现象: Java程序在Windows命令行编译运行打印中文时,直接在命令行下编译会报错:gbk编码的不可映射字符。Eclipse不存在该问题。
分析:显然是几种编码格式不兼容,但要搞清楚源文件的编码方式、编译生成的class文件编码方式并且确保两个阶段编码格式的兼容。
Windows下默认是ANSI编码(注意非ASCII),在中文操作系统中就是GBK编码(windows命令行中输入chcp,显示Active code page: 936,cp936即为gbk编码。),而javac默认也是采用操作系统的编码(可以通过notepad++看到class文件的编码格式为ANSI),若源文件为UTF-8,则两种格式不符就会报错。在eclipse/idea等IDE下不会出现这种情况,归功于强大的IDE已经帮我们省去了太多麻烦,同时也屏蔽了我们一窥内部洞天的机会。解决该问题将源文件编码方式和编译时的编码方式设为一致即可。
编程时文件的编码一般都为utf-8,这样与windows默认的gbk编码不符,若是文件中带中文,直接javac编译都不会通过,如果文件中不带中文字符但是想打印中文字符,则打印会乱码。
**解决:**明白以上,问题就很简单了。解决:
1.将源文件编码格式更改为ANSI,使源码文件格式与编译时格式保持一致;
2.若是命令行下编译,加上-encoding参数,即javac –encoding utf-8 xx.java,使编译格式和源码格式相同。
环境变量中加入JAVA_TOOL_OPTIONS,值设为-Dfile.encoding=UTF-8,则有文件的编译编码方式自动变为UTF-8.
增补:
下面总结一下Java相关的编码格式:
| 编码格式 |
说明 |
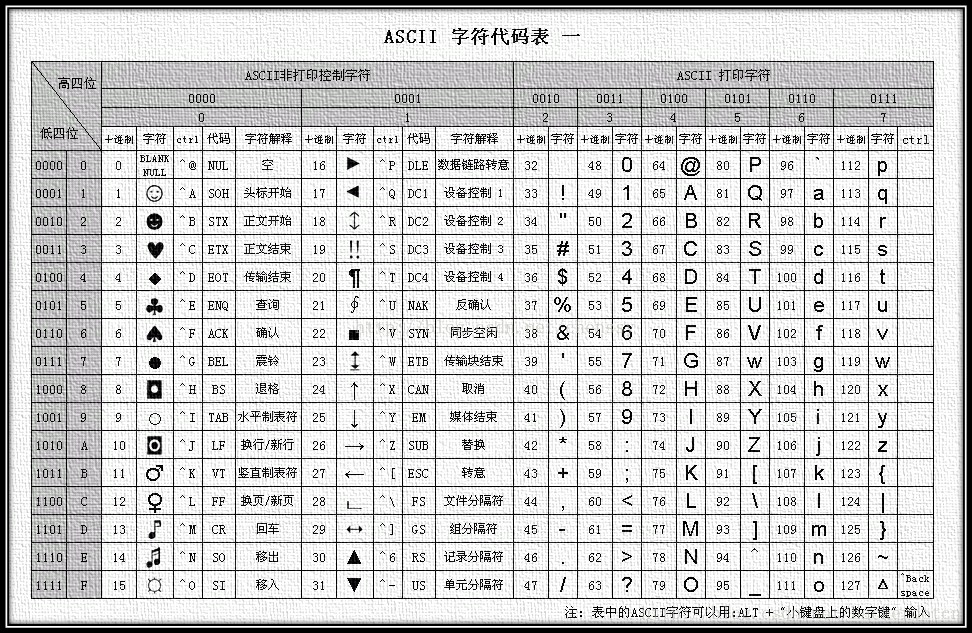
| ASCII |
共128个,用1个字节的低7位表示
0到31及127是控制字符,32到126是打印字符 |
| ISO8859-1 |
在ASCII上扩展,共256个,仍是单字节编码 |
| GB23121 |
汉字编码字符集,双字节编码 |
| GBK |
扩展GB2312,加入更多汉字,
变长编码,英文单字节表示兼容ASCII,中文双字节表示 |
| UTF-16 |
Unicode字符集,定长编码,双字节编码
Java以UTF-16作为内存存储格式
|
| UTF-8 |
变长编码,长度可以是1~6个字节 |
参考:
https://www.zhihu.com/question/20650946
附录:ASCII码表