Windows(窗口)
Windows是流计算的核心。Windows将流分成有限大小的“buckets”,我们可以在其上应用聚合计算(ProcessWindowFunction,ReduceFunction,AggregateFunction或FoldFunction)等。在Flink中编写一个窗口计算的基本结构如下:
Keyed Windows
stream
.keyBy(...)
.window(...) <- 必须制定: 窗口类型
[.trigger(...)] <- 可选: "trigger" (都有默认 触发器),决定窗口什么时候触发
[.evictor(...)] <- 可选: "evictor" (默认 没有剔出),剔出窗口中的元素
[.allowedLateness(...)] <- 可选: "lateness" (默认 0),不允许又迟到的数据
[.sideOutputLateData(...)] <- 可选: "output tag" 将迟到的数据输出到 指定流中
.reduce/aggregate/fold/apply() <- 必须指定: "function",实现对窗口数据的聚合计算
[.getSideOutput(...)] <- 可选: "output tag" 获取Sideout的数据,一般处理迟到数据
Non-Keyed Windows
stream
.windowAll(...) <- 必须制定: 窗口类型
[.trigger(...)] <- 可选: "trigger" (都有默认 触发器),决定窗口什么时候触发
[.evictor(...)] <- 可选: "evictor" (默认 没有剔出),剔出窗口中的元素
[.allowedLateness(...)] <- 可选: "lateness" (默认 0),不允许又迟到的数据
[.sideOutputLateData(...)] <- 可选: "output tag" 将迟到的数据输出到 指定流中
.reduce/aggregate/fold/apply() <- 必须指定: "function",实现对窗口数据的聚合计算
[.getSideOutput(...)] <- 可选: "output tag" 获取Sideout的数据,一般处理迟到数据
Window Lifecycle(生命周期)
In a nutshell, a window is created as soon as the first element that should belong to this window arrives, and the window is completely removed when the time (event or processing time) passes its end timestamp plus the user-specified allowed lateness (see Allowed Lateness). Flink guarantees removal only for time-based windows and not for other types, e.g. global windows (see Window Assigners).
in addition, each window will have a Trigger (see Triggers) and a function (ProcessWindowFunction, ReduceFunction,AggregateFunction or FoldFunction) (see Window Functions) attached to it. The function will contain the computation to be applied to the contents of the window, while the Trigger specifies the conditions under which the window is considered ready for the function to be applied.
Apart from the above, you can specify an Evictor (see Evictors) which will be able to remove elements from the window after the trigger fires and before and/or after the function is applied.
Window Assigners(窗口分配器)
The window assigner defines how elements are assigned to windows. This is done by specifying the WindowAssigner of your choice in the window(...) (for keyedstreams) or the windowAll() (for non-keyed streams) call.
A WindowAssigner is responsible for assigning each incoming element to one or more windows. Flink comes with pre-defined window assigners for the most common use cases, namely tumbling windows, sliding windows, session windows and global windows. You can also implement a custom window assigner by extending the WindowAssigner class. All built-in window assigners (except the global windows) assign elements to windows based on time, which can either be processing time or event time.
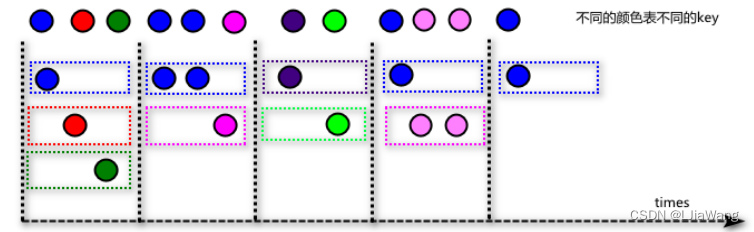
Tumbling Windows
滚动窗口长度固定,滑动间隔等于窗口长度,窗口元素之间没有交叠。
var env=StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("centos",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce((v1,v2)=>(v1._1,v1._2+v2._2))
.print()
env.execute("window")
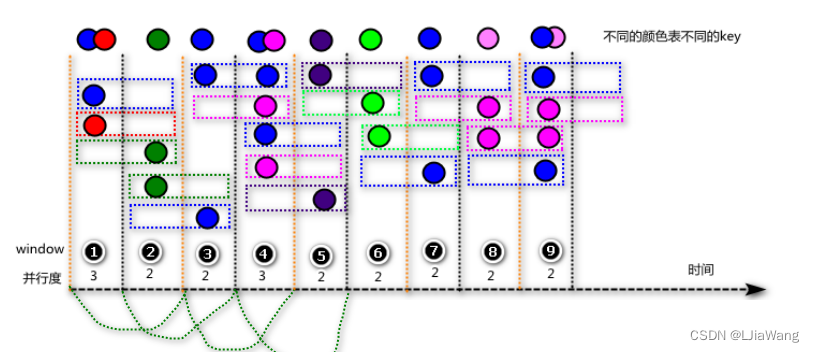
Sliding Windows
滑动窗口长度固定,窗口长度大于窗口滑动间隔,元素存在交叠。
var env=StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("centos",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(_._1)
.window(SlidingProcessingTimeWindows.of(Time.seconds(4),Time.seconds(2)))
.process(new ProcessWindowFunction[(String,Int),String,String,TimeWindow]{
