最近工作中应用到了 Kylin,因此调研了 Kylin的原理和行业应用。本文参考了官网和众多其他公司中 Kylin的应用案例,文末给出了出处,希望对大家有帮助。
Apache Kylin的原理和技术架构
Apache Kylin 从数据仓库中最常用的Hive中读取源数据,使用 MapReduce作为Cube构建的引擎,并把预计算结果保存在HBase中,对外暴露Rest API/JDBC/ODBC的查询接口。
Apache Kylin系统主要可以分为在线查询和离线构建两部分,具体架构图如下:

Apache Kylin在百度地图的实践
对于 Apache Kylin 在实际生产环境中的应用,在国内,百度地图数据智能组是最早的一批实践者之一。目前,百度地图大数据 OLAP 多维分析平台承载百度地图内部多个基于 Apache Kylin 引擎的亿级多维分析查询项目,共计约 80 个 cube,平均半年时间的历史数据,共计约 50 亿行的源数据规模,单表最大数据量为 20 亿 + 条源数据,满足大时间区间、复杂条件过滤、多维汇总聚合的单条 SQL 查询毫秒级响应,较为高效地解决了亿级大数据交互查询的性能需求。
Kylin 有效解决的痛点问题:
痛点一:百亿级海量数据多维指标动态计算耗时问题,Apache Kylin 通过预计算生成 Cube 结果数据集并存储到 HBase 的方式解决。
痛点二:复杂条件筛选问题,用户查询时,Apache Kylin 利用 router 查找算法及优化的 HBase Coprocessor 解决;
痛点三:跨月、季度、年等大时间区间查询问题,对于预计算结果的存储,Apache Kylin 利用 Cube 的 Data Segment 分区存储管理解决。
百度地图大数据 OLAP 平台系统架构

主要模块包括:
数据接入:主要负责从数据仓库端获取业务所需的最细粒度的事实表数据。
任务管理:主要负责Cube 的相关任务的执行、管理等。
任务监控:主要负责Cube 任务在执行过程中的状态及相应的操作管理。
集群监控:主要包括Hadoop 生态进程的监控及Kylin 进程的监控。
基于仓库端 join 好的 fact 事实表建 Cube,减少对小规模集群带来的 hive join 压力
对于 Cube 的设计,官方有专门的相关文档说明,里面有较多的指导经验,比如: cube 的维度最好不要超过 15 个, 对于 cardinality 较大的维度放在前面,维度的值不要过大,维度 Hierarchy 的设置等等。
实践中,百度地图将某个产品需求分为多个页面进行开发,每个页面查询主要基于事实表建的 cube,每个页面对应多张维度表和 1 张事实表,维度表放在 MySQL 端,由数据仓库端统一管理,事实表计算后存放在 HDFS 中,事实表中不存储维度的名称,仅存储维度的 id,主要基于 3 方面考虑:
假设我们把维度名称也存在 Cube 中,如果维度名称变化必然导致整个 cube 的回溯,代价很大。这里可能有人会问,事实表中只有维度 id 没有维度 name,假设我们需要 join 得到查询结果中含有维度 name 的记录,怎么办呢?对于某个产品的 1 个页面,我们查询时传到后台的是维度 id,维度 id 对应的维度 name 来自 MySQL 中的维度表,可以将维度 name 查询出来并和维度 id 保存为 1 个维度 map 待后续使用。同时,一个页面的可视范围有限,查询结果虽然总量很多,但是每一页返回的满足条件的事实表记录结果有限,那么,我们可以通过之前保存的维度 map 来映射每列 id 对应的名称,相当于在前端逻辑中完成了传统的 id 和 name 的 join 操作。
Aggregation cube 辅助中高维度指标计算,解决向上汇总计算数据膨胀问题
比如我们的事实表有个 detail 分区数据,detail 分区包含最细粒度 os 和 appversion 两个维度的数据 (注意: cuid 维度的计算在仓库端处理),我们的 cube 设计也选择 os 和 appversion,hierarchy 层次结构上,os 是 appversion 的父亲节点,从 os+appversion(group by os, appversion) 组合维度来看,统计的用户量没有问题,但是按照 os(group by os) 单维度统计用户量时,会从基于这个 detail 分区建立的 cube 向上汇总计算,设上午用户使用的是 android 8.0 版本,下午大量用户升级到 android 8.1 版本,android 8.0 组合维度 + android 8.1 组合维度向上计算汇总得到 os=android(group by os, where os=android) 单维度用户,数据会膨胀且数据不准确。