以考虑通过引入 Kylin 来解决这个问题。
与 Hive 等类似,Kylin 也支持 UDF,允许用户对查询中需要使用的函数进行一定的扩展,下面我们就尝试通过创建 UDF 的方式,在 Kylin 中引入 Hivemall 的一维 changefinder 函数。
创建 Kylin 的 UDF 主要有两个步骤:
创建一个包含 UDF 相关方法的类,具体需要哪些方法将在后文详细介绍。
修改 Kylin 目录下的 conf/kylin.properties 配置文件,添加一行 kylin.query.udf.{UDF名称}={UDF类名},保存并重启 Kylin 后就可以使用定义好的 UDF 了。
Hivamall 中的 ChangeFinder 算法
在动手之前,我们先简要考察一下 ChangeFinder 算法的原理和它在 Hivemall 中的实现。ChangeFinder 是一种基于自回归模型的算法,包括分别检测离群值和突变点的两大阶段,每个阶段又可以细分为更新自回归模型和计算异常分值两个步骤。这其中两个阶段的计算过程是几乎相同的,输出分别是离群分值和突变分值,主要区别在于输入不同,突变点检测阶段以离群值检测阶段的输出作为输入。
ChangeFinder 算法定义了时间序列上的自回归模型,并设计了用于估计模型参数的算法,称为 Sequentially Discounting AR Model Learning 算法,简称 SDAR 算法。SDAR 算法有两个参数,分别是模型的阶数和衰减系数,序列数据保存在长度为的 RingBuffer 中,经 SDAR 算法计算就可以得到该序列对应自回归模型的参数,这部分在一维数据上的实现在 hivemall.anomaly.SDAR1D 类中。
有了这些参数,就可以使用模型的概率密度函数进行分值的计算,Hivemall 中提供了海林格距离和对数两种计算方式,其中默认使用的是海林格距离。此外,ChangeFinder 算法在突变点检测阶段的开始和结束时会分别对输入的离群分值和输出的突变分值进行窗口平滑,这就需要额外的两个输入参数,即窗口大小T1和 T2。
static double evalScoreY(DoubleRingBuffer xRing,
SDAR1D sdar1,
DoubleRingBuffer yRing,
SDAR1D sdar2,
DoubleRingBuffer outlierScores, DoubleRingBuffer changepointScores,
double x, int k) {
//计算离群分值
double scoreX = evalScoreX(xRing, sdar1, x, k);
//第一次平滑
double y = smoothing(outlierScores.add(scoreX));
//计算突变分值
double[] ySeries = new double[k + 1];
yRing.add(y).toArray(ySeries, false);
int k2 = yRing.size() - 1;
double y_hat = sdar2.update(ySeries, k2);
double lossY = (k2 == 0D) ? 0D : hellingerLoss(sdar2);
//第二次平滑
double scoreY = smoothing(changepointScores.add(lossY));
return scoreY;
}
UDF 开发过程中的主要问题
了解了上面这些信息,就可以开始动手移植了,动手过程中需要解决几个问题:
首先是 UDF 的类型问题。Kylin 的 SQL 支持来自另一个 Apache 开源项目 Calcite(http://calcite.apache.org),Calcite支持的 UDF 除最基本的单行映射的函数外,还有聚合函数和窗口聚合函数两种,即 UDAF 和 Window UDAF。