override def process(key: String, context: Context,
elements: Iterable[(String, Int)],
out: Collector[String]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
val window = context.window
println(sdf.format(window.getStart)+"\t"+sdf.format(window.getEnd))
for(e <- elements){
print(e+"\t")
}
println()
}
})
env.execute("window")
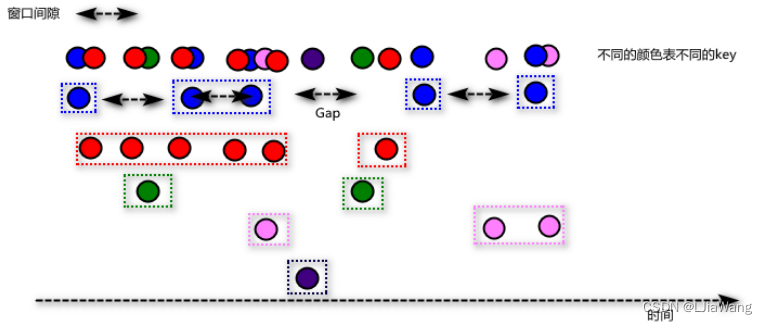
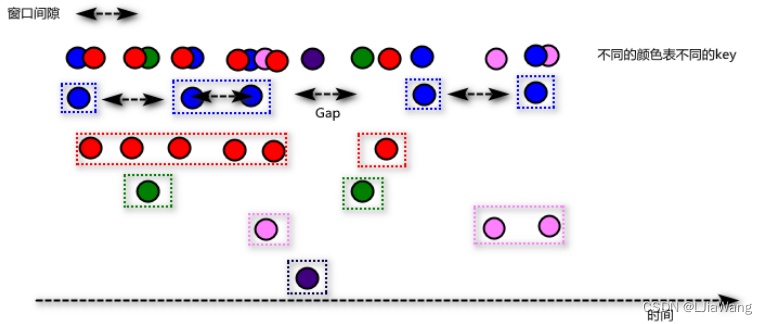
Session Windows(MergerWindow)
通过计算元素时间间隔,如果间隔小于session gap,则会合并到一个窗口中;如果大于时间间隔,当前窗口关闭,后续的元素属于新的窗口。与滚动窗口和滑动窗口不同的是会话窗口没有固定的窗口大小,底层本质上做的是窗口合并。
var env=StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("centos",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(_._1)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))
.apply(new WindowFunction[(String,Int),String,String,TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[String]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
println(sdf.format(window.getStart)+"\t"+sdf.format(window.getEnd))
for(e<- input){
print(e+"\t")
}
println()
}
})
env.execute("window")
Global Windows
全局窗口会将所有key相同的元素放到一个窗口中,默认该窗口永远都不会关闭(永远都不会触发),因为该窗口没有默认的窗口触发器Trigger,因此需要用户自定义Trigger。
var env=StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("centos",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(_._1)
.window(GlobalWindows.create())
.trigger(CountTrigger.of[GlobalWindow](3))
.apply(new WindowFunction[(String,Int),String,String,GlobalWindow]{
override def apply(key: String, window: GlobalWindow, input: Iterable[(String, Int)], out: Collector[String]): Unit = {
println("=======window========")
for(e<- input){
print(e+"\t")
}
println()
}
})
env.execute("window")
Window Functions
当系统认定窗口就绪之后会调用Window Functions对窗口实现聚合计算。常见的Window Functions有以下形式: ReduceFunction, AggregateFunction, FoldFunction 或者ProcessWindowFunction|WindowFunction(古董|旧版)。
ReduceFunction
class SumReduceFunction extends ReduceFunction[(String,Int)]{
override def reduce(v1: (String, Int), v2: (String, Int)): (String, Int) = {
(v1._1,v1._2+v2._2)
}
}
var env=StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("centos",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new SumReduceFunction)// .reduce((v1,v2)=>(v1._1,v1._2+v2._2))
.print()
env.execute("window")
AggregateFunction
class SumAggregateFunction extends AggregateFunction[(String,Int),(String,Int),(String,Int)]{
override def createAccumulator(): (String,Int) = {
("",0)
}
override def merge(a: (String,Int), b: (String,Int)): (String,Int) = {
(a._1,a._2+b._2)
}
override def add(value: (String, Int), accumulator: (String,Int)): (String,Int) = {
(value._1,accumulator._2+value._2)
}
override def getResult(accumulator: (String,Int)): (String, Int) = {
accumulator
}
}
var env=StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new SumAggregateFunction)
.print()
env.execute("window")
FoldFunction
class SumFoldFunction extends FoldFunction[(String,Int),(String,Long)]{
override def fold(accumulator: (String, Long), value: (String, Int)): (String, Long) = {
(value._1,accumulator._2+value._2)
}
}
var env=StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("centos",8877)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(1)))
//.fold(("",0L),new SumFoldFunction)
.fold(("",0L))((acc,v)=>(v._1,acc._2+v._2))
.print()
env.execute("window")
ProcessWindowFunction
var env=StreamExecutionEnvironment.getExecutionEnvironment