因此我们为事实表增加一个 agg 分区,agg 分区包含已经从 cuid 粒度 group by 去重后计算好的 os 单维度结果。这样,当用户请求 os 维度汇总的情况下,Apache Kylin 会根据 router 算法,计算出符合条件的候选 cube 集合,并按照权重进行优选级排序 (熟悉 MicroStrategy 等 BI 产品的同学应该知道这类案例),选择器会选中基于 agg 分区建立的 os 单维度 agg cube,而不从 detail 这个分区建立的 cube 来自底向上从最细粒度往高汇总,从而保证了数据的正确性。
新增留存类分析,如何更高效更新历史记录
对应小规模集群,计算资源是非常宝贵的,假设我们对于某个项目的留存分析到了日对 1 日到日对 30 日,日对 1 周到日对 4 周,日对 1 月到日对 4 月,周对 1 周到周对 4 周,月对 1 月到月对 4 月。那么对于传统的存储方案,我们将遇到问题。
假如今天是 2015-12-02,我们计算实际得到的是 2015-12-01 的数据。
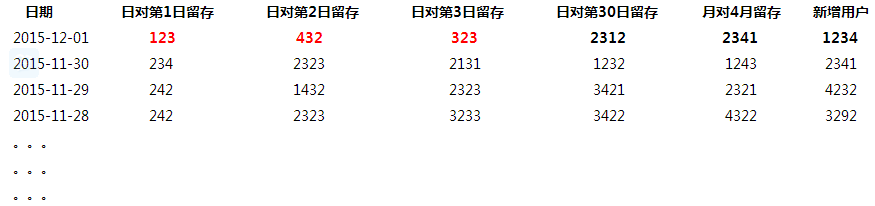
此方案的思路是,当今天是2015-12-02,实际是2015-12-01 的数据,如上示例存储,但日对第n 日的留存表示的是n 日前对应的那个日期的留存量,相当于旋转了红色对角线。
此方案的优势:
如果要查看某个时间范围内的某 1 个指标,直接选择该范围的该列指标即可
如果今后增加新的留存,比如半年留存,年留存等指标,不需要级联更新历史天数的数据,只需要更新 2015-12-01 这 1 天的数据,时间复杂度 O(1) 不变,对物理机器资源要求不高。
此方案的缺点:
如果涉及到某 1 天或者某个时间范围的多列指标查询,需要前端开发留存分析特殊处理逻辑,根据相应的时间窗口滑动,从不同的行,选择不同的列,然后渲染到前端页面。
Apache Kylin在链家的实践
链家Kylin平台的架构如图:

如上,为链家 Olap 平台结构,于 16 年底搭建。Kylin 采用集群部署模式,共部署 6 台机器,3 台用于分布式构建 Cube,3 台用于负载均衡查询,query 单台可用内存限制在 80G。同时,计算集群一旦运行大任务,内存压力大的时候,HBase 就会性能非常差,为避免和计算集群互相影响,Kylin 集群依赖独立的 Hbase 集群。同时,对 Hbase 集群做了相应的优化,包括:读写分离、SSD_FIRST 优先读取远程 SSD、并对依赖的 hdfs 做了相应优化。
由于 Kylin 只专注预计算,不保存明细数据,对于即席查询和明细查询,通过自研 QE 引擎实现,底层依赖 spark、presto、hive,通过特定规则,路由到相应查询引擎执行查询。多维分析查询,由 Kylin 集群提供查询服务,可实现简单的实时聚合计算。
当前 Kylin 主要查询方为指标 API 平台,能根据查询 sql 特征,做相应缓存。指标 API 作为数据统一出口,衍生出其他一些业务产品。使用统计,如下:Cube 数量 500+,覆盖公司 12 个业务线。Cube 存储总量 200+TB,数据行万亿级,单 Cube 最大 40+亿行。日查询量 27 万+,缓存不命中情况下,时延 < 500ms(70%), < 1s(90%),少量复杂 sql 查询耗时 10s 左右。
当前,kylin 在用版本为 1.6,最新版本为 2.3。自 2.0 版本之后,又新增了一些新的特性,配置文件和属性也做了一些调整。由于,Cube 数据量大,涉及业务方多,在当前无明显瓶颈的情况下,没有实时更新新版本。但是,引入了 2.0+新增的一些重要特性,如分布式构建和分布式锁。
链家维护了自己的一套 Kylin 代码,使用过程中,针对特定场景的进行一些优化开发,包括:
支持分布式构建。原生 kylin 是只能有一台机器进行构建。的当 kylin 上的 cube 越来越多,单台机器显然不能满足任务需求,除了任务数据有限制,任务多时也会互相影响数据构建的效率。通过修改 kylin 的任务调度策略,支持了多台机器同时构建数据。使 kylin 的构建能力可以横向扩展,来保证数据构建;