不同类型的 UDF,其类定义和在 SQL 中的使用方法也不尽相同,聚合函数将整列数据聚合成一个,如 count、sum 等,窗口聚合函数则是与 over 子句一起使用的聚合函数。从上面考察的 changefinder 算法的原理来看,这里我们应该选择窗口聚合函数,这样就需要在类中定义 5 个方法:init、add、merge、remove result (http://calcite.apache.org/docs/adapter.html,Extensibility 小节),并定义一个类,用于储存异常分值计算的中间结果。
其次,要解决函数拆分的问题。Hivemall 中的 changefinder 函数将离群值和突变点的检测放在了一起,以 json 的形式输出计算结果,我们可以将它拆分成两个 UDF,即定义两个类 OutlierWindowUDF 和 ChangePointWindowUDF,分别用于计算离群分值和突变分值,以方便进一步的分析。以 changepoint 函数为例,拆分后的主要计算过程如下:
static double evalScoreY(DoubleRingBuffer xRing,
SDAR1D sdar1,
DoubleRingBuffer yRing,
SDAR1D sdar2,
DoubleRingBuffer outlierScores, DoubleRingBuffer changepointScores,
double x, int k) {
//计算离群分值
double scoreX = evalScoreX(xRing, sdar1, x, k);
//第一次平滑
double y = smoothing(outlierScores.add(scoreX));
//计算突变分值
double[] ySeries = new double[k + 1];
yRing.add(y).toArray(ySeries, false);
int k2 = yRing.size() - 1;
double y_hat = sdar2.update(ySeries, k2);
double lossY = (k2 == 0D) ? 0D : hellingerLoss(sdar2);
//第二次平滑
double scoreY = smoothing(changepointScores.add(lossY));
return scoreY;
接下来要解决数据结构初始化的问题。Hive 允许 UDF 在进行计算之前使用传入的参数进行初始化,但 Calcite 的 UDF 并不支持带参数的初始化,因此需要在计算第一行时使用、等参数进行初始化,OutlierWindowUDF 需要初始化 1 个 DoubleRingBuffer 变量和 1 个 SDAR1D 变量,而 ChangePointWindowUDF 需要初始化 4 个 DoubleRingBuffer 变量和 2 个 SDAR1D 变量。Calcite 聚合函数类型的 UDF 需要使用一个用户定义的类作为 Accumulator,因此我们可以定义一个内部类,用于存储计算过程中所需的各种变量,以 outlier 函数为例:
class OutlierWindowStatus {
DoubleRingBuffer xRing;
SDAR1D sdar1;
double result;
boolean initialized;
OutlierWindowStatus() {
xRing = null;
sdar1 = null;
result = 0D;
initialized = false;
}
void initialize(int k, double r) {
xRing = new DoubleRingBuffer(k + 1);
sdar1 = new SDAR1D(r, k);