env.socketTextStream("centos",7788)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(_._1)
.window(SlidingProcessingTimeWindows.of(Time.seconds(4),Time.seconds(2)))
.process(new ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
override def process(key: String, context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String,Int)]): Unit = {
val results = elements.reduce((v1,v2)=>(v1._1,v1._2+v2._2))
out.collect(results)
}
}).print()
env.execute("window")
globalState() | windowState()
-
globalState(), which allows access to keyed state that is not scoped to a window
-
windowState(), which allows access to keyed state that is also scoped to the window
var env=StreamExecutionEnvironment.getExecutionEnvironment
val globalTag = new OutputTag[(String,Int)]("globalTag")
val countsStream = env.socketTextStream("centos", 7788)
.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(4), Time.seconds(2)))
.process(new ProcessWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
var wvds: ValueStateDescriptor[Int] = _
var gvds: ValueStateDescriptor[Int] = _
override def open(parameters: Configuration): Unit = {
wvds = new ValueStateDescriptor[Int]("window-value", createTypeInformation[Int])
gvds = new ValueStateDescriptor[Int]("global-value", createTypeInformation[Int])
}
override def process(key: String, context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val total = elements.map(_._2).sum
val ws = context.windowState.getState(wvds)
val gs=context.globalState.getState(gvds)
val historyWindowValue = ws.value()
val historyGlobalValue = gs.value()
out.collect((key, historyWindowValue + total))
context.output(globalTag, (key, historyGlobalValue + total))
ws.update(historyWindowValue + total)
gs.update(historyGlobalValue + total)
}
})
countsStream.print("窗口统计")
countsStream.getSideOutput(globalTag).print("全局输出")
env.execute("window")
ReduceFunction+ProcessWindowFunction
var env=StreamExecutionEnvironment.getExecutionEnvironment
val globalTag = new OutputTag[(String,Int)]("globalTag")
val countsStream = env.socketTextStream("centos", 7788)
.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(4), Time.seconds(2)))
.reduce(new SumReduceFunction,new ProcessWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
override def process(key: String, context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
val total = elements.map(_._2).sum
out.collect((key, total))
}
})
countsStream.print("窗口统计")
countsStream.getSideOutput(globalTag).print("全局输出")
env.execute("window")
var env=StreamExecutionEnvironment.getExecutionEnvironment
val countsStream = env.socketTextStream("centos", 7788)
.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(4), Time.seconds(2)))
.fold(("",0L),new SumFoldFunction,new ProcessWindowFunction[(String, Long), (String, Long), String, TimeWindow] {
override def process(key: String, context: Context,
elements: Iterable[(String, Long)],
out: Collector[(String, Long)]): Unit = {
val total = elements.map(_._2).sum
out.collect((key, total))
}
}).print()
env.execute("window")
WindowFunction(不常用)
遗产或古董,一般用ProcessWindowFunction替代。
In some places where a ProcessWindowFunction can be used you can also use a WindowFunction. This is an older version of ProcessWindowFunction that provides less contextual information and does not have some advances features, such as per-window keyed state. This interface will be deprecated at some point.
