推荐系统,一般是用于电商、广告、内容、信息流等推荐平台,以挖掘数据的最大价值。可以提升用户粘性和转化率。而本文提及到的基于内容的协同过滤算法就是一个经典的算法。
基本思想
首先,什么是协同呢?协同在这里指的就是,用集体的智慧来为个体过滤出他需要的信息。
基于物品的协同过滤算法,就是以物品为连接点,给用户推荐那些和他们之前喜欢的物品相似的物品。 比如,该算法会因为你购买过《Java从入门到精通》而给你推荐《Java并发编程实战》。不过,基于物品的协同过滤算法并不利用物品的内容属性计算物品之间的相似度,二是通过分析用户的行为数据计算物品之间的相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。
所以呢,这个算法思想的强大之处就在于,不用考虑目标物品之间的相互关系或者内在联系。只用考虑用户和物品之间的行为数据即可。
计算过程
相似度计算:
简单的计算公式如下
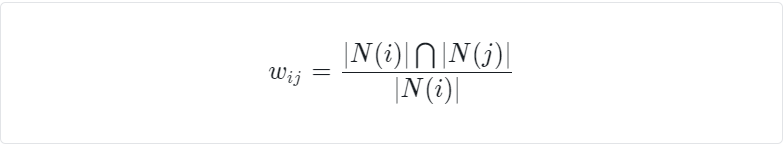
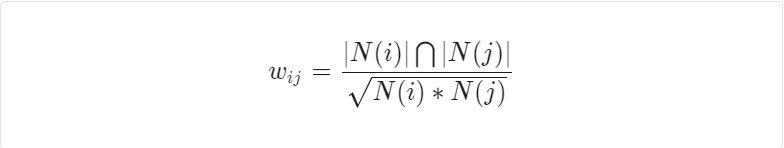
这里,分母|N(i)|是喜欢物品i的用户数,而分子|N(i)∩N(j)|是同时喜欢物品i和物品j的用户数,所以该公式也可以理解为喜欢物品i的用户中有多少比例也喜欢物品j。
在 1 式中,如果出现某种商品火爆,可能会导致计算错误,2式则在一定程度上进行了惩罚。
构建推荐矩阵:
假如说,有 a,b,c,d,e 五个商品,其购买数据如下。

那么按公式计算,a,b 的相似度为
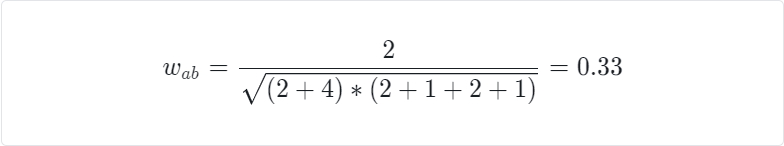
以同样的方式,就可以得到相似度矩阵

下面就是,根据需要被预测的用户已有的记录 ,与相似度对应的数值相乘求和,再排序就能得到对应需要推荐的函数了。 比如下面公式就是计算 用户 u 对 物品 j 的兴趣。
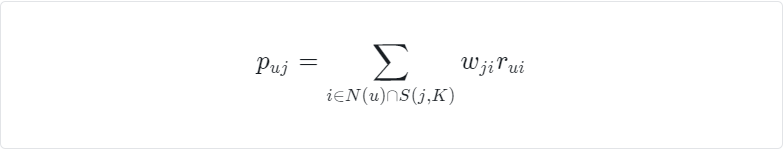


则:
p(u,b) = 0.331 +0.313 = 1.26
p(u,c) = 01 + 0.223 = 0.66
所以最终的推荐列表为【b,c,e】
优缺点:
Item-based算法原理是给用户推荐那些和他之前喜欢的物品类似的物品,在推荐方面更加个性化,反映了用户自己的兴趣传承。在用户有新行为时,一定会导致推荐结果的实时变化。
适用范围:长尾物品丰富,用户个性化需求强烈的领域。
优点:可以利用用户的历史行为给用户做推荐解释,可以令用户比较信服。比较适用在物品较少、物品更新速度不会很快、用户的兴趣比较固定和持久的情况下。
缺点:无法避免用户冷启动,需要等待用户接触物品后才给他推荐相关物品,没有办法在不离线更新物品相似度表的情况下将新物品推荐给用户。