initialized = true;
}
void setResult(double result) {
this.result = result;
}
}
public OutlierWindowStatus init() {
return new OutlierWindowStatus();
}
public OutlierWindowStatus add(OutlierWindowStatus ows, BigDecimal x, int k, BigDecimal r1) {
if (!ows.initialized) {
ows.initialize(k, r1.doubleValue());
}
ows.setResult(evalScoreX(ows.xRing, ows.sdar1, x.doubleValue(), k));
return ows;
}
public OutlierWindowStatus merge(OutlierWindowStatus ows1, OutlierWindowStatus ows2) {
return ows1;
}
public OutlierWindowStatus remove(OutlierWindowStatus ows, double x) {
return ows;
}
public double result(OutlierWindowStatus ows) {
return ows.result;
}
还要注意的是,由于 Calcite 会把窗口聚合函数输入的非整数作为 BigDecimal 类型来处理,这里也应该把相应的参数定义为 BigDecimal 类型。
最后,使用 maven 的 shade 插件进行打包,并排除其中的 SF、DSA、RSA 等签名文件,就得到了可以放入 Kylin 的 lib 目录的 jar 文件,在 kylin.properties 文件中加入以下两行并重启 Kylin,就可以使用 UDF 了:
kylin.query.udf.outlier_window=org.apache.kylin.query.udf.OutlierWindowUDF
kylin.query.udf.changepoint_window=org.apache.kylin.query.udf.ChangePointWindowUDF
我们可以将 Hivemall 提供的示例数据导入到 Hive 中,使用 Kylin 建立 Cube 并进行简单的查询验证,以 outlier 函数为例:
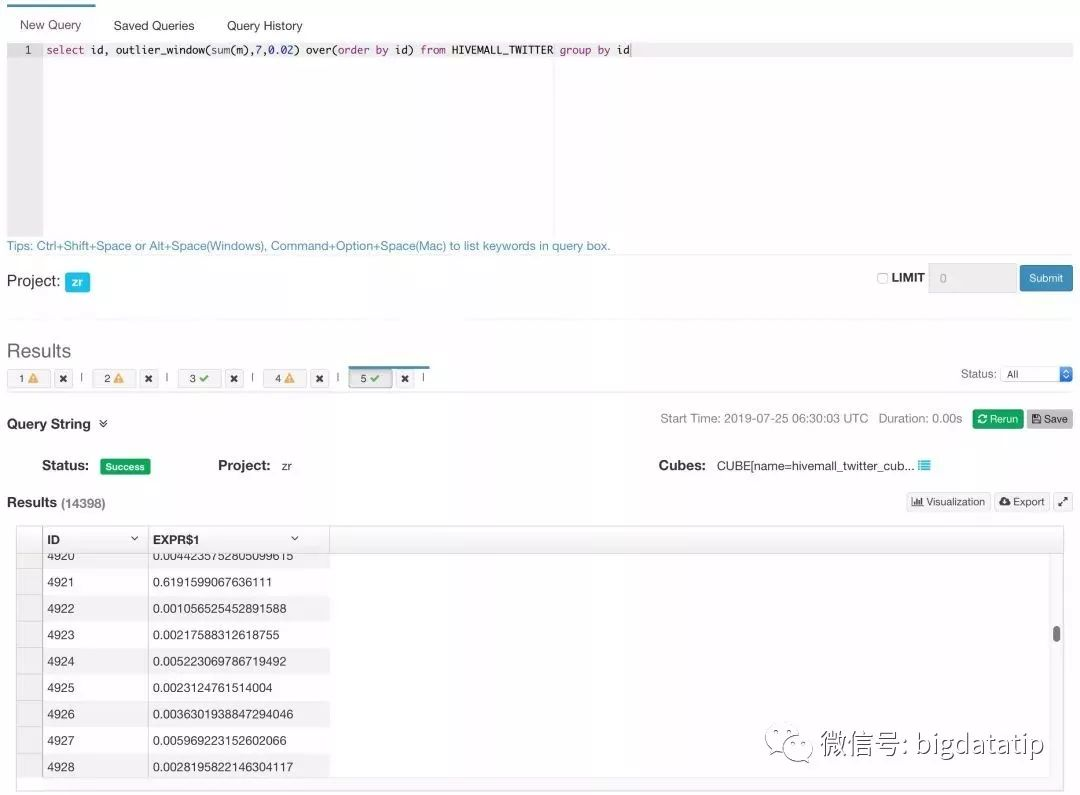
如上图,我们使用一条简单的 SQL 语句验证 outlier 函数,返回的结果就是在示例数据上计算得到的离群分值。为了使结果更加直观一些,可以将查询结果导出,从中截取一个 100 行的片段绘图,在图中加入一条表示阈值的虚线:
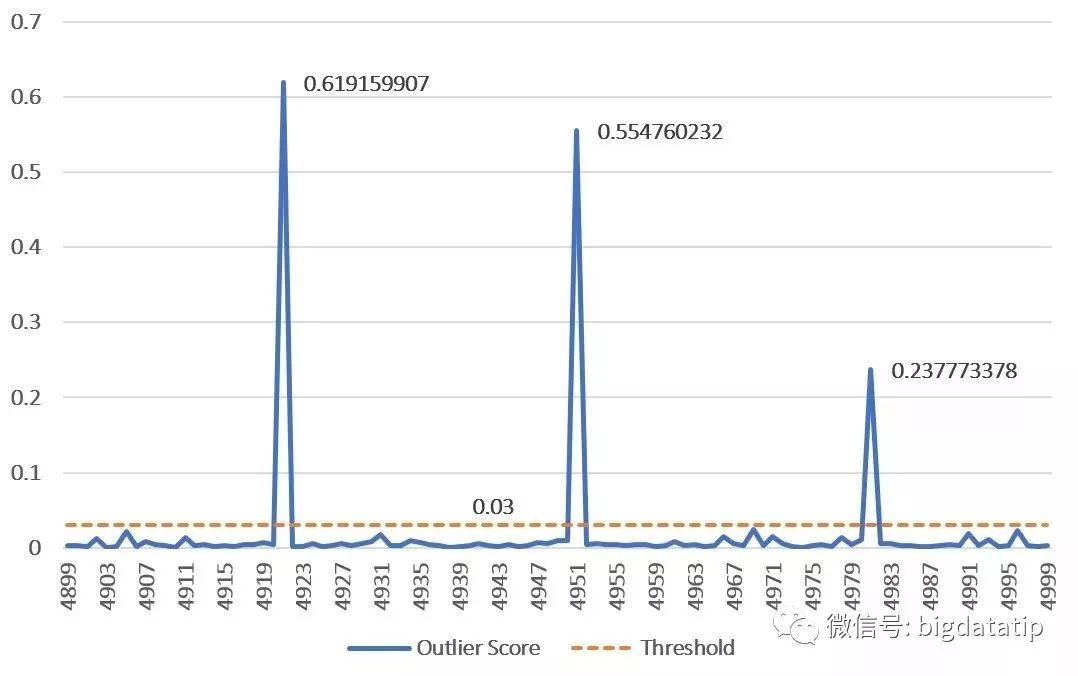
图中的横轴表示数据的行号,纵轴表示数据的离群分值,取阈值为 0.03,可以看到,函数成功检测出了这 100 条数据中的 3 个比较明显的离群值。
作者介绍:郑嵘,Kyligence 研发工程师,主要负责 Kyligence MDX 研发。
参考文献
[1] Chandola, Varun, Arindam Banerjee, and Vipin Kumar. Anomaly detection: A survey. ACM computing surveys (CSUR) 41.3 (2009): 15.
[2] K. Yamanishi and J. Takeuchi. A Unifying Framework for Detecting Outliers and Change Points from Non-Stationary Time Series Data. KDD 2002.