env.socketTextStream("centos",7788)
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(_._1) //不能按照position进行keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(1)))
.apply(new WindowFunction[(String,Int),(String,Int),String,TimeWindow] {
override def apply(key: String,
window: TimeWindow,
input: Iterable[(String, Int)],
out: Collector[(String, Int)]): Unit = {
out.collect((key,input.map(_._2).sum))
}
}).print()
env.execute("window")
Triggers(触发器)
A Trigger determines when a window (as formed by the window assigner) is ready to be processed by the window function. Each WindowAssigner comes with a default Trigger. If the default trigger does not fit your needs, you can specify a custom trigger using trigger(...).
| WindowAssigners |
触发器 |
| global window |
NeverTrigger |
| event-time window |
EventTimeTrigger |
| processing-time window |
ProcessingTimeTrigger |
The trigger interface has five methods that allow a Trigger to react to different events:
- The
onElement() method is called for each element that is added to a window.
- The
onEventTime() method is called when a registered event-time timer fires.
- The
onProcessingTime() method is called when a registered processing-time timer fires.
- The
onMerge() method is relevant for stateful triggers and merges the states of two triggers when their corresponding windows merge, e.g. when using session windows.
- Finally the
clear() method performs any action needed upon removal of the corresponding window.
DeltaTrigger
var env=StreamExecutionEnvironment.getExecutionEnvironment
val deltaTrigger = DeltaTrigger.of[(String,Double),GlobalWindow](2.0,new DeltaFunction[(String,Double)] {
override def getDelta(oldDataPoint: (String, Double), newDataPoint: (String, Double)): Double = {
newDataPoint._2-oldDataPoint._2
}
},createTypeInformation[(String,Double)].createSerializer(env.getConfig))
env.socketTextStream("centos",7788)
.map(_.split("\\s+"))
.map(ts=>(ts(0),ts(1).toDouble))
.keyBy(0)
.window(GlobalWindows.create())
.trigger(deltaTrigger)
.reduce((v1:(String,Double),v2:(String,Double))=>(v1._1,v1._2+v2._2))
.print()
env.execute("window")
evictor(剔出)
The evictor has the ability to remove elements from a window after the trigger fires and before and/or after the window function is applied. To do so, the Evictor interface has two methods:
public interface Evictor<T, W extends Window> extends Serializable {
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
}
ErrorEvitor
class ErrorEvictor(isBefore:Boolean) extends Evictor[String,TimeWindow] {
override def evictBefore(elements: lang.Iterable[TimestampedValue[String]], size: Int, window: TimeWindow, evictorContext: Evictor.EvictorContext): Unit = {
if(isBefore){
evictor(elements,size,window,evictorContext)
}
}
override def evictAfter(elements: lang.Iterable[TimestampedValue[String]], size: Int, window: TimeWindow, evictorContext: Evictor.EvictorContext): Unit = {
if(!isBefore){
evictor(elements,size,window,evictorContext)
}
}
private def evictor(elements: lang.Iterable[TimestampedValue[String]], size: Int, window: TimeWindow, evictorContext: Evictor.EvictorContext): Unit={
val iterator = elements.iterator()
while(iterator.hasNext){
val it = iterator.next()
if(it.getValue.contains("error")){//将 含有error数据剔出
iterator.remove()
}
}
}
}