优化构建时字典下载策略。原生 kylin 在 build cubiod data 时用的字典,会将该字段的全部字典下载到节点上,当字段的字典数量很多或者字典文件很大时,会在文件传输上消耗很多不必要的时间。通过修改代码,使任务只下载需要的字典文件,从而减少文件传输时间消耗,加快构建;
全局字典锁,在同一 Cube 所任务构建时,由于共享全局字典锁,当某执行任务异常时,会导致其他任务获取不到锁,此 bug 已修复并提交官方;
支持设置 Cube 强制关联维表,过滤事实表中无效的维度数据。kylin 创建的临时表作为数据源。当使用 olap 表和维表关联字段作为维度时,会默认不关联维表,直接使用 olap 中的字段做维度。而在 Build Cube 这一步又会使用维表的字典来转换维度的值。如果 olap 中的值维表中没有就会产生问题。我们通过增加配置项,可以使 kylin 强制关联维表,来过滤掉 olap 表中的脏数据;
Kylin query 机器,查询或者聚合,会加载大量的数据到内存,内存占用大,甚至存在频繁 Full GC 的情况。这种情况下,CMS 垃圾回收表现不是很好,因此更换为 G1 收集器,尽量做到 STW 时间可控,并及时调优。
Kylin在滴滴OLAP引擎中的应用
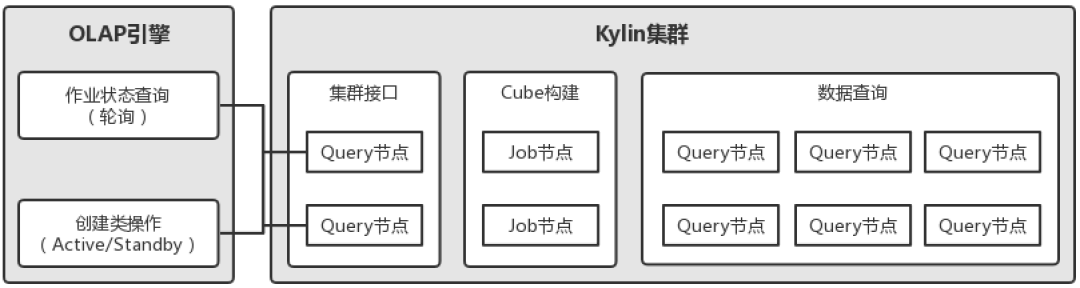
下图为 Kylin 在滴滴 OLAP 引擎中的部署情况,Kylin 集群包含 2 台分布式构建节点、8 台查询节点,其中 2 台查询节点作为集群接口承接 REST 请求,REST 请求主要包含两类:构建作业状态查询和创建类操作,创建类操作如装载表、建模、创建立方体以及对等的删除操作等等。对于构建作业状态查询轮询请求两台节点,而对创建类操作则请求其中固定的一台节点,另一台作为 Standby 存在,这样设计的主要目的是避免集群接口的单点问题,同时解决因 Kylin 集群元数据同步机制导致的可能出现的创建类操作失败问题。
Kylin 作为固化分析场景引擎,主要负责对有聚合缓存需求的表进行查询加速。什么样的表会有这样的需求呢?
前者不难理解,后者则如引擎中的表,表数据规模较大,且被频繁执行某种聚合分析,在一段时间内达到一定的频次,引擎会识别并认为该表需要执行聚合缓存,进而触发调度将数据“复制”到 Kylin。这样,下次针对该表的聚合分析如果可被 Kylin 的聚合缓存覆盖,就会直接查询 Kylin 中的聚合数据“副本”而非原始的明细数据“副本”。
Apache Kylin 在场景引擎中的使用效果
目前,Kylin 集群维护了700+ 的立方体,每日运行2000+ 的构建作业,平均构建时长37 分钟,立方体存储总量30+TB(已去除HDFS 副本影响);对未使用缓存的查询进行统计,80% 的查询耗时小于500ms,90% 的查询耗时小于2.8 秒。需要说明的是,由于OLAP 引擎中“数据转移决策”模块会根据查询场景触发数据“复制”到Kylin 中来,在近期的统计中,立方体数量一度会达到1100+。
在业务方面,Kylin 间接服务了下游数易(面向全公司的报表类数据产品)、开放平台(面向全公司的查询入口)等多个重要数据产品,覆盖了快车、专车等十多个业务线的分析使用,间接用户3000+,Kylin 的引入为用户提供了稳定、可靠、高效的固化分析性能。
使用 Apache Kylin 遇到的挑战
滴滴使用 Kylin 的方式与传统方式有异,Kylin 在架构设计上与业务紧耦合,传统方式中业务分析人员基于 Kylin 建模、构建立方体(Cube),然后执行分析查询。但滴滴将 Kylin 作为固化分析场景下的引擎使用,提供针对表的聚合缓存服务,这样作为一个通用数据组件的 Kylin 就剥离了业务属性,且与用户相割裂,对外透明。
在最初的使用中,由于没有控制 OLAP 引擎的内部并发,来自调度的聚合缓存任务会在某些情况下高并发地执行 Kylin 的表加载、模型和立方体的创建,因为 Kylin Project 元数据的更新机制导致操作存在失败的可能。当前,我们通过在 OLAP 引擎内部使用队列在一定程度上缓解了问题的发生,此外,结合重试机制,基本可以保证操作的成功完成。最后我们也注意到,该问题在最新的 Kylin 版本中已经进行了修复。
另外,Kylin 默认地,在删除立方体时不会卸载 HBase 中的 Segment 表,而需定期执行脚本进行清理。这样,就导致引擎运行时及时卸载无效的立方体无法级联到 HBase,给 HBase 造成了较大的运维压力。因此我们也对源码进行了调整,在立方体删除时增加了 HBase Segment 表清理的功能,等等。