var fsEnv=StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.socketTextStream("CentOS",7788)
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.evictor(new ErrorEvictor(true))
.apply(new AllWindowFunction[String,String,TimeWindow] {
override def apply(window: TimeWindow, input: Iterable[String], out: Collector[String]): Unit = {
for(e <- input){
out.collect(e)
}
print()
}
})
.print()
fsEnv.execute("window")
Event Time
Flink在做窗口计算的时候支持以下语义的window:Processing time、Event time、Ingestion time
Processing time:使用处理节点时间,计算窗口
Event time:使用事件产生时间,计算窗口- 精确
Ingestion time:数据进入到Flink的时间,一般是通过SourceFunction指定时间
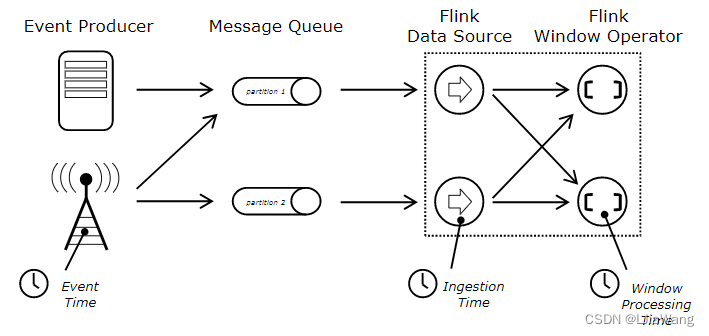
默认Flink使用的是ProcessingTime ,因此一般情况下如果用户需要使用 Event time/Ingestion time需要设置时间属性
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//window 操作
fsEnv.execute("event time")
一旦设置基于EventTime处理,用户必须声明水位线的计算策略,系统需要给每一个流计算出水位线时间T,只有窗口的end time T’ < = watermarker(T)的时候,窗口才会被触发。在Flink当中需要用户实现水位线计算的方式,系统并不提供实现。触发水位线的计算方式有两种:①一种是基于定时Interval(推荐)、②通过记录触发,每来一条记录系统会立即更新水位线。
定时
class AccessLogAssignerWithPeriodicWatermarks extends AssignerWithPeriodicWatermarks[AccessLog]{
private var maxSeeTime:Long=0L
private var maxOrderness:Long=2000L
override def getCurrentWatermark: Watermark = {
return new Watermark(maxSeeTime-maxOrderness)
}
override def extractTimestamp(element: AccessLog, previousElementTimestamp: Long): Long = {
maxSeeTime=Math.max(maxSeeTime,element.timestamp)
element.timestamp
}
}
基于记录
class AccessLogAssignerWithPunctuatedWatermarks extends AssignerWithPunctuatedWatermarks[AccessLog]{
private var maxSeeTime:Long=0L
private var maxOrderness:Long=2000L
override def checkAndGetNextWatermark(lastElement: AccessLog, extractedTimestamp: Long): Watermark = {
new Watermark(maxSeeTime-maxOrderness)
}
override def extractTimestamp(element: AccessLog, previousElementTimestamp: Long): Long = {
maxSeeTime=Math.max(maxSeeTime,element.timestamp)
element.timestamp
}
}
Watermarker
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
fsEnv.getConfig.setAutoWatermarkInterval(1000)//设置水位线定期计算频率 1s/每次
fsEnv.setParallelism(1)
//模块信息 时间
fsEnv.socketTextStream("CentOS",8888)
.map(line=> line.split("\\s+"))
.map(ts=>AccessLog(ts(0),ts(1).toLong))
.assignTimestampsAndWatermarks(new AccessLogAssignerWithPeriodicWatermarks)
.keyBy(accessLog=>accessLog.channel)
.window(TumblingEventTimeWindows.of(Time.seconds(4)))
.process(new ProcessWindowFunction[AccessLog,String,String,TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[AccessLog], out: Collector[String]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
val window = context.window
val currentWatermark = context.currentWatermark
println("window:"+sdf.format(window.getStart)+"\t"+sdf.format(window.getEnd)+" \t watermarker:"+sdf.format(currentWatermark))
for(e<-elements){
val AccessLog(channel:String,timestamp:Long)=e
out.collect(channel+"\t"+sdf.format(timestamp))
}
}
})
.print()
迟到数据处理
Flink支持对迟到数据处理,如果watermaker - window end < allow late time 记录可以参与窗口计算,否则Flink将too late数据丢弃。
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
fsEnv.getConfig.setAutoWatermarkInterval(1000)//设置水位线定期计算频率 1s/每次
fsEnv.setParallelism(1)
//模块信息 时间
fsEnv.socketTextStream("CentOS",8888)
.map(line=> line.split("\\s+"))
.map(ts=>AccessLog(ts(0),ts(1).toLong))
.assignTimestampsAndWatermarks(new AccessLogAssignerWithPeriodicWatermarks)
.keyBy(accessLog=>accessLog.channel)
.window(TumblingEventTimeWindows.of(Time.seconds(4)))
.allowedLateness(Time.seconds(2))
.process(new ProcessWindowFunction[AccessLog,String,String,TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[AccessLog], out: Collector[String]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
val window = context.window
val currentWatermark = context.currentWatermark
println("window:"+sdf.format(window.getStart)+"\t"+sdf.format(window.getEnd)+" \t watermarker:"+sdf.format(currentWatermark))
for(e<-elements){
val AccessLog(channel:String,timestamp:Long)=e
out.collect(channel+"\t"+sdf.format(timestamp))
}
}
})
.print()
fsEnv.execute("event time")
Flink默认对too late数据采取的是丢弃,如果用户想拿到过期的数据,可以使用sideout方式
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
fsEnv.getConfig.setAutoWatermarkInterval(1000)//设置水位线定期计算频率 1s/每次
fsEnv.setParallelism(1)
val lateTag = new OutputTag[AccessLog]("latetag")
//模块信息 时间
val keyedWindowStream=fsEnv.socketTextStream("CentOS",8888)
.map(line=> line.split("\\s+"))
.map(ts=>AccessLog(ts(0),ts(1).toLong))
.assignTimestampsAndWatermarks(new AccessLogAssignerWithPeriodicWatermarks)
.keyBy(accessLog=>accessLog.channel)
.window(TumblingEventTimeWindows.of(Time.seconds(4)))
.allowedLateness(Time.seconds(2))
.sideOutputLateData(lateTag)
.process(new ProcessWindowFunction[AccessLog,String,String,TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[AccessLog], out: Collector[String]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
val window = context.window
val currentWatermark = context.currentWatermark
println("window:"+sdf.format(window.getStart)+"\t"+sdf.format(window.getEnd)+" \t watermarker:"+sdf.format(currentWatermark))
for(e<-elements){
val AccessLog(channel:String,timestamp:Long)=e
out.collect(channel+"\t"+sdf.format(timestamp))
}
}
})
keyedWindowStream.print("正常:")
keyedWindowStream.getSideOutput(lateTag).print("too late:")
fsEnv.execute("event time")
当流中存在多个水位线,系统在计算的时候取最低。
Joining
Window Join
基本语法
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
Tumbling Window Join
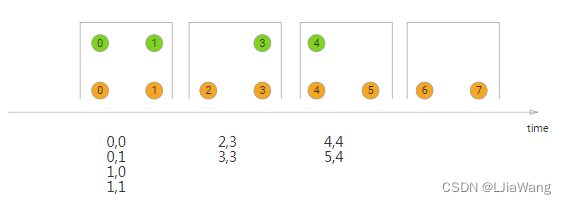
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
fsEnv.getConfig.setAutoWatermarkInterval(1000)
fsEnv.setParallelism(1)
//001 zhangsan 1571627570000
val userStream = fsEnv.socketTextStream("CentOS",7788)
.map(line=>line.split("\\s+"))
.map(ts=>User(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new UserAssignerWithPeriodicWatermarks)
.setParallelism(1)
//001 apple 4.5 1571627570000L
val orderStream = fsEnv.socketTextStream("CentOS",8899)
.map(line=>line.split("\\s+"))
.map(ts=>OrderItem(ts(0),ts(1),ts(2).toDouble,ts(3).toLong))
.assignTimestampsAndWatermarks(new OrderItemWithPeriodicWatermarks)
.setParallelism(1)
userStream.join(orderStream)
.where(user=>user.id)
.equalTo(orderItem=> orderItem.uid)
.window(TumblingEventTimeWindows.of(Time.seconds(4)))
.apply((u,o)=>{
(u.id,u.name,o.name,o.price,o.ts)
})
.print()
fsEnv.execute("FlinkStreamSlidingWindowJoin")
Sliding Window Join
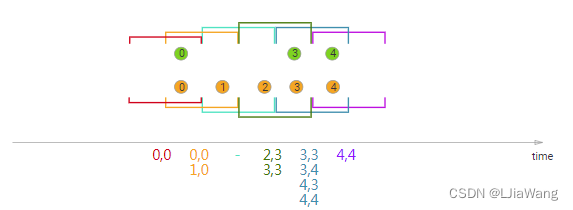
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
fsEnv.getConfig.setAutoWatermarkInterval(1000)
fsEnv.setParallelism(1)
//001 zhangsan 1571627570000
val userStream = fsEnv.socketTextStream("CentOS",7788)
.map(line=>line.split("\\s+"))
.map(ts=>User(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new UserAssignerWithPeriodicWatermarks)
.setParallelism(1)
//001 apple 4.5 1571627570000L
val orderStream = fsEnv.socketTextStream("CentOS",8899)
.map(line=>line.split("\\s+"))
.map(ts=>OrderItem(ts(0),ts(1),ts(2).toDouble,ts(3).toLong))
.assignTimestampsAndWatermarks(new OrderItemWithPeriodicWatermarks)
.setParallelism(1)
userStream.join(orderStream)
.where(user=>user.id)
.equalTo(orderItem=> orderItem.uid)
.window(SlidingEventTimeWindows.of(Time.seconds(4),Time.seconds(2)))
.apply((u,o)=>{
(u.id,u.name,o.name,o.price,o.ts)
})
.print()
fsEnv.execute("FlinkStreamTumblingWindowJoin")
Session Window Join
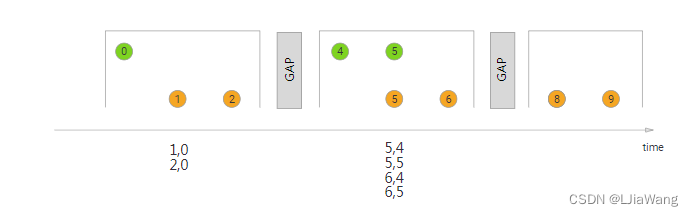
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
fsEnv.getConfig.setAutoWatermarkInterval(1000)
fsEnv.setParallelism(1)
//001 zhangsan 1571627570000
val userStream = fsEnv.socketTextStream("CentOS",7788)
.map(line=>line.split("\\s+"))
.map(ts=>User(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new UserAssignerWithPeriodicWatermarks)
.setParallelism(1)
//001 apple 4.5 1571627570000L
val orderStream = fsEnv.socketTextStream("CentOS",8899)
.map(line=>line.split("\\s+"))
.map(ts=>OrderItem(ts(0),ts(1),ts(2).toDouble,ts(3).toLong))
.assignTimestampsAndWatermarks(new OrderItemWithPeriodicWatermarks)
.setParallelism(1)
userStream.join(orderStream)
.where(user=>user.id)
.equalTo(orderItem=> orderItem.uid)
.window(EventTimeSessionWindows.withGap(Time.seconds(5)))
.apply((u,o)=>{
(u.id,u.name,o.name,o.price,o.ts)
})
.print()
fsEnv.execute("FlinkStreamSessionWindowJoin")
Interval Join
The interval join joins elements of two streams (we’ll call them A & B for now) with a common key and where elements of stream B have timestamps that lie in a relative time interval to timestamps of elements in stream A.
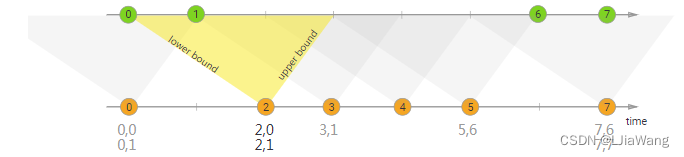
This can also be expressed more formally as b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] ora.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
val fsEnv = StreamExecutionEnvironment.getExecutionEnvironment
fsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
fsEnv.getConfig.setAutoWatermarkInterval(1000)
fsEnv.setParallelism(1)
//001 zhangsan 1571627570000
val userStream = fsEnv.socketTextStream("CentOS",7788)
.map(line=>line.split("\\s+"))
.map(ts=>User(ts(0),ts(1),ts(2).toLong))
.assignTimestampsAndWatermarks(new UserAssignerWithPeriodicWatermarks)
.setParallelism(1)
.keyBy(_.id)
//001 apple 4.5 1571627570000L
val orderStream = fsEnv.socketTextStream("CentOS",8899)
.map(line=>line.split("\\s+"))
.map(ts=>OrderItem(ts(0),ts(1),ts(2).toDouble,ts(3).toLong))
.assignTimestampsAndWatermarks(new OrderItemWithPeriodicWatermarks)
.setParallelism(1)
.keyBy(_.uid)
userStream.intervalJoin(orderStream)
.between(Time.seconds(-1),Time.seconds(1))
.process(new ProcessJoinFunction[User,OrderItem,String]{
override def processElement(left: User, right: OrderItem, ctx: ProcessJoinFunction[User, OrderItem, String]#Context, out: Collector[String]): Unit = {
println(left+" \t"+right)
out.collect(left.id+" "+left.name+" "+right.name+" "+ right.price+" "+right.ts)
}
})
.print()
fsEnv.execute("FlinkStreamSessionWindowJoin")
Flink HA
The JobManager coordinates every Flink deployment. It is responsible for both scheduling and resource management.
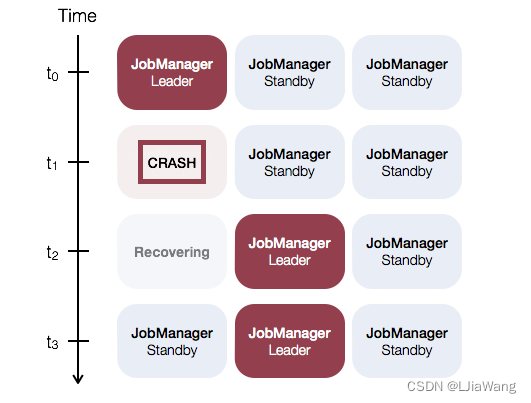
By default, there is a single JobManager instance per Flink cluster. This creates a single point of failure (SPOF): if the JobManager crashes, no new programs can be submitted and running programs fail.
With JobManager High Availability, you can recover from JobManager failures and thereby eliminate the SPOF. You can configure high availability for both standalone and YARN clusters.
Standalone Cluster High Availability
The general idea of JobManager high availability for standalone clusters is that there is a single leading JobManager at any time and multiple standby JobManagers to take over leadership in case the leader fails. This guarantees that there is no single point of failureand programs can make progress as soon as a standby JobManager has taken leadership. There is no explicit distinction between standby and master JobManager instances. Each JobManager can take the role of master or standby.
搭建过程
先决条件(略)
- 安装JDK
- 安装HADOOP HDFS-HA
- 安装Zookeeper
Flink环境构建
[root@CentOSX ~]# vi .bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CLASSPATH
[root@CentOSX ~]# source .bashrc
[root@CentOSX ~]# echo $HADOOP_CLASSPATH
/usr/hadoop-2.9.2/etc/hadoop:/usr/hadoop-2.9.2/share/hadoop/common/lib/*:/usr/hadoop-2.9.2/share/hadoop/common/*:/usr/hadoop-2.9.2/share/hadoop/hdfs:/usr/hadoop-2.9.2/share/hadoop/hdfs/lib/*:/usr/hadoop-2.9.2/share/hadoop/hdfs/*:/usr/hadoop-2.9.2/share/hadoop/yarn/lib/*:/usr/hadoop-2.9.2/share/hadoop/yarn/*:/usr/hadoop-2.9.2/share/hadoop/mapreduce/lib/*:/usr/hadoop-2.9.2/share/hadoop/mapreduce/*:/usr/hadoop-2.9.2/contrib/capacity-scheduler/*.jar
[root@CentOSX ~]# tar -zxf flink-1.8.1-bin-scala_2.11.tgz -C /usr/
[root@CentOSA ~]# cd /usr/flink-1.8.1
[root@CentOSA flink-1.8.1]# vi conf/flink-conf.yaml
#==============================================================================
# Common
#==============================================================================
taskmanager.numberOfTaskSlots: 4
parallelism.default: 3
#==============================================================================
# High Availability
#==============================================================================
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: CentOSA:2181,CentOSB:2181,CentOSC:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /default_ns
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
state.backend: rocksdb
state.checkpoints.dir: hdfs:///flink-checkpoints
state.savepoints.dir: hdfs:///flink-savepoints
state.backend.incremental: true
[root@CentOSX flink-1.8.1]# vi conf/masters
CentOSA:8081
CentOSB:8081
CentOSC:8081
[root@CentOSA flink-1.8.1]# vi conf/slaves
CentOSA
CentOSB
CentOSC
启动Flink集群
[root@CentOSA flink-1.8.1]# ./bin/start-cluster.sh
Starting HA cluster with 3 masters.
Starting standalonesession daemon on host CentOSA.
Starting standalonesession daemon on host CentOSB.
Starting standalonesession daemon on host CentOSC.
Starting taskexecutor daemon on host CentOSA.
Starting taskexecutor daemon on host CentOSB.
Starting taskexecutor daemon on host CentOSC.
等集群启动完成后,查看JobManager任务的日志,在lead主机中可以看到:
http://xxx:8081 was granted leadership with leaderSessionID=f5338c3f-c3e5-4600-a07c-566e38bc0ff4
测试HA
登陆获取leadership的节点,然后执行以下指令
[root@CentOSB flink-1.8.1]# ./bin/jobmanager.sh stop
查看其它节点,按照上诉的测试方式,可以查找leadership日志输出的节点,该节点就是master节点